现在谈起大数据几乎等价于谈论Hadoop及其它的生态圈产品。但是现在一个下一代的计算框架已经长大,而且声名显赫。那就是Spark。你或许已经听说过它以及它的诸多好处。
自从发布之日起,Hadoop就被认为是Google大数据工具的等价实现。它帮助很多公司处理先前不可想象的大数据。围绕着它的两个主要部件(HDFS,分布式一致性的文件系统,和MapReduce, 分布式的计算框架), 一堆相关的工具涌现, 补充并提高它的功能。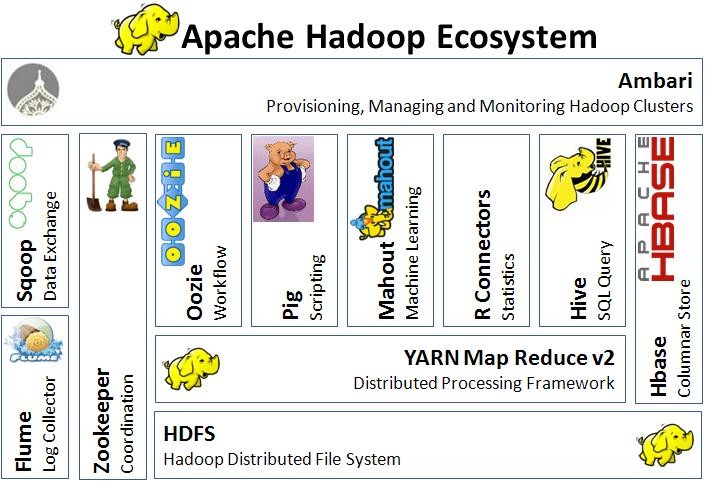
使用Scala开发Kafka应用

Kafka官方提供了Producer和Consumer的例子。 尽管Kafka是由Scala开发的,但是却没有提供使用Scala编写Producer和Consumer的例子。
本文介绍了使用Scala开发producer和consumer的例子。
项目代码可以在github上浏览下载: kafka-example-in-scala 。
Kafka实践:通过8个case学习Kafka的功能

Apache Kafka是分布式发布-订阅消息系统。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
Apache Kafka与传统消息系统相比,有以下不同:
- 它被设计为一个分布式系统,易于向外扩展;
- 它同时为发布和订阅提供高吞吐量;
- 它支持多订阅者,当失败时能自动平衡消费者;
- 它将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。
我们将通过几个case学习Kafka的功能。
Kafka 配置参数
Kafka为broker,producer和consumer提供了很多的配置参数。 了解并理解这些配置参数对于我们使用kafka是非常重要的。
本文列出了一些重要的配置参数。
官方的文档 Configuration比较老了,很多参数有所变动, 有些名字也有所改变。我在整理的过程中根据0.8.2的代码也做了修正。
30个你必须熟记的CSS选择器
英语原文: The 30 CSS Selectors you Must Memorize
中文翻译 by Yimin Zhou: 30个你必须熟记的CSS选择器
另外一个关于CSS slector的资源是: MDN CSS Selectors
你学会了基本的id,class类选择器和descendant后代选择器,然后就觉得完事了吗?如果这样,你就会错过许多灵活运用CSS的机会。虽然本文提到的许多选择器都属于CSS3,并且只能在现代的浏览器中使用,但学会这些是大有好处的。
7个你可能不知道的CSS单位
原文:7 CSS Units You Might Not Know About
译文:7个你可能不知道的CSS单位
译者:dwqs
众所周知,当使用CSS技术的时候,很容被一些奇异问题给困住。而当我们面对新的问题时,这会让我们处于非常不利的位置。
但是,伴随着Web的发展,新的解决方案也在慢慢成熟。因此,作为一个Web设计和前端开发人员,除了对我们使用的工具或属性非常了解并能熟练运用,已经别无选择了。
这也意味着,对于那些特别的工具或属性,即使平常很少使用,但是当需要的时候,我们也能很好的把它运用到工作中。
今天,我就介绍一些你之前可能不知道的CSS 属性,是一些例如px和ems测量方面的单位,但是很有可能你之前都没听过这些。一起来看看吧。
Android 开发最佳实践

原文: Best practices in Android development
Futurice公司Android开发者总结的经验。
遵循以下准则,避免重复发明轮子。若您对开发iOS或Windows Phone 有兴趣,
请看iOS Good Practices 和 Windows client Good Practices 这两篇文章。
Java程序员应当知道的10个面向对象设计原则
原文: Java程序员应当知道的10个面向对象设计原则
程序员学架构 翻译自 http://javarevisited.blogspot.com/2012/03/10-object-oriented-design-p
面向对象设计原则是OOPS编程的核心, 但我见过的大多数Java程序员热心于像Singleton (单例) 、 Decorator(装饰器)、Observer(观察者) 等设计模式,而没有把足够多的注意力放在学习面向对象的分析和设计上面。学习面向对象编程像“抽象”、“封装”、“多态”、“继承” 等基础知识是重要的,但同时为了创建简洁、模块化的设计,了解这些设计原则也同等重要。我经常看到不同经验水平的java程序员,他们有的不知道这些OOPS 和SOLID设计原则,有的只是不知道一个特定的设计原则会带来怎样的益处,甚至不知道在编码中如何使用这些设计原则。
(设计原则)底线是永远追求高内聚、低耦合的编码或设计。 Apache 和 Sun的开源代码是学习Java和OOPS设计原则的良好范例。它们向我们展示了,设计原则在Java编程中是如何使用的。Java JDK 使用了一些设计原则:BorderFactory类中的工厂模式、Runtime类中的单例模式、java.io 类中的装饰器模式。顺便说一句,如果您真的对Java编码原则感兴趣,请阅读Joshua Bloch 的Effective Java,他编写过Java API。我个人最喜欢的关于面向对象设计模式的是Kathy Sierra的Head First Design Pattern(深入浅出设计模式),以及其它的关于深入浅出面向对象分析和设计。这些书对编写更好的代码有很大帮助,充分利用各种面向对象和SOLID的设计模式。
虽然学习设计模式(原则)最好的方法是现实中的例子和理解违反设计原则带来的不便,本文的宗旨是向那些没有接触过或正处于学习阶段的Java程序员介绍面向对象设计原则。我个人认为OOPS 和SOLID设计原则需要有文章清楚的介绍它们,在此我一定尽力做到这点,但现在请您准备浏览以下设计模式(原则) :)
Java WebSocket教程
翻译自 mastertheboss的 WebSockets tutorial on Wildfly 8,同时在翻译的过程中增加了很多的背景知识。
WebSocket 是web客户端和服务器之间新的通讯方式, 依然架构在HTTP协议之上。使用WebSocket连接, web应用程序可以执行实时的交互, 而不是以前的poll方式。
WebSocket是HTML5开始提供的一种在单个 TCP 连接上进行全双工通讯的协议,可以用来创建快速的更大规模的健壮的高性能实时的web应用程序。WebSocket通信协议于2011年被IETF定为标准RFC 6455,WebSocketAPI被W3C定为标准。
在WebSocket API中,浏览器和服务器只需要做一个握手的动作,然后,浏览器和服务器之间就形成了一条快速通道。两者之间就直接可以数据互相传送。
Material Design 风格的设置页面

设置页面是 Android 开发 APP 几乎必须的一个页面。
Google 在发布 Material Design 的一些兼容包的时候,一直没有解决的一个大问题就是设置页面。让device-2015-02-20-132630人很蛋疼的是,如果你继承 PreferenceActivity 来做设置页面的话,会导致你的这个页面 ActionBar 丢失,完全显示不出来,丑,而且官方貌似一直没有解决,真不知怎么想的。所以一般我们的解决办法就是使用 Activity + Fragment 来保留 ActionBar 又能使用简易的 PreferenceFragment。
