这两年来我一直在做网络故障监控的工作,经常使用的一个手段就是发送一些探测包进行网络的探测,根据丢包和时延,再结合网络拓扑等手段分析现网网络故障。因为要监控的是度厂全部网络的质量状况,并且需要很高的精度去覆盖网络设备、板卡、端口以及他们之间映射等所有的路径,所以需要尽量发送高频的探测包去快准狠的感知到故障并发现。
同时,和业务网络程序的不一样,业务程序一般是业务层代码,TCP的重传的机制,或者业务换个五元组重连一次,就会绕过网络中的故障,而网络监控也需要把这个链路中这些故障找出来,经常我会使用UDP或者TCP的握手包进行网络的探测,再不济使用ICMP协议进行网络的探测。
经常有人会说,现在都两个服务器间都能实现几十上百万的requests/second了,比如我们访问Redis节点,但是『达到』和『产品化可用』是两回事,也很少有人将redis节点在几十万的qps之下常态运行,我们还得考虑丢包的情况和时延的情况。
但是不管怎样,benchmark的工作我们还是要做的,这是我们评价我们的程序的一个基准,实际运行中我们可能使用这个基本的1/10的能力,以便保证程序的稳定性和CPU、内存、时延要求等。我写本文的目的,也是在测试机上进行这样的benchmark,检查网络方案的能力。
- 首先使用一个普通的UDP程序进行百万pps (packets per second)的测试
- 介绍XDP技术,实现一个简单的网络统计程序
- 使用XDP技术实现echo能力,替换原来的UDP server, 将CPU使用率几乎降为0
背景
普通的网络测试程序代码在network_benchmark,除了UDP的探测外,我还实现了一个TCP程序的探测。
client和server连接到同一台交换机上,尽量减少网络的干扰。
1 | 客户端机器: xxx.xxx.xxx.176 |
客户机和服务器都设置了网卡多队列:
1 | # ethtool -l xgbe0 |
相关的网络参数也做了设置,比如read/write buffer, net.core.netdev_max_backlog等。
普通UDP benchmark
为了充分利用网卡多队列的优势,我们使用了多个端口,建立多条流进行测试。
UDP client 匀速按照指定的rate发送数据:
1 | conn, err := net.DialUDP("udp", srcAddr, dstAddr) |
client将接收到的回包进行统计,按照每秒一个周期聚合数据:
1 | func (c *Client) read() { |
服务端将收到的数据原封不动的返回:
1 | conn, err := net.ListenUDP("udp", &net.UDPAddr{ |
我们在测试机上运行这个测试程序,让客户端每秒1百万个包的速率发送,可以看到基本接近每秒百万的pps,时延0.2ms:
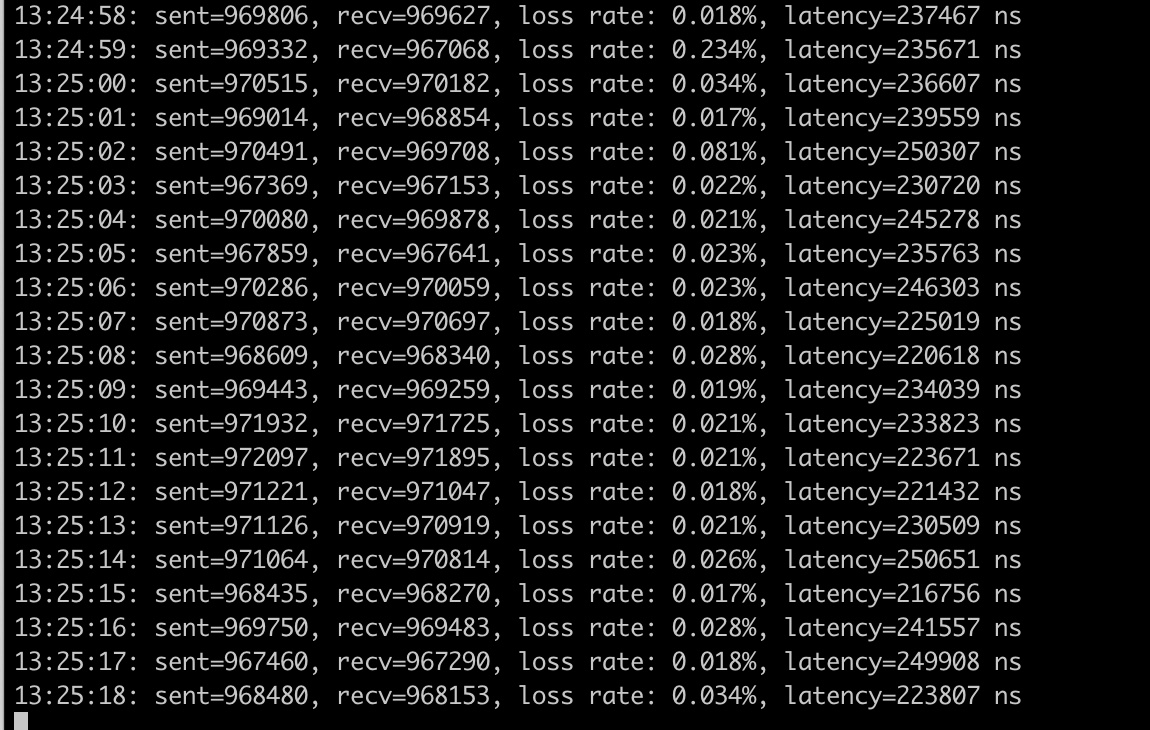
客户端的资源使用情况, CPU占用很多, idle 基本在36%左右:
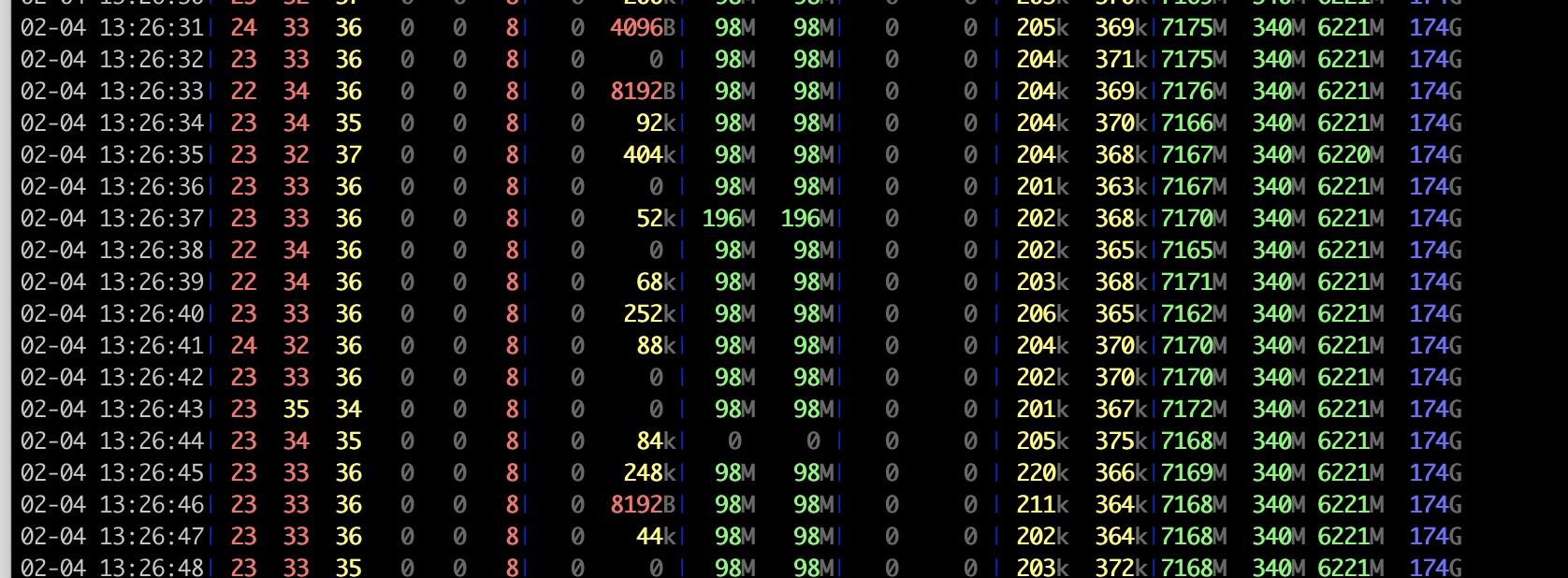
服务端的资源占用如下, CPU idle在 62%左右:
XDP 技术
上面的程序是中规中矩的UDP程序。如果分析我们的需求,你会发现我们的程序,尤其是服务端的程序非常的简单,基本就是实现一个rfc862的echo程序。
首先,我们先聊一聊bpf、ebpf和xdp。
在 1992 年 USENIX 会议上,论文“The BSD Packet Filter: A New Architecture for User-level Packet Capture”提出了革命性的包过滤机制 BSD Packet Filter(简称为 BPF),这比当时最先进的数据包过滤技术还快 20 倍。在 Linux 2.1.75 中,首次引入了 BPF 技术。在 Linux 3.0 中,增加了 BPF 即时编译器,它替换掉了原本性能更差的解释器,进一步优化了 BPF 指令运行的效率。
2014 年,Alexei Starovoitov 将 BPF 扩展为一个通用的虚拟机,也就是 eBPF。eBPF 不仅扩展了寄存器的数量,引入了全新的 BPF 映射存储,还在 4.x 内核中将原本单一的数据包过滤事件逐步扩展到了内核态函数、用户态函数、跟踪点、性能事件(perf_events)以及安全控制等。eBPF 的诞生是 BPF 技术的一个转折点,使得 BPF 不再仅限于网络栈,而是成为内核的一个顶级子系统。
XDP全称eXpress Data Path,即快速数据路径,XDP是Linux网络处理流程中的一个eBPF钩子,能够挂载eBPF程序,它能够在网络数据包到达网卡驱动层时对其进行处理,具有非常优秀的数据面处理性能,打通了Linux网络处理的高速公路。
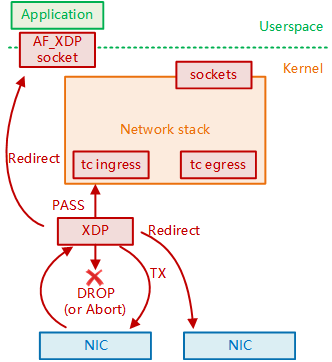
传统的Linux内核网络协议栈由于更加注重通用性,其网络处理存在着固有的性能瓶颈,随着10G、25G、40G、100G甚至更高速率的网卡出现,这种性能瓶颈变得更加突出,传统内核网络协议栈已经难以满足高性能网络处理的要求。在2010年,开发出了DPDK内核旁路(Kernel Bypass)技术,并逐渐成为网络处理加速的一种成熟方案。然而这种方案也有自己的一些固有缺陷,且始终是独立于linux内核的,在2016年的Linux Netdev会议上,David S. Miller让下面人和他一起念“DPDK is not Linux”。同年,伴随着eBPF技术的成熟,Linux也终于合入了属于自己的网络处理高速公路——XDP。
XDP能够在网络数据包到达网卡驱动层时对其进行快速处理,比如转发、重定向等。避免深陷linux协议栈的复杂处理流程,极大地提升网络传输性能,所以如果采用XDP技术,在服务区收到一个UDP包的,立即将其返回,不再经过后面的协议栈的处理,岂不是能够有更好的性能?
ebpf/XDP等技术和特性一直在发展,好处是我们能够使用越来越多的新功能,坏处就是你在写一个ebpf/XDP程序的时候,甚至找不到一个可运行的例子,会遇到不同的Linux版本、不同版本的库、不同厂商的提供的库、不同的编程语言等等。我使用ChatGPT生成一个XDP的例子都跑不起来,这也阻碍了XDP更广泛的采用,当然这也不方案一些大厂或者创业公司开始广泛的使用ebpf/XDP等技术开发了性能优异的产品,比如Facebook的四层负载均衡器Katran、Cilium的各个云原生网络产品、IOVisor的bcc、CloudFlare的bpf-tools等工具。
在这一节,我介绍一个XDP的简单的程序,把XDP程序的开发讨论和编译流程介绍一下,下一节在介绍基于XDP改成我们的UDP benchmark程序。
首先写一个XDP程序:
1 |
|
我们定义了一个用来统计用的数据结构datarec,用来记录处理的packet的数量和有问题的包的数量(为了简单,这个字段我们没有使用)。定义了一个映射stats_global_map用来传给用户态的程序查询这个统计结果。
然后定义xdp_prognum0处理逻辑。这里通过bpf_map_lookup_elem查询到统计map,然后对它的processed加一。
我们总是返回XDP_PASS, 让包继续往下处理。
对了,为了编写XDP程序,我专门购买了也给腾讯云的轻量级服务器,新人第一年不到100块钱,不是打广告啊,的的确确发现ebpf/XDP有时候必须需要新的内核和通用的Linux版本才更容易编译和运行。

可能你需要安装一些编译工具和libbpf库等。
1、 安装gcc和clang编译器:
1 | sudo apt-get install gcc clang |
2、安装LLVM工具链:
1 | sudo apt-get install llvm-dev libelf-dev libclang-dev |
3、安装Linux内核头文件:
1 | sudo apt-get install linux-headers-$(uname -r) |
4、下载并安装libbpf库:
1 | git clone https://github.com/libbpf/libbpf.git |
总之,环境准备好后,我们可以使用下面的命令编译这个XDP程序:
1 | clang -O2 -target bpf -c stat.c -o stat.o |
使用ip命令加载XDP程序并传入参数。例如,假设要加载的程序为my_xdp_prog.o,参数为param1和param2,并且要将程序绑定到接口eth0:
1 | sudo ip link set dev eth0 xdp obj my_xdp_prog.o sec my_xdp_sec param1 param2 |
但是呢,我不像这么做,而是想使用Go程序进行加在,并且每秒一次查询stat的统计数据打印出来。
Go语言有几个ebpf相关的库:
这里我使用cilium ebpf库, 活跃,而且cilium做出了产品,而且,还提供bpf2go工具,可以把XDP程序的C代码编译成字节码,嵌入到Go语言中,并且生成Go语言的辅助方法,收到bpftool gen skeleton工具的启发。
首先安装bpf2go工具:
1 | go install github.com/cilium/ebpf/cmd/bpf2go@latest |
然后写一个main.go文件,先准备好程序框架,在package上面加上go generate:
1 | //go:generate go run github.com/cilium/ebpf/cmd/bpf2go stat ebpf/stat.c |
它就会编译stat.c这个XDP程序,并生成辅助的方法:
对了,我开发是MacPro或者Mac mini上使用vscode做开发的,通过vscode ssh插件连接到我购买的这个腾讯云节点上,这样就方便使用Linux环境做编译了。
接下来完善main.go,实现加载XDP程序,并请示访问map查询处理的包的数量:
编译顺利,运行运行。
利用XDP实现网络程序的服务端
有了上面开发XDP程序的经验,我们就可以实现那个UDP的服务器端了。在开发之前,我们想想我们到底要做什么?
这个程序服务器基本就是个echo的功能,没有统计信息,没有额外的业务逻辑,只是把它收到的UDP包返回回去,所以我们XDP程序需要:
- 处理特定UDP目标端口的packet
- 把Mac地址(二层的数据帧)、IP地址(三层IP)、UDP(UDP端口)中的数据交换,再发包返回
- 从哪个网卡接收,就从哪个网卡中返回
这个程序我们我们定义我们要处理的端口范围是20000到20016, 凡事目的端口是这个范围的数据包,我们原封不动的把数据返回。
在数据返回时,我们交换了mac地址、IP地址和端口,把包改造成了返回包,这里我们偷了个懒,没用重新计算checksum。
最后我们返回XDP_TX, 也就是从哪个网卡队列接收的,再通过这个网卡队列返回和客户端:
1 |
|
接下来就是正常的套路,使用bpf2go生成辅助代码,使用cilium/ebpf加在:
1 | //go:generate go run github.com/cilium/ebpf/cmd/bpf2go echo ebpf/echo.c |
运行go generate,在运行CGO_ENABLED=0 go build .编译出echo程序,直接把这个echo程序复制到你的目的服务器中(最好5.15.x以上的内核),然后运行
1 | ./echo -iface eth0 |
在另外一台机器上 nc -u xxx.xxx.xxx.175测试一下,可以看到发送的数据又直接返回回来了,符合期望:
1 | # nc -u xxx.xxx.xxx.75 20000 |
一切准备妥当,我们在另外一台机器上,还是运行我们的udp程序,可以看到也是轻轻松松达到每秒百万个packet:
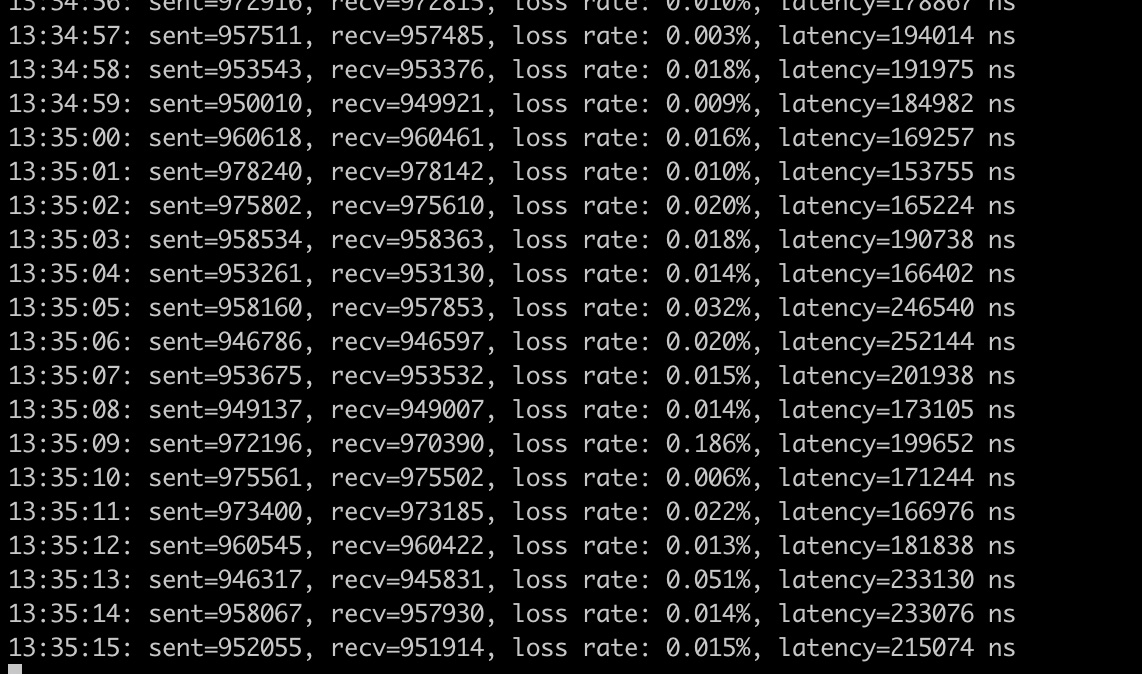
可以看到时延明显是变低了,在0.1ms ~0.2ms,这也是符合预期的,因为服务器根本就没有走到协议栈,在网卡驱动那里就把结果返回了。
在看看服务端资源占用情况:
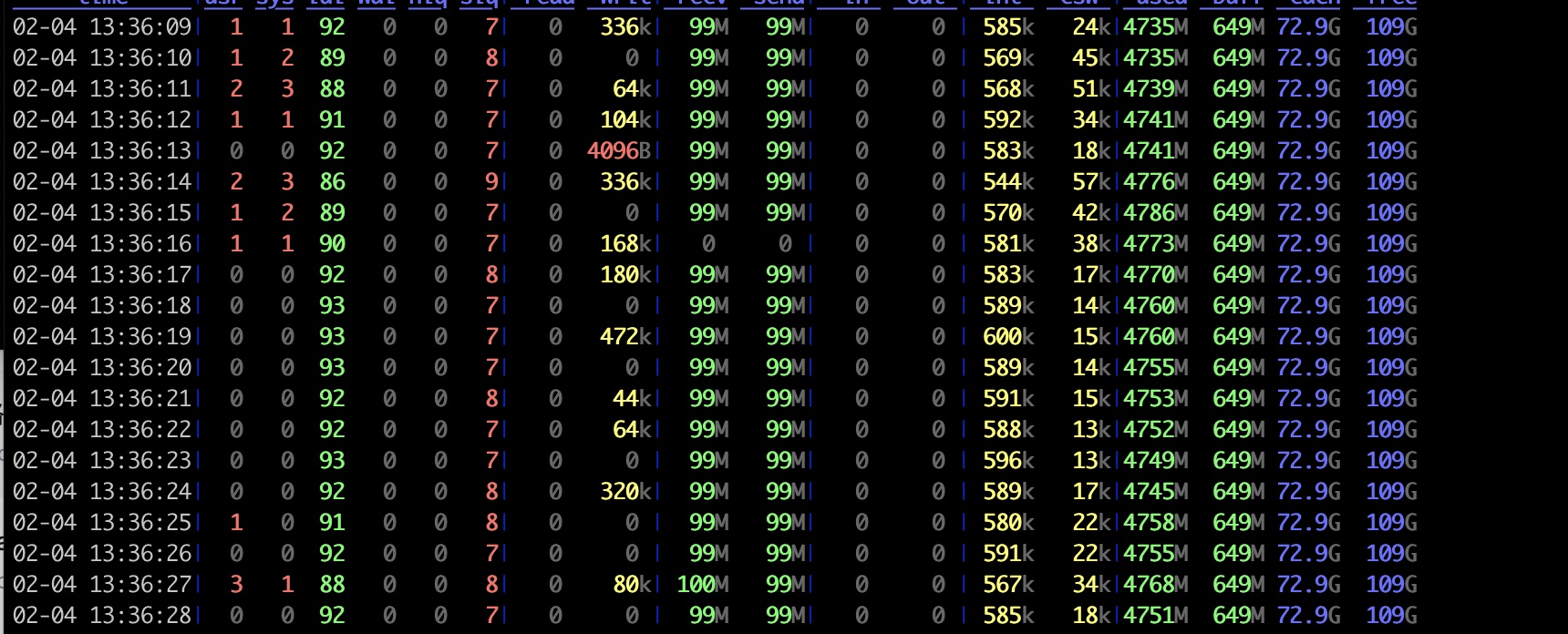
服务器CPU几乎没有占用,10%不到是用在了软中断上面, usr占用几乎为0, 这是XDP程序带来的巨大的好处。
