Go 语言的内存分配机制
目录
免责声明
这篇博文主要关注在 ARM 架构 Linux 系统上运行的 Go 1.24 编程语言。内容可能不涵盖其他操作系统或硬件架构的平台特定细节。
本文基于其他资料和我对 Go 的理解,可能并非完全准确。如有错误或建议,欢迎在最底部的评论区指正 😄。
引言
内存分配是每个编程语言运行时的核心,Go 也不例外。内存的高效分配和管理直接影响 Go 应用程序的性能、可扩展性和响应能力。
虽然 Go 通过简单的 API(new(T)、&T{} 和 make)抽象了大部分复杂性,但理解底层原理能让我们深入了解运行时如何实现高效性,以及潜在的性能瓶颈可能出现在哪里。
在这篇文章中,我们将深入探讨 Go 的内存分配器。我们将了解其核心组件,它们如何协作来服务不同大小的分配请求,以及栈是如何与堆对象一起管理的。在此过程中,我们将研究一些案例,以理解 Go 内存分配策略的实际含义。最终,你应该对 Go 如何在提供高性能的同时抽象内存管理有一个更清晰的认识。
在深入了解 Go 如何分配内存之前,有必要理解典型操作系统中内存工作原理的一些基本概念。
我建议你先阅读虚拟内存基础这篇文章。如果你已经熟悉这些概念,可以跳过那篇文章。
现在,让我们深入了解 Go 对虚拟内存的理解。
Go 对虚拟内存的理解
作为一个用户空间应用程序,Go 进程遵循基础文章中描述的标准虚拟内存布局。
具体来说,进程的栈段是与主线程关联的 g0 栈(又称系统栈)。已初始化(即具有非零值)的全局变量存储在数据段中,而未初始化的变量位于 BSS 段中。
Go 运行时不使用位于程序断点下方的传统堆段来分配堆对象。相反,Go 运行时主要依赖内存映射段为堆对象和 goroutine 栈分配内存。
从现在开始,我将把 Go 用于动态分配的内存映射段称为堆,它不要与程序断点下的传统进程堆混淆。

从 Go 运行时角度看的虚拟内存布局
Arena 和 Page
为了高效管理这些内存,Go 运行时将这些内存映射段分割成分层单元,从粗粒度到细粒度。
最粗粒度的单元称为 arenas,这是一个固定大小的 64 MB 区域。由于 mmap 系统调用的特性,arenas 不需要是连续的,因为它可能返回与请求不同的地址。
每个 arena 进一步细分为更小的固定大小单元,称为页(pages),每个页大小为 8 KB。需要注意的是,这些运行时管理的页与基础文章中讨论的典型操作系统页不同,后者通常为 4 KB。
如果对象小于 8 KB,每个页包含同一大小的多个对象;如果对象大小正好是 8 KB,则包含单个对象。大于 8 KB 的对象会跨越多个页。

Go 运行时中的内存页
这些页也用于分配 goroutine 栈。如我之前在 Go 调度器博文中讨论的,每个 goroutine 栈最初占用 2 KB,这意味着一个 8 KB 的页可以容纳最多 4 个 goroutine 栈。
Span 和 Size Class
Go 内存管理中的另一个关键概念是 span。span 是由一个或多个连续页组成的内存单元。每个 span 被细分为多个相同大小的对象。
通过将 span 分割为多个相等的对象,Go 有效地使用了分离匹配(segregated fit)内存分配策略。这种策略使 Go 能够为各种大小的对象高效分配内存,同时最小化碎片。
Go 使用 mspan 结构来保存 span 的元数据,如第一页的起始地址、跨越的页数、已分配对象的数量等。
在这篇博文中,当我提到 span 时,指的是它所代表的内存区域。当我提到 mspan 时,指的是描述该区域的结构体。
Go 运行时将对象大小组织成一组预定义的组,称为大小类(size classes)。每个 span 恰好属于一个大小类,由其包含的对象大小决定。Go 定义了 68 个不同的大小类,编号从 0 到 67,如这个大小类表所示。
大小类 0 保留用于处理大对象(大于 32 KB)的分配,而大小类 1 到 67 用于微小对象和小对象。

具有不同大小类的两个 span
属于某个大小类的 span 包含固定数量的页和对象,由表中的 bytes/span 和 objects 列确定。
上图展示了两个 span:一个来自大小类 38(包含 2048 字节对象),另一个来自大小类 55(包含 10880 字节对象)。
因为一个 8 KB 页正好能容纳四个 2048 字节的对象,大小类 38 的 span 在单个页内包含 8 个对象。相反,由于每个 10880 字节的对象超过一页,大小类 55 的 span 跨越 4 页,容纳 3 个对象。
但是为什么大小类 55的 span 不只包含一个对象并跨越 2 页呢?
原因是为了减少内存碎片。由于 span 内的对象是连续的,在最后一个对象和 span 末尾之间可能存在空间。这个空间称为尾部浪费(tail waste),可以通过公式 (页数)*8192-(对象数)*(对象大小) 轻松计算。
如果 span 分配在 2 页上,尾部浪费将是 2*8192-10880*1=5504 字节,显著高于分配在 4 页时的 4*8192-10880*3=128 字节的尾部浪费。

span 中的尾部浪费
虽然用户 Go 应用程序可以分配各种大小的对象,但为什么 Go 只为小对象定义了 67 个大小类?如果我们的应用程序分配一个 300 字节的小对象,而这个大小在大小类表中没有对应条目,会怎么办?
在这种情况下,Go 运行时会将对象大小向上舍入到下一个大小类,在这个例子中是 320 字节。
到目前为止展示的绿色对象不是用户 Go 应用程序实际分配的对象,而是由 Go 运行时管理的大小类对象。

用户对象和大小类对象
用户 Go 应用程序分配的对象(简称用户对象)包含在大小类对象中。用户对象大小可以变化,但必须小于它们所属的大小类对象的大小。因此,用户对象的大小和大小类对象的大小之间可能存在浪费。所有大小类对象中的这些浪费加上尾部浪费构成了 span 的总浪费。
⚠️ 一个大小类对象不总是包含恰好一个用户对象。对于小和大用户对象,每个大小类对象通常恰好包含一个用户对象。然而,对于微小用户对象,多个用户对象可以打包到单个大小类对象中,参见微小对象分配器。
让我们考虑最坏情况下大小类 55的一个 span,它包含三个用户对象,每个大小为 10241 字节,即大小类 55 对象的最小大小。
3 个大小类对象的浪费是 3*(10880-10241)=3*639=1917 字节,尾部浪费是 4*8192-10880*3=128 字节。
因此,这个 span 的总浪费是 1917+128=2045 字节,而 span 大小是 4*8192=32768 字节,导致最大总浪费 2045/32768=6.24%,如 Go 大小类表中大小类 55 的第 6 列所述。
尽管 Go 使用旨在最小化碎片的分离匹配策略,内存中仍然存在一些浪费。span 的总浪费反映了每个 span 外部碎片化的内存量。
Span Class
Go 的垃圾回收器是跟踪垃圾回收器,这意味着它需要遍历对象图来识别垃圾回收周期中所有可达对象。然而,如果已知某个类型不包含指针(无论是直接还是通过其字段),例如具有多个字段的结构,其中一些字段包含指向原始类型或其他结构的指针,那么垃圾回收器可以安全地跳过扫描该类型的对象以减少开销和提高性能,对吧?类型中是否存在指针是在编译时确定的,因此这种优化不会产生额外的运行时成本。
为了实现这种行为,Go 运行时引入了 span class 的概念。span class 根据两个属性对内存 span 进行分类:它们包含的对象的大小类和这些对象是否包含指针。
如果对象包含指针,则 span 属于扫描类(scan class)。如果不包含,则被归类为非扫描类(noscan class)。
因为指针存在是一个二元属性——类型要么包含指针,要么不包含——span class 的总数简单地是大小类数量的两倍。Go 总共定义了 68*2=136 个 span class。span class 用整数表示,范围从 0 到 135。
如果数字是偶数,它是扫描类;否则是非扫描类。
之前,我提到每个 span 恰好属于一个大小类。更准确地说,每个 span 恰好属于一个 span class。关联的大小类可以通过将 span class 编号除以 2 来获得。span 是否属于扫描或非扫描类由 span class 编号的奇偶性确定:偶数表示扫描 span,奇数表示非扫描 span。
Span Set
为了高效管理 span,Go 运行时将它们组织成一个称为 span set 的数据结构。span set 是属于同一 span class 的 mspan 对象的集合,如下图所示。

span set 的布局
本质上,它是一个数组切片。切片根据需要动态增长,每个数组的大小固定为 512 个条目。数组中的每个元素都是一个 mspan 对象,它保存 span 的元数据,因此可以为空。
上图中的紫色元素是非空的,而白色元素是空的。span set 还有两个额外字段:head 和 tail,用于跟踪 span set 中第一个和最后一个非空元素。
从 span set 弹出从 head 开始,自上而下遍历数组,在每个数组内从左到右遍历。推入从 tail 开始,同样自上而下遍历,从左到右填充每个数组。
如果推入或弹出元素导致数组为空,则数组从 span set 中移除并添加到空闲数组池中以供将来重用。
注意 head 和 tail 是原子变量,因此多个 goroutine 可以并发地从 span set 添加或移除 span,无需额外锁定。
堆位和 Malloc 头
给定一个有 1000 个字段的大结构,其中一些字段是指针,Go 的垃圾回收器如何知道哪些字段是指针,以便正确遍历对象图?
如果垃圾回收器必须在运行时检查每个对象的每个字段,那将是极其低效的,特别是对于大型或深度嵌套的数据结构。
为了解决这个问题,Go 使用元数据来高效识别指针位置,而无需扫描所有字段。这种机制基于两个关键结构:堆位(heap bits)和 malloc 头(malloc headers)。
对于小于 512 字节的对象,Go 在 span 中分配内存并使用堆位图来跟踪 span 中哪些字包含指针。位图中的每一位对应一个字(通常是 8 字节):1 表示指针,0 表示非指针数据。位图存储在 span 的末尾,由该 span 中的所有对象共享。当创建 span 时,Go 为位图保留空间,并使用剩余空间容纳尽可能多的对象。

span 中的堆位
对于大于 512 字节的对象,维护大位图是低效的。相反,每个对象伴随一个 8 字节的 malloc 头——指向对象类型信息的指针。这个类型元数据包括 GCData 字段,它编码了类型的指针布局。垃圾回收器使用这个数据在遍历对象图时精确高效地定位只包含指针的字段。

对象中的 malloc 头
堆管理
Go 在内存映射段之上构建了自己的堆抽象,由全局 mheap 对象管理。mheap 负责分配新 span、清理未使用的 span,甚至管理 goroutine 栈。
Span 分配:mheap.alloc
由于 Go 运行时在巨大的虚拟地址空间内运行,mheap 分配器在分配 span 时很难高效地定位连续的空闲页,特别是在高并发情况下。
在 Go 的早期版本中,如扩展 Go 页分配器提案中详述的,每个 mheap 操作都是全局同步的。这种设计在大量分配工作负载期间导致严重的吞吐量下降和尾部延迟增加。今天的 Go 内存分配器实现了该提案中的可扩展设计。让我们深入了解它如何克服这些瓶颈并在高度并发环境中高效管理内存分配。
跟踪空闲页
因为虚拟地址空间很大,每个页的状态(空闲或使用中)是二元属性,将此信息存储在位图中是高效的,其中 1 表示使用中,0 表示空闲。
注意,这里的使用中或空闲是指页是否已交付给 mcentral,而不是指用户 Go 应用程序是否使用中或空闲。
每个位图是一个包含 8 个 uint64 值的数组,总共占用 64 字节,可以表示 512 个连续页的状态。考虑到一个 arena 大小为 64 MB,每个页为 8 KB,一个 arena 中有 64MB/8KB=8192 个页。
由于每个位图覆盖 512 个页,一个 arena 需要 8192/512=16 个位图。每个位图占用 64 字节,一个 arena 的所有位图总大小为 16×64=1024 字节,即 1 KB。
然而,遍历位图寻找一连串空闲页仍然是低效的,而且如果位图不包含任何空闲页,这样做是浪费的。如果我们能以某种方式缓存空闲页,以便能快速找到空闲页而不需扫描位图,那就更好了。
Go 引入了位图摘要(summary)的概念,它有三个字段:start、end 和 max。start 是位图开头连续 0 位的数量。类似地,end 是位图末尾连续 0 位的数量。最后,max 表示最大的连续 0 位序列。
一旦位图被修改,即页被分配或释放时,摘要就会立即更新。
下图显示了一个位图摘要:开头有 3 个连续空闲页,末尾有 7 个连续空闲页,最长的空闲页连续数是 10。箭头表示地址空间的增长方向,即低地址的 3 个空闲页和高地址的 7 个空闲页。

位图摘要的可视化
有了这三个字段,Go 能够通过合并连续内存块的摘要,在单个 arena 内或跨多个相邻 arena 找到足够的连续空闲内存块。
考虑两个相邻的块,S1 和 S2,每个跨越 512 页。S1 的摘要是 start=3、end=7、max=10,而 S2 的摘要是 start=5、end=2、max=8。
由于这些块是连续的,它们可以合并成一个覆盖所有 1024 页的摘要。合并后的摘要计算为 start=S1.start=3、end=S2.end=2、max=max(S1.max, S2.max, S1.end+S2.start)=max(10, 8, 7+5)=12。

合并两个连续内存块的摘要
通过合并较低级别的摘要,Go 隐式构建了一个分层结构,实现对连续空闲页的高效跟踪。它使用单个全局基数树(radix tree)的摘要来管理整个虚拟地址空间,如下图所示。
每个蓝色框代表连续内存块的摘要,其到下一级的虚线反映了它在下一级覆盖的部分。绿色框代表叶节点摘要所指向的 512 页的位图。

整个地址空间的摘要基数树
在 linux/amd64 架构上,Go 使用 48 位虚拟地址空间,即 2^48 字节或 256 TB。在这种设置下,基数树的高度为 5。
内部节点(级别 0 到 3)存储从合并其 8 个子节点派生的摘要。每个叶节点(级别 4)对应单个位图的摘要,该位图覆盖 512 页。
级别 0 有 16384 个条目,级别 1 有 16384*8 个条目,级别 2 有 16384*8^2 个条目,级别 3 有 16384*8^3 个条目,级别 4 有 16384*8^4 个条目。
因为每个叶条目汇总 512 页,每个级别 0 条目汇总 512*8^4=2097152 个连续页,可容纳 2097152*8KB=16GB 的内存。
注意这些数字代表最大可能的条目。每个级别的实际条目数随着堆的增长而逐渐增加。

深入了解摘要基数树
如前所述,每个级别 0 条目汇总 2097152=2^21 个连续页,start、end 和 max 可能大到 2^21。因此,将所有这三个字段存储在一起需要最多 21*3=63 位。
这使得可以将摘要打包到单个 uint64 中,称为 pallocSum:前 21 位存储 start,接下来 21 位存储 end,后面 21 位存储 max。
有一个特殊情况:如果 max=2^21,意味着整个块都是空闲的。在这种情况下,start 和 end 也是 2^21,摘要编码为 2^63。相反,如果块没有空闲页,即所有 start、end 和 max 都是 0,摘要值肯定是 0。
摘要基数树实现为数组切片,其中每个切片对应一个树级别。数组固定树中的级别数,而切片随着堆扩展而动态增长。
较低地址的摘要保持在切片的开头,而较高地址的摘要附加到切片的末尾。由于给定级别的摘要切片覆盖整个保留地址空间,摘要在其切片内的索引直接确定了它代表的内存区域。
查找空闲页:pageAlloc.find
Go 使用深度优先搜索算法定位足够的空闲页连续区间。它从扫描基数树级别 0 的最多 16,384 个条目开始。如果摘要为 0(意味着没有空闲页),它移动到下一个条目。
如果在两个相邻条目的边界处,或在第一个条目的开始处,或在最后一个条目的结尾处找到足够的连续区间,那么它基于摘要所指向的地址立即返回空闲区间的地址。
否则,如果当前摘要的 max 字段满足分配请求,搜索下降到下一级别的 8 个子条目中。
如果搜索到达叶级别但仍无法找到足够的连续区间,那么它扫描 max 值足够大的条目内的位图,以定位确切的空闲页连续区间。
如果我们遍历级别 0 的所有条目但仍无法找到足够的连续区间,它返回 0,表示没有空闲页。
你可能注意到这个算法的一个缺点:如果级别 0 开始的许多页已经在使用中,分配器最终会为每次分配重复遍历基数树中的相同路径,这是低效的。
Go 通过维护一个称为 searchAddr 的提示来解决这个问题,它标记在此之前不存在空闲页的地址。这允许分配器直接从提示开始搜索,而不是从开头重新开始。
由于分配在堆中从低地址到高地址进行,提示可以在每次搜索后前进,缩小搜索空间,直到新内存被释放。在实践中,大多数分配发生在当前提示附近。
堆增长:mheap.grow
如果基数树中没有可用的空闲页,即 pageAlloc.find 返回 0,Go 运行时必须通过调用 mmap 系统调用要求内核扩展其虚拟地址空间。增长可能不像请求的页数那么大,而是以较大的块出现,向上舍入到 arena 大小(64 MB)。即使只请求单个页,堆也会在虚拟内存空间中扩展 64 MB(不是物理内存,感谢按需分页!)。
为了管理这个过程,运行时维护一个称为 arenaHints 的提示地址列表,这些是它希望内核用于新分配的地址。这个列表在 main 函数运行之前初始化,其值可以在这里找到。在堆增长期间,Go 遍历这些提示,通过将该地址传递给 mmap 系统调用的第一个参数,要求内核在每个建议的地址分配内存。
然而,内核可能选择不同的位置。如果发生这种情况,Go 移动到下一个提示。如果所有提示都失败,Go 退回到请求与 arena 大小对齐的随机地址的内存,然后更新提示列表,以便将来的增长与新分配的 arena 保持连续。
这个过程将内存段从 None 转换为 Reserved。一旦 arena 向运行时注册,即通过添加到所有 arena 列表,段就从 Reserved 转换为 Prepared。
此时,基数摘要树被更新以包含新的 arena,扩展每个级别的摘要切片,将新页的位图标记为空闲,并相应更新摘要。这个新内存段也被跟踪为使用中。
设置 Span:mheap.haveSpan
一旦找到请求的页连续区间,运行时设置一个 mspan 对象来管理该内存范围。
像任何其他 Go 对象一样,mspan 对象本身必须存在于内存中。因此,这些 mspan 对象由 fixalloc slab 分配器分配,它使用 mmap 系统调用直接从内核请求内存。
然后设置 span,包括其大小类、它覆盖的页数和第一页的地址。关联的内存段从 Prepared 转换为 Ready,表示它已准备好供 mcentral 使用。
缓存空闲页:mheap.allocToCache
不幸的是,pageAlloc.find 和 mheap.grow 都依赖于全局锁,这在重度并发分配工作负载下可能成为瓶颈。由于 Go 程序运行的并发性等于处理器 P 的数量,在每个 P 中本地缓存空闲页有助于避免全局锁争用。
Go 通过每个 P 的 pageCache 实现这一点。pageCache 由一个 64 页对齐内存块的基地址和一个跟踪这些页中哪些是空闲的 64 位位图组成。因为每个页是 8 KB,单个 P 的 pageCache 最多可以容纳 512 KB 的空闲内存。
当 goroutine 从 mheap 请求 span 时,运行时首先检查当前 P 的 pageCache。如果它包含足够的空闲页,这些页立即用于设置 span。如果没有,运行时退回到调用 pageAlloc.find 来定位足够的页连续区间。
如果 pageCache 为空,运行时分配一个新的。它首先尝试获取摘要基数树中当前提示 searchAddr 附近的页(如查找空闲页部分所述)。由于提示可能不准确,它可能需要遍历基数树来寻找空闲页。
注意,拥有 N 个空闲页的概率随着 N 接近 64 而下降,因为 pageCache 限制为 64 页。在这种情况下,缓存未命中会太多,运行时必须频繁退回到 pageAlloc.find 来寻找空闲页。这就是为什么如果 N 等于或大于 16,运行时不会检查缓存,而是直接退回到 pageAlloc.find。
下图总结了 span 分配中寻找空闲页的逻辑。灰色框"查找页"在查找空闲页部分描述,绿色框"堆增长"在堆增长部分描述,而蓝色框"设置 span"在设置 Span部分描述。
|
|
查找空闲页进行 span 分配的逻辑
一旦获得新页,它们在摘要基数树中被标记为使用中,以防止其他 P 声明它们,并确保分配器在下次堆增长时不会重用它们。摘要基数树提示也会更新,以便后续分配跳过这些使用中的页。
缓存 Span 对象:mheap.allocMSpanLocked
如设置 Span中讨论的,必须分配一个 mspan 对象来表示和管理页的 span。
如果直接从 mheap 获得 mspan 对象,需要获取全局锁,这可能成为性能瓶颈。为了避免这种情况,Go 运行时像页一样,为每个 P 缓存空闲的 mspan 对象。
当在 pageCache 中找到空闲页时,运行时首先检查当前 P 是否已经缓存了 mspan。如果有,可以立即重用,无需任何全局锁争用。否则,运行时从 mheap 分配多个 mspan 对象,将它们缓存在 P 的空闲列表中以供将来使用,并分配其中一个来管理新分配的页连续区间。
中央 Span 管理器:mcentral
由于 mheap 主要管理粗粒度的内存单元,如页和大 span,它没有提供分配和释放微小或小对象的高效方式。
这个角色由 mcentral 处理,它也充当 mheap 和每个 P 分配器 mcache(在处理器内存分配器中讨论)之间的桥梁。
内部数据结构
每个 mcentral 管理属于特定 span class 的 span。总共,mheap 维护 136 个 mcentral 实例——每个类一个。在一个 mcentral 内,有两类span set:full(没有空闲对象的 span)和 partial(有一些空闲对象的 span)。每个类别进一步分为两个 span set:已清理和未清理,取决于 span 是否已被清理。
|
|
mcentral 实例中的 span set
span 被清理意味着什么?Go 的垃圾回收器基于标记-清理:首先标记所有可达对象,然后清理不可达的对象,要么将该内存返回给运行时重用,要么在某些情况下,将其释放回内核以减少进程占用空间。清理是一个复杂过程,但本质上包括以下三个步骤:从未清理集合弹出 span,释放该 span 中标记为不可达的对象,将 span 推入已清理集合。
span 在 partial 和 full 之间的转换在分配或清理期间确定,取决于 span 中空闲对象的数量是增加还是减少。如果 span 中的空闲对象数量达到零,它从 partial 集合移动到 full 集合。否则,如果 span 中的空闲对象数量为正,它从 full 移动到 partial 集合。
由于如 Span Set 中讨论的,span set 是线程安全的,mcentral 可以被多个 goroutine 并发访问,无需额外锁定。这增加了 Go 程序 span 分配的吞吐量。
准备 Span:mcentral.cacheSpan
作为 mheap 和 mcache 之间的中介,mcentral 负责准备 span——要么从其 span set 获取现有的,要么从 mheap 请求——给请求的 mcache。为了说明,这个逻辑在以下流程图中详述。绿色框"请求 mheap 分配 span"的逻辑在Span 分配中描述。
|
|
mcentral 准备 span 的逻辑
回收 Span:mcentral.uncacheSpan
当 mcache 需要将 span 返回给 mcentral 时,它调用 mcentral.uncacheSpan 方法。如果 span 尚未被清理,它首先被清理以回收不可达对象。然后无论是否需要清理,span 都根据其空闲对象数量被放入 full 或 partial 已清理集合中。
处理器内存分配器:mcache
如Go 调度器文章中讨论的,每个处理器 P 充当 goroutine 的执行上下文。由于 goroutine 可能分配内存,每个 P 也维护其自己的内存分配器,称为 mcache,它针对微小和小堆分配进行了优化,也用于为 goroutine 分配栈段。
缓存空闲 Span
mcache 的名称来自于它在其 alloc 字段中为每个 span class 缓存有空闲对象的 span。当 mcache 实例初始化时,每个 span class 都用一个 emptymspan 实例缓存,它不包含空闲对象。当 goroutine 需要分配特定 span class 的用户对象时,它要求 mcache 提供一个空闲大小类对象来容纳请求的用户对象——要么从缓存的 span,要么如果缓存的 span 中没有空闲对象,则从 mcentral 请求新 span。这个逻辑如下图所示。
|
|
从 mcache 请求空闲大小类对象的逻辑
绿色框"将缓存的 span 返回给 mcentral"的逻辑在回收 Span中描述。蓝色框"请求 mcentral 提供新 span"的逻辑在准备 Span中描述。
微小对象分配器
所有各种大小的用户微小对象(小于 16 字节)都从 span class 5(或大小类 2)分配,其中每个大小类对象占用 16 字节。
每个 mcache 实例使用 3 个字段跟踪 span 中的微小分配:
tiny:当前有可分配空间的大小类对象的起始地址tinyoffset:最后分配的用户对象的结束位置(相对于tiny)tinyalloc:当前 span 中迄今为止分配的用户微小对象总数
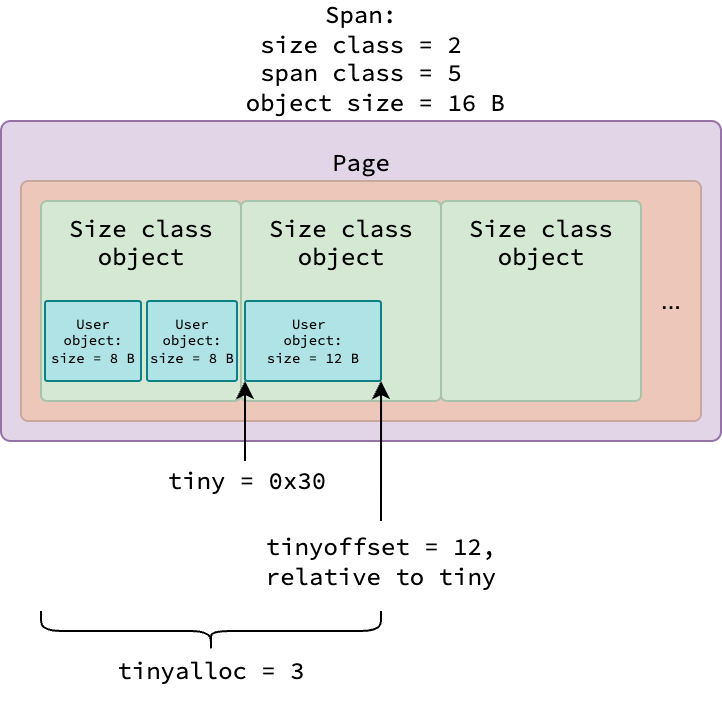
微小用户对象分配的示例 span
上图展示了用于微小对象分配的 span,其中 0x30 是大小类对象起始地址的示例。详细的分配逻辑将在微小对象:mallocgcTiny 中解释。
总结
如前面各节讨论的,Go 的内存分配器是一个复杂系统,有三个组件协同工作来高效管理内存:mheap、mcentral 和 mcache。
下图总结了这些组件如何交互为我们的 Go 程序分配内存。在深入下一节详细的堆分配逻辑之前,请花一点时间回顾它。

Go 内存分配器回顾
堆分配
在 Go 中,一个常见的误解是在堆上分配对象需要 new(T) 或 &T{}。由于几个原因,这并不总是如此。
首先,如果对象足够小,只存在于函数作用域内,并且不在该作用域外被引用,编译器可能将其分配在栈上而不是堆上。
其次,即使是用 var n int 声明的基本类型也可能在堆上结束,取决于逃逸分析。
第三,使用 make 创建复合类型(如切片、映射或通道)通常将其底层数据结构放在堆上。
在堆上分配对象的决定由编译器确定,将在栈还是堆?部分描述。
本节只关注 mallocgc——Go 运行时用于在堆上分配对象的方法。此方法将被各种内置函数和操作符间接调用,如 new、make、&T{}。
mallocgc 根据对象大小将其分为三类:微小(小于 16 字节)、小(16 字节到 32760 字节)和大(大于 32760 字节)。它还考虑对象类型是否包含任何指针,这影响垃圾回收。
基于这些标准,它调用不同的分配路径,如下图所示,以优化内存使用和性能。
|
|
mallocgc 如何分类对象
微小对象:mallocgcTiny
微小对象由每个处理器 P 中的 mcache 分配,使用微小对象分配器部分描述的三个属性。分配逻辑如下图所示。
|
|
mallocgcTiny 的概览逻辑
tinyoffset 根据请求大小对齐——如果能被 8 整除则 8 字节对齐,能被 4 整除则 4 字节对齐,能被 2 整除则 2 字节对齐,否则不对齐。
蓝色菱形中的检查意味着请求大小的用户对象从 tinyoffset 开始是否能适合当前大小类对象;如果可以,则可以在该大小类对象内分配新用户对象。绿色框"从 mcentral 请求 span class 5 的新 span"的逻辑在准备 Span部分描述。

微小对象分配
注意微小对象分配由 mcache 服务,它是每个处理器 P 本地的。这使分配线程安全且无锁,除非必须通过 mcentral 从 mheap 请求新 span 时。
微小对象分配使用的 span 属于 span class 5,或大小类 2。根据大小类表,大小类 2 的 span 容纳 512 个大小类对象。
由于每个大小类对象可以在微小分配中容纳多个用户对象,单个 span 可以服务至少 512 次微小用户对象分配而无需任何锁。
小对象:mallocgcSmall*
为了让垃圾回收器高效识别活跃对象并跳过对不包含其他对象引用的对象的跟踪,Go 根据类型是否包含指针(在 Span Class 部分描述)将小对象分为扫描和非扫描 span class。
扫描 span class 进一步分为两类:带堆位的和带 malloc 头的(在堆位和 Malloc 头部分描述)。
Go 基于这些分类实现了不同的函数来分配小对象。
非扫描小对象:mallocgcSmallNoscan
不包含指针的小对象由 mallocgcSmallNoscan 函数分配。
请求的 size 首先向上舍入,使对象恰好适合大小类对象。由于分配是非扫描的,span class 计算为 2*sizeclass+1。
例如,如果用户请求 365 字节的对象,它向上舍入到最接近的大小类 384 字节,或大小类 22。对应的 span class 因此是 45(2*22+1)。
然后函数检查当前处理器 P 的 mcache 中计算出的 span class 的缓存 span 是否有空闲对象。如果没有,它通过从 mcentral 请求新 span 并将其缓存在 mcache 中来请求空闲大小类对象。获得空闲大小类对象后,它更新垃圾回收器和分析器的信息,并返回分配对象的地址。
扫描小对象:mallocgcSmallScanNoHeader 和 mallocgcSmallScanHeader
根据其大小,包含指针的小对象由 mallocgcSmallScanNoHeader 或 mallocgcSmallScanHeader 函数分配。如果请求的 size 小于或等于 512 字节,分配由前者处理;否则,由后者处理。
这两个函数的逻辑与 mallocgcSmallNoscan 类似,除了 span class、span 布局和 span 内大小类对象的布局。
mallocgcSmallScanNoHeader 使用的 span 与 mallocgcSmallNoscan 使用的不同——它在末尾包含称为堆位的特殊数据(参见堆位和 Malloc 头)。由于这些 span 必须保留空间存储堆位,它们能容纳的大小类对象比大小类表中指定的要少。保留逻辑在 mheap.initSpan 方法中实现。
mallocgcSmallScanHeader 使用的 span 内大小类对象的布局也很特殊——每个大小类对象都有一个 malloc 头(参见堆位和 Malloc 头)作为前缀。因此,为了让用户对象和 malloc 头恰好适合大小类对象,请求的 size 在向上舍入到最接近的大小类之前增加 8 字节。
例如,假设 Go 代码请求一个包含指针的 636 字节对象。虽然这通常适合大小类 28(640 字节),但这个对象包含指针的事实需要 malloc 头,将大小增加到 644 字节。这将分配推入大小类 29(704 字节)。
大对象:mallocgcLarge
由于 mcache 和 mcentral 只管理最大 32KB 大小类的 span,大对象(大于 32760 字节)直接从 mheap 分配(参见Span 分配),无需咨询 mcache 或 mcentral。
容纳大对象的 span 也可以是扫描或非扫描的。与小对象不同,大对象不因 span class 而变化:扫描 span 总是 0,非扫描 span 总是 1。
当分配大对象时,例如包含 100 万个大结构的切片,内核不会立即提交物理内存。相反,它为分配保留虚拟地址空间。只有当程序首次写入该区域时,物理页才会被分配,这要感谢按需分页。
栈管理
如Go 调度器文章中讨论的,Go 运行时代码和用户代码都运行在内核管理的线程上。每个线程都有自己的栈——一个连续的内存块,保存栈帧,栈帧又存储函数参数、局部变量和返回地址。
由于在栈上分配变量只是调整栈指针(如栈分配中解释的),我们的重点是 Go 中栈如何分配和管理。
在 Go 中,线程的栈称为系统栈,而 goroutine 的栈简称为栈。
为了管理执行上下文,运行时引入了 m(线程)和 g(goroutine)抽象。每个 g 都有一个 stack 字段记录其栈的开始和结束地址。每个 m 都有一个特殊的 g0 goroutine,其栈代表系统栈。运行时在执行必须在系统栈而非 goroutine 栈上运行的操作时使用 g0,如增长或收缩 goroutine 的栈。
主线程的系统栈在 Go 进程启动时由内核分配。对于非主线程,它们的栈由内核或 Go 运行时分配,取决于操作系统以及是否使用 CGO。
在 Darwin 和 Windows 上,内核总是为非主线程分配系统栈。然而在 Linux 上,Go 运行时为非主线程分配系统栈,除非使用 CGO。
 |
| 
Darwin/Windows 中进程的虚拟内存布局 | Linux 中进程的虚拟内存布局
内核分配的系统栈位于 Go 管理的虚拟内存空间之外,而运行时分配的系统栈在其内部创建。内核确保其系统栈不会与 Go 的管理内存冲突。
内核分配的系统栈通常从 512 KB 到几 MB,而 Go 分配的系统栈固定为 16 KB。
相比之下,goroutine 栈以 2 KB 开始,可以根据需要动态增长或收缩。
分配栈:stackalloc
Go 运行时管理的栈——无论是系统栈还是 goroutine 栈——都容纳在 span 中,就像堆对象一样。你可以将栈看作专门用于在 Go 运行时或用户代码执行期间保存局部变量和函数调用帧的特殊堆对象。
栈通常从当前 P 的 mcache 分配。如果垃圾回收正在进行,当处理器 P 数量改变时,或如果当前线程在系统调用期间从其 P 分离,栈则从全局池分配。
有两个池:小池用于小于 32 KB 的栈,或大池用于等于或大于 32 KB 的栈。
Goroutine 以小栈开始,因此由小栈池分配,但当由于调用更多函数或分配更多栈变量而增长超过 32 KB 时,使用大栈池。这种行为将在栈增长部分描述。
从池分配栈
小栈池是一个四条目的 mspan 双向链表数组,每个 span 保存虚拟内存块的元数据。
此池中的所有 span 都属于 span class 0 并覆盖四个连续页,因此每个 span 占用 32 KB。数组中的每个条目对应一个栈顺序,它确定栈大小:顺序 0 → 每个栈是 2 KB,顺序 1 → 每个栈是 4 KB,顺序 2 → 每个栈是 8 KB,顺序 3 → 每个栈是 16 KB。
你可能想知道为什么栈以这种方式分为顺序和大小。原因是 goroutine 栈是连续的内存区域,当它们增长时大小翻倍。这种行为将在栈增长部分详细解释。

小栈池
当请求小于 32 KB 的栈时,运行时首先根据请求大小确定适当的顺序。然后检查该顺序链表的头部以找到可用的 span。如果没有可用的 span,它从 mheap 请求一个(参见Span 分配)并将其分割成所需顺序的栈。一旦 span 准备好,Go 运行时取第一个可用栈,更新 span 的元数据,并返回栈。
大栈池就是各种大小栈的链表,每个栈包含在 span class 0 的 mspan 中。
当请求等于或大于 32 KB 的栈时,从链表弹出第一个栈并返回。如果链表为空,它从 mheap 请求新 span(参见Span 分配)。
注意由于栈池是全局的,可以被多个线程并发访问,因此它们受互斥锁保护以确保线程安全,代价是由于锁争用导致吞吐量降低。
从缓存分配栈
为了减少分配栈时的锁争用,每个处理器 P 在其 mcache 中维护自己的栈缓存。
类似于小栈池,栈缓存是一个四条目的空闲栈单向链表数组,每个条目对应一个栈顺序。
当服务小栈分配请求时,运行时首先检查当前 P 的栈缓存以寻找可用栈。如果没有,它通过从小栈池请求一些栈来重新填充缓存,缓存它们,并返回第一个。
大栈不从栈缓存服务,它们总是直接从大栈池分配。
栈增长:morestack
分段栈
历史上,Go 使用分段栈方法。每个 goroutine 以小栈开始。如果函数调用需要比当前栈可用空间更多的栈空间,将分配一个新的栈并链接到前一个。当函数返回时,新栈将被释放,执行继续在前一个栈上。这个过程称为栈分割。
下面的代码片段和图展示了一个场景,其中 ingest 函数逐行处理文件中的数据,其中 read 的栈帧分布在两个栈中。
如果栈指针达到某个限制(所谓的栈保护,稍后讨论),对 read 或 process 的调用可能触发栈分割。
请注意,在这种方法中,goroutine 栈可能不包含连续内存区域。
|
|

分段栈策略中的栈分割
然而,这种分段栈方法有一个称为热栈分割问题的性能问题。如果函数在紧密循环内反复需要频繁分配和释放栈,整个过程将产生显著的性能损失。
当函数返回时,新分配的栈被释放。由于每次栈分割需要 60 纳秒,这个问题导致显著开销,因为它在循环的每次迭代都会发生。
避免这个问题的一个技巧是向在循环内频繁调用的函数的栈帧添加填充。我们可以分配虚拟局部变量来增加栈帧大小,从而减少栈分割的可能性。但从 Go 程序员的角度来看,这是容易出错的并降低代码可读性。
连续栈
为了缓解热栈分割问题,Go 1.4 版本后切换到称为连续栈的方法。
当 goroutine 栈需要增长时,分配一个比当前大两倍的新较大栈。当前栈的内容复制到新栈,goroutine 切换使用新栈。

连续栈策略中的栈复制
上图展示了连续栈,并显示当未充分利用时它不会收缩(例如,第一次迭代完成后)。这种行为有助于缓解热分割问题。
然而,如果 goroutine 栈从不收缩,如果它在峰值使用期间显著增长但后来大部分空间未使用,内存可能被浪费。
实际上,在连续栈方案中,goroutine 栈在垃圾回收周期期间收缩而不是函数返回时。如果总的栈内使用大小少于当前栈大小的四分之一,分配一个当前大小一半的新较小栈。当前栈的内容复制到新栈,goroutine 切换使用新栈。
详见 shrinkstack。
如Go 调度器文章中提到的,为了让 goroutine 栈增长,必须在函数序言中插入一些检查。
检查基本上是 CPU 指令,需要 CPU 周期执行。对于频繁调用的小函数,这种开销可能是显著的。
为了缓解这种开销,小函数标记为 //go:nosplit 指令,它告诉编译器不要在其序言中插入栈增长检查。
⚠️ 不要混淆。//go:nosplit 中的"split"听起来与分段栈方法中的栈分割相关,但它实际上也意味着连续栈方法中的栈增长检查。
栈保护
当调用函数时,栈指针按函数栈帧的大小减少。然后它与 goroutine 的栈保护检查,这决定是否需要栈增长。
栈保护由两部分组成:StackNosplitBase 和 StackSmall。在 Linux 上,这将保护放在栈底上方 928 字节处—— StackNosplitBase 800 字节和 StackSmall 128 字节。

goroutine 栈中栈保护的位置
但是溢出意味着栈指针超出栈,那么为什么栈指针针对栈保护而不是栈底检查?
原因在 Go 运行时源代码的这个注释中解释。让我用更简单的术语重新解释。
首先,由于 Go 允许函数通过标记为 //go:nosplit 不执行栈增长检查,必须保留等于 StackNosplitBase 的空间,以便它们可以安全执行而不引用任何无效地址。
例如,morestack——它本身处理栈增长——必须让其整个栈帧适合分配的栈。
其次,它充当栈帧小于 StackSmall 的小函数的优化。
当调用这些函数时,Go 不会费心减少栈指针并针对栈保护检查它。相反,它简单地检查当前栈指针是否低于栈保护,通过跳过栈指针调整为每次函数调用节省一个 CPU 指令。
重用栈:stackfree
当 goroutine 完成执行,goroutine 栈因有太多可用空间而收缩,或 Go 运行时管理的系统线程退出时,它们的栈被标记为可重用。
如果 goroutine 当前与处理器 P 连接且 P 的栈缓存大小足够小,其栈返回到该 P 的栈缓存。
否则,栈返回到全局池——根据栈的大小,要么是具有相应顺序的小栈池,要么是大栈池。
当栈返回到全局池时,如果垃圾回收不在进行中,相应的内存页将返回给内核。
详见 Go 运行时源代码中的这个注释。
栈还是堆?
有人可能认为 var n T 总是在栈上分配,而 new(T) 或 &T{} 总是在堆上分配类型 T 的对象。
但在 Go 中并非总是如此。让我们检查一些假设的例子来了解背后的问题以及 Go 如何解决它们。
考虑以下程序,它定义了一个函数 getUserByID,通过标识符检索用户。
假设 getUserByID 在栈上分配 User 结构,从数据库获取用户数据,并返回该结构的地址,即返回指向该结构的指针。
|
|

悬空指针问题
当调用 getUserByID 时,user 变量放在其栈帧的地址 0xe0。函数返回后,user 仍保存地址 0xe0,但该地址不再有效,因为 getUserByID 的栈帧已被弹出。
当 main 然后尝试访问 user.age 时,它解引用无效地址,导致悬空指针问题和未定义行为。
为了防止此类问题,Go 采用称为逃逸分析(escape analysis)的技术,在编译时进行。
逃逸分析确定变量——用 var n T、new(T)、&T{} 或 make(T) 声明——是否可以安全地分配在 goroutine 栈上,或必须逃逸到堆上。
如果变量被认为在其声明函数之外被引用,它在堆上分配以确保在函数返回后可以安全访问。
在上面的代码片段中,user 变量被确定逃逸到堆,因为其地址被返回并在 main 中使用。因此,编译器在堆上分配 user 以防止悬空指针问题。
逃逸分析也试图将变量保持在栈上,即使它们通常是堆分配的(例如,用 new(T)、&T{} 或 make(T) 关键字创建的),只要它们被证明只在函数作用域内使用且在编译时不占用超过 MaxImplicitStackVarSize 的内存空间。
你可以通过使用 -gcflags="-m" 选项编译以下程序来验证这些行为,该选项指示编译器打印优化决策,包括逃逸分析结果。
|
|
我们可以看到 user 被移动到堆,因为它逃逸了,而用 make([]User, 100) 创建的切片不会逃逸,因为它只在 main 中使用且其大小小于 MaxImplicitStackVarSize。
现在,尝试将切片的长度更新为 1,000,000 并用相同选项再次编译程序,观察下面的输出。
user 仍然逃逸到堆,但这次用 make([]User, 1000000) 创建的切片也逃逸了,因为其大小超过 MaxImplicitStackVarSize,因此太大无法适合栈。
|
|
案例研究
既然你对 Go 如何为堆对象和栈分配内存有了更好的理解,让我们检查一些实际例子来理解 Go 在实践中如何分配内存以及如何优化堆分配。
案例研究 1:重用切片的底层数组
如你可能知道的,Go 中的切片是一个描述符,包含指向底层数组的指针、其长度和容量。
当我们用 make([]T, length, capacity) 创建新切片时,编译器用对 Go 运行时中 makeslice 的调用覆盖 make 关键字。
makeslice 然后用等于 capacity*sizeof(T) 的大小调用 mallocgc 在堆上分配底层数组。
换句话说,capacity 跟踪底层数组的大小,而 length 跟踪数组中使用中元素的数量。
append 将新元素追加到切片末尾,增加其长度。如果新长度超过当前容量,append 调用 mallocgc 分配一个两倍大的新底层数组,将现有元素复制到新数组,并更新切片描述符指向新数组。
Go 中的切片可以使用 [start:end] 语法重新切片。重新切片创建一个新的切片头,指向与原始切片相同底层数组内的元素子范围。
重要的是,这个操作不复制数据或分配额外内存——新切片简单地重用现有数组。详见切片介绍。
我们可以利用重新切片行为通过重用切片的底层数组而不是创建新数组来优化堆分配。考虑以下程序,它解析 CSV 文件并逐行处理每行,其中每行可能有大量字段。
|
|
由于 parse 为每行创建空切片,它每次被调用时都在堆上分配新的底层数组。另外,由于对行中每个字段调用 append,如果字段数量超过底层数组的初始容量,它可能触发多次堆分配。
mallocgc 中的相同路径被重复执行,导致许多浪费的堆分配。
让我们通过重用 row 切片的底层数组来优化程序。通过用 row[:0] 重新切片,我们将切片的长度重置为零,同时保持其容量不变。
堆分配只在第一次调用 parse 时发生,即解析第一行时。对于有 1,024 个字段和 1,000,000 行的 CSV 文件,堆分配次数从 1000000*log₂(1024)=10⁷ 减少到仅 log₂(1024)=10 次,简单通过重新切片。
|
|
案例研究 2:将多个变量组合成单个结构
最近,iter 包中有一个提交,将多个标量变量组合成单个结构。

将多个变量组合成单个结构
最初,由于这 7 个变量超出函数作用域,它们都在堆上单独分配,因此导致 7 次对 mallocgc 的调用。
虽然其中一些变量小于 16 字节,可以由微小对象分配器分配,但如果频繁调用 Pull,7 次对 mallocgc 的调用开销仍然很大。
通过将这些变量组合成单个结构,只需要一次对 mallocgc 的调用就能在堆上分配结构,提高内存分配效率。
然而,这种方法有一个缺点,就是将不相关的对象耦合在一起,这阻止垃圾回收器回收不再需要的单个对象。
但是,在这个特定情况下,由于大部分这些变量一起使用,这种权衡是可以接受的。
原始 PR 中的基准测试结果(复制如下)显示堆分配次数从 11 减少到 5。差异与上述分析一致,其中 7 个变量组合成单个结构,因此节省 6 次对 mallocgc 的调用。
另外,内存消耗和分配时间减少约三分之一。
|
|
案例研究 3:使用 sync.Pool 重用对象
在一些应用程序中,经常创建和丢弃同一类型的许多短期、无状态对象。
一个典型例子是 pp 打印器对象,它在 fmt 包中广泛使用,用于格式化常用函数中的字符串,如 Fprintf 和 Sprintf。
如果这些函数分配新的 pp 对象,用它执行格式化,然后在完成时丢弃它,那么当你的应用程序每秒写 10,000 条日志时,转化为每秒分配 10,000 个 pp 对象,之后被垃圾回收器扫描。这种模式由于频繁堆分配和垃圾回收导致显著开销。
为了减少这种开销,Go 提供 sync.Pool,一种缓存和重用同一类型对象的机制。
当处理 Get 请求时,sync.Pool 首先在其池中寻找可用对象。如果找不到,它调用用户定义的 New 函数创建一个,最终调用 mallocgc 在堆上分配它。客户端使用对象完毕后,可以使用 Put 方法将其返回池中。通过回收对象,sync.Pool 减少堆分配次数和垃圾回收器需要扫描的对象数量,从而提高性能。
实际上,Fprintf 和 Sprintf 从池中请求 pp,用它格式化,然后将其返回池以供将来重用。ppFree 池在导入 fmt 包时初始化。
sync.Pool 设计为无锁且在高并发下高效。为了实现这一点,它依赖一种称为固定(pinning)的技术,防止 goroutine 在池中获取或放置对象时被抢占。由于 sync.Pool 对每个处理器 P 是本地的,固定确保 goroutine 在操作期间保持在同一 P 上。
结论
Go 的内存分配器设计有明确目标:在高度并发应用程序中提供高效性。
通过在 mheap、mcentral 和 mcache 之间分层其分配策略,运行时平衡全局协调与每 P 缓存,最小化锁争用同时保持分配快速。
栈虽然与堆对象管理方式不同,但遵循高效分配和自适应增长的类似原则。
对于大多数 Go 开发者,这些细节隐藏在简单构造如 &T{}、new(T) 和 make(T) 背后。
然而,理解内部机制为为什么某些模式比其他模式表现更好、垃圾回收器如何与分配交互,以及运行时为实现大规模低延迟并发所做的权衡提供了宝贵见解。
在构建和优化 Go 应用程序时,请记住你创建的每个变量或 goroutine 最终都由这些机制支持。
我希望你发现这些知识对编写更高效可靠的 Go 程序有用。
如有任何疑问,请随时留言。如果你真的喜欢我的内容,请考虑支持我!😄
参考资料
- Ankur Anand. Go 内存分配器可视化指南。
- sobyte.net. Go 内存分配,Go 栈管理。
- Michael Knyszek, Austin Clements. 扩展 Go 页分配器。
- Dmitry Vyukov. Go 调度器:实现轻量级并发的语言。
