「A picture is worth a thousand words. A diagram is worth ten thousand lines of code.」
一图胜千言。一张图胜万行代码。
第 13 章解决了一个问题:AI 写代码容易,读代码难。Understand-Anything 用知识图谱让 AI 理解现有代码。
反过来——代码写完了,作为人类你怎么理解它?毕竟,线上出了故障你还等着你背锅呢。
我前一段看到一句箴言:"𝐲𝐨𝐮 𝐜𝐚𝐧 𝐨𝐮𝐭𝐬𝐨𝐮𝐫𝐜𝐞 𝐲𝐨𝐮𝐫 𝐭𝐡𝐢𝐧𝐤𝐢𝐧𝐠, 𝐛𝐮𝐭 𝐲𝐨𝐮 𝐜𝐚𝐧𝐧𝐨𝐭 𝐨𝐮𝐭𝐬𝐨𝐮𝐫𝐜𝐞 𝐲𝐨𝐮𝐫 𝐮𝐧𝐝𝐞𝐫𝐬𝐭𝐚𝐧𝐝𝐢𝐧𝐠", 翻译过来就是"你可以外包你的思考(给AI),但是你不能外包你的理解"。 这句话被 Andrej Karpathy 多次引用,以至于大家认为是他说的,其实是kache说的:

这句话非常有哲理。Dex Horthy 在 2025 AI Engineer 大会上独立提出了:"Don't outsource the thinking" / "AI cannot replace thinking, it can only amplify the thinking you have done.",但是今年你看, AI已经外包了我们的思考,你只需说出的你需求,智能体就能帮助你生生成你要的程序,但是 AI 没有办法帮我们理解啊。
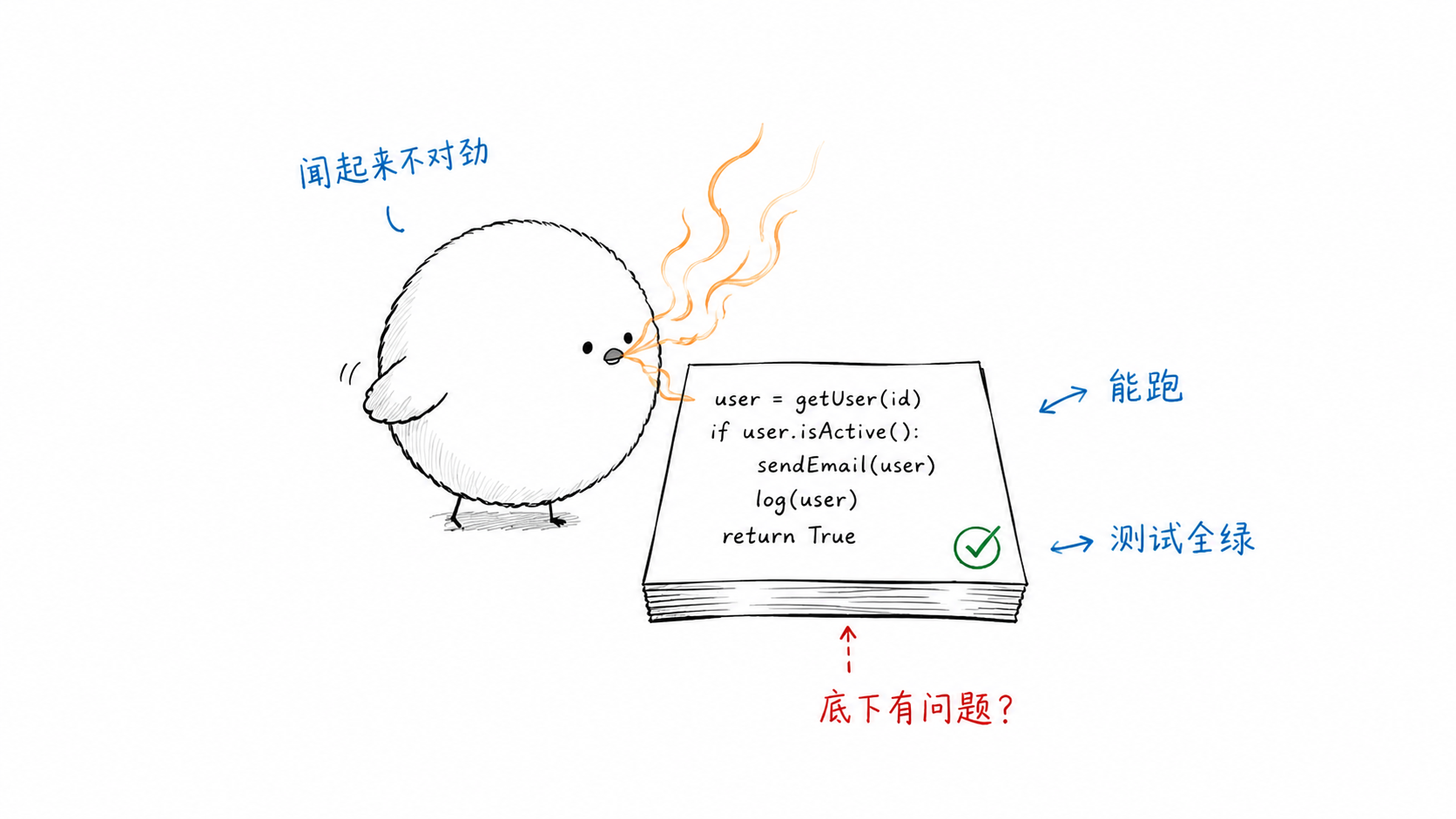
我最近就遇到了这样的困惑:我通过goal workflow很快的实现了一个大模型训推任务智能诊断系统,全是AI帮我生成的,但是在联调的前一个星期,我心虚了。
因为我知道,联调和上线的时候,必然有一些问题,比如当时的设计有些模糊的地方,设计上有gap, 实现上也难免有bug。如果我对生成的代码不熟悉,联调的时候出故障我都不知道啥原因咋修复,可能当时还得重新捋代码才能慢慢找根因,太影响联调的同学了。未来上线以后出现问题,想快速修复就更不可能了。
所以我专门花了两天时间,建了几个卡片,就为了学习代码理解代码。
那我是通过什么方式去理解AI生成的代码的呢?
答案藏在一个用了二十多年的老工具里:UML。区别只有一点:以前的 UML 是人画给团队的,现在是 AI 画给你的。十四种图,从类结构到部署拓扑,从序列交互到状态变迁。AI 生成代码,AI 再画图解释代码——你读图就够了。
为此,我专门创建了一个Skill,用来生成UML的十四种代码和架构图、流程图以及泳道图。此skill的介绍:https://goal.rpcx.io/index_cn.html#step-diagram, 也集成到了goal workflow套件中了。
本章分两部分:第一部分过一遍 UML 十四种正式图形,外加三种 UML 规范没有但实际很常用的图。第二部分介绍 insight-diagram——一个在 goal.rpcx.io 上发布的 Skill,给任意代码库自动生成全套 UML 图、架构图和流程图。
阅读全文