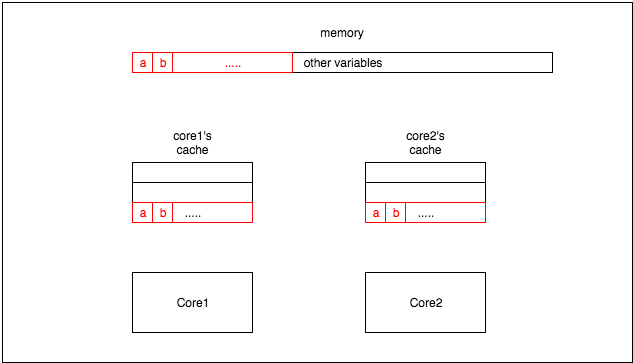
package test
import (
"runtime"
"sync"
"testing"
)
type foo struct {
x, y, z int64
}
type foo64Start struct {
_ [64]byte
x, y, z int64
}
type foo64StartEnd struct {
_ [64]byte
x, y, z int64
_ [64]byte
}
type foo128Start struct {
_ [128]byte
x, y, z int64
}
type foo128StartEnd struct {
_ [128]byte
x, y, z int64
_ [128]byte
}
type foo64StartEndAligned struct {
_ [64]byte
x, y, z int64
_ [64 - 24]byte
}
type foo128StartEndAligned struct {
_ [128]byte
x, y, z int64
_ [128 - 24]byte
}
const iter = (1 << 16)
func BenchmarkFalseSharing(b *testing.B) {
var wg sync.WaitGroup
b.Run("NoPad", func(b *testing.B) {
arr := make([]foo, runtime.GOMAXPROCS(0))
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arr {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[i].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
b.Run("Pad64Start", func(b *testing.B) {
arr := make([]foo64Start, runtime.GOMAXPROCS(0))
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arr {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[i].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
b.Run("Pad64StartEnd", func(b *testing.B) {
arr := make([]foo64StartEnd, runtime.GOMAXPROCS(0))
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arr {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[i].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
b.Run("Pad128Start", func(b *testing.B) {
arr := make([]foo128Start, runtime.GOMAXPROCS(0))
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arr {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[i].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
b.Run("Pad128StartEnd", func(b *testing.B) {
arr := make([]foo128StartEnd, runtime.GOMAXPROCS(0))
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arr {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[i].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
b.Run("Pad64StartEndAligned", func(b *testing.B) {
arr := make([]foo64StartEndAligned, runtime.GOMAXPROCS(0))
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arr {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[i].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
b.Run("Pad128StartEndAligned", func(b *testing.B) {
arr := make([]foo128StartEndAligned, runtime.GOMAXPROCS(0))
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arr {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[i].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
}
func BenchmarkTrueSharing(b *testing.B) {
var wg sync.WaitGroup
b.Run("<64", func(b *testing.B) {
arr := make([]foo, runtime.GOMAXPROCS(0)*iter)
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arrChan {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[(i*iter)+j].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
b.Run(">64", func(b *testing.B) {
arr := make([]foo64Start, runtime.GOMAXPROCS(0)*iter)
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arrChan {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[(i*iter)+j].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
b.Run(">128", func(b *testing.B) {
arr := make([]foo128Start, runtime.GOMAXPROCS(0)*iter)
arrChan := make([]chan struct{}, runtime.GOMAXPROCS(0))
for i := range arrChan {
arrChan[i] = make(chan struct{})
}
for i := range arrChan {
go func(i int) {
for range arrChan[i] {
for j := 0; j < iter; j++ {
arr[(i*iter)+j].x++
}
wg.Done()
}
}(i)
}
b.ResetTimer()
for i := 0; i < b.N; i++ {
wg.Add(runtime.GOMAXPROCS(0))
for j := range arrChan {
arrChan[j] <- struct{}{}
}
wg.Wait()
}
b.StopTimer()
for i := range arrChan {
close(arrChan[i])
}
})
}