CQRS全称为Command Query Responsibility Segregation。 CQRS并不是一个完整的架构,而是一个小的模式。这个模式首先由Greg Young 和 Udi Dahan提出,Martin Flower有一篇文章专门介绍这个模式,微软也有一个专门教程介绍CQRS。
CQRS描述起来很简单,就是命令和查询职责分离。
传统上,我们会使用统一的模型进行数据的增删改查,并提供统一的服务,这是我们最常用的一种方式,很多框架也提供了辅助功能帮我们自动产生CRUD的代码。
但是,这也带来一些问题:
- 对数据的读取往往比写入频繁得多
- 在读取数据时,我们通常会获取大量数据,或是一个数据列表。与之相比,对数据的写入通常只影响一个单一的聚合。
- 从用户的角度来看,数据的读取应当表现出比写入更高的性能。对于用户来说,在进行数据变更时产生一些拖慢的现象更易于接受。
Vladimir Khorikov定义了三种类型的CQRS,并且与不使用CQRS(No CQRS)的架构方式进行了对比:
- 在No CQRS架构中,使用同一个领域模型进行命令与查询的处理。这种方式不会造成代码或复杂度的提高,但会使对读取操作的优化变得非常困难,甚至完全不可能。
- 在分离式类结构中,使用领域类处理命令,并用数据传输对象(DTO)负责返回读取的数据,这种方式会带来某种程度的重复。Khorikov相信,到了这个阶段的CQRS应用对于大多数企业应用来说已经足够了,它在复杂性与性能之间实现了良好的平衡。
- 在分离式模型中,数据的读取与写入将使用不同的API与模型对应实现。这种方式不仅能够优化查询,并且能够利用缓存,对于读取负载很高的应用来说是一种不错的方案。
- 对查询使用分离的存储结构以进行优化,能够应对更大规模的读取操作。对于数据的写入与查询将各种使用不同类型的存储结构,比如分别使用一个关系型数据库和一个NoSQL类型的数据库。通常会在后台运行读存储结构的同步,因此数据的读取将实现最终一致性。这种模式的可伸缩性最高,但同时也意味着最高的复杂性。
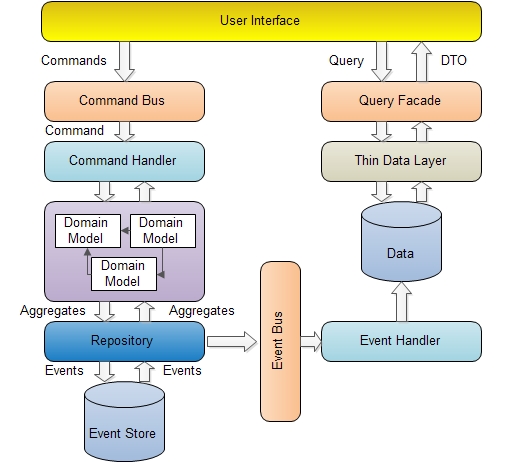
CQRS经常和Event Sourcing一起提到,尽管两者没有依赖关系,它们只是经常互相补充。
一个对象从创建开始到消亡会经历很多事件,以前我们是在每次对象参与完一个业务动作后把对象的最新状态持久化保存到数据库中,也就是说我们的数据库中的数据是反映了对象的当前最新的状态。而事件溯源则相反,不是保存对象的最新状态,而是保存这个对象所经历的每个事件,所有的由对象产生的事件会按照时间先后顺序有序的存放在数据库中。可以看出,事件溯源的这种做法是更符合事实观的,因为它完整的描述了对象的整个生命周期过程中所经历的所有事件。
参考文章
- http://codebetter.com/gregyoung/2010/02/16/cqrs-task-based-uis-event-sourcing-agh/
- http://martinfowler.com/bliki/CQRS.html
- CQRS Journey
- Event Sourcing Pattern
- http://en.wikipedia.org/wiki/Command%E2%80%93query_separation
- Introduction to CQRS
- http://www.infoq.com/cn/news/2015/05/cqrs-advantages
- http://www.cnblogs.com/netfocus/p/4150084.html
- http://jensrantil.github.io/cqrsevent-sourcing-messaging-patterns.html
