现在谈起大数据几乎等价于谈论Hadoop及其它的生态圈产品。但是现在一个下一代的计算框架已经长大,而且声名显赫。那就是Spark。你或许已经听说过它以及它的诸多好处。
自从发布之日起,Hadoop就被认为是Google大数据工具的等价实现。它帮助很多公司处理先前不可想象的大数据。围绕着它的两个主要部件(HDFS,分布式一致性的文件系统,和MapReduce, 分布式的计算框架), 一堆相关的工具涌现, 补充并提高它的功能。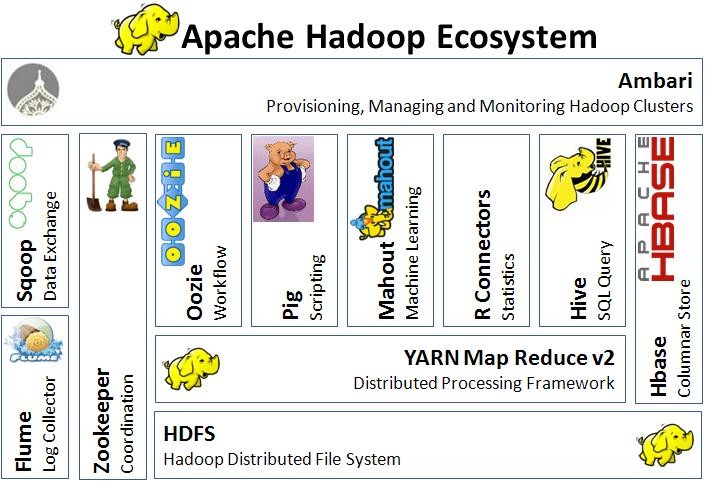
现在我们已经有了注入系统(Kafka, Flume, …), SQL类的查询系统(Hive, Impala, Shark, ..),非SQL类的查询系统(Cassandra, HBase, …), 分析系统框架(MapReduce, Pig, R-Hadoop, …) , 图数据模型(Giraph), 机器学习(Mahout, H20), 工作流框架(Oozie)等等.
然而,Hadoop也有它的局限。 Hadoop设计的目的是处理几个小时或者几天内的批处理数据。尽管做了种种努力使它变得更快, 也有一些工具如上面提到的工具科技将它的延迟降低到秒级,但是它仍然不能满足应用对时间延迟的需求,这些系统要求返回时间小于1秒。
另一个问题就是尽管它的生态圈很丰富,但是过于杂乱。 它们使用了各种各样的编程语言和不同的数据抽象,这对维护来说就是一场噩梦。大部分产品级系统都不得不维护四到五个代码库。
Spark试图解决这些问题而且相当成功。
Hadoop一个主要问题就是基于磁盘文件系统,需要序列化和反序列化大量的信息,显然很慢。Spark则尽可能的在内存中处理,光这个就使它比Haddop快100倍(所有的数据都在内存中时),或者快10倍(当需要内存和磁盘需要数据交换时)。 它特别适合迭代算法。
Spark作为一个单一系统包含了五个大数据处理的组件: 批处理框架, 近实时的流处理, 机器学习, SQL查询和图计算. 它极大的简化了开发和维护工作, 而且单一的平台也确保了用户在处理不同的分析需求时可以使用一致的产品。
除了上面谈到的几点,Spark还提供了Scala API,允许数据科学家使用函数式编程来处理数据。函数式编程更自然的适合数据处理, 也更适合并发和分布式算法。但是如果你不喜欢Scala,或者不了解它, 你也可以使用Java, Python甚至R.
Spark最伟大之处就是向后兼容Hadoop. 你可以把它加入到你的工具集,不需扔掉先前的工作。Spark可以使用存储在HDFS中的任何文件或者其它的Hadoop支持的存储系统。 也支持文本文件, SequenceFiles 和其它的Hadoop InputFormat文件.
