
张奇 写的关于Activity生命周期的文章。
关于Activity的生命周期网上也有很多文章,最经典的莫过于官方的一张图解了。

如你所知,JavaScript是世上编程语言的Number One (编者按: 原文如此), 用来编写Web和移动混合应用(比如PhoneGap或者Appcelerator), 也可以编写服务器端的程序(比如NodeJS或者Wakanda),并且拥有很多其他的实现。 它也是很多新手进入编程世界的启蒙语言,因为它不但可以在浏览器上显示一个简单的alert信息,而且还可以用来控制一个机器人(使用nodebot,或者nodruino)。掌握JavaScript并且能够写出规范并性能高效代码的开发人员,已经成为人才市场上的猎寻目标。
在这篇文章中,Saad Mousliki将分享一组JavaScript的技巧、窍门和最佳实践,这些都是JavaScript程序员应该知晓的,不管他们是使用在浏览器/引擎上,还是服务器端(SSJS Service Side JavaScript)JavaScript解释器上。
需要注意的是,这篇文章中的代码片段都在最新的Google Chrome(版本号30)上测试过,它使用V8 JavaScript引擎(V8 3.20.17.15)
Brendan Gregg曾是SUN公司(现已被Oracle收购)的kernal和性能工程师。2010年10月离开Oracle加入Joyent, 2014年成为Netflix公司的高级性能架构师。 Dtrace项目的专家之一, DTraceToolkit的创建者。 现在经常在他的博客上发表一些关于Linux性能的文章。
他专门开了一个页面介绍Linux 性能监控工具, 下图就是他的一副描述Linux监控工具的巨图:
最近在测试系统的Benchmark的时候,遇到一个奇怪的现象: 有少许请求的总处理时间特别长。后来发现耗时基本处在connect to server上。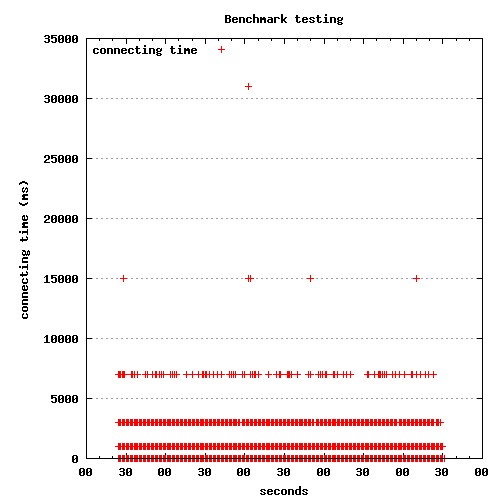
奇怪的是,耗时较长的连接所用的时间基本还有规律, 大概是1秒,3秒,7秒,15秒.....这样有规律的数列,而且耗时越长的连接数量越少。
最近忙于系统性能的DEBUG和调优。 有些性能瓶颈和Linux的TCP/IP的协议栈的设置有关,所以特别google了一下Linux TCP/IP的协议栈的参数意义和配置,记录一下。
如果想永久的保存参数的设置, 可以将参数加入到/etc/sysctl.conf中。如果想临时的更改参数的配置, 可以修改/proc/sys/net/ipv4/下的参数, 机器重启后更改失效。
Apache Beach (ab)是Apache自带的一个性能测试工具,专门用来测试网站的性能, 不仅限于Apache web服务器。
它可以将每个测试数据写入的一个文件中。 格式如下:
|
|
可以使用其它作图工具如gnuplot生成图形。
但是首先,你需要了解每一列的数据代表的意思。

对网站资源进行优化,并使用不同浏览器测试并不是网站设计过程中最有意思的部分,但是这个过程中的很多重复的任务能够使用正确的工具自动完成,从而使效率大大提高,这是让很多开发者觉得有趣的地方。
Gulp是一个构建系统,它能通过自动执行常见任务,比如编译预处理CSS,压缩JavaScript和刷新浏览器,来改进网站开发的过程。通过本文,我们将知道如何使用Gulp来改变开发流程,从而使开发更加快速高效。
Grunt 一直是前端领域构建工具的王者,然而它也不是毫无缺陷的,近期风头正劲的 gulp.js 隐隐有取而代之的态势。那么,究竟是什么使得 gulp.js 备受关注呢? gulp.js 的作者 Eric Schoffstall 在他介绍 gulp.js 的 presentation 中总结了 Grunt 的几点不足之处,请看nightire的翻译和总结。
阮一峰在他的JavaScript 标准参考教程也有专门一节介绍: Gulp:任务自动管理工具 。
还有chenllos的gulp构建进阶供参考。

Java NIO根据操作系统不同, 针对nio中的Selector有不同的实现:
所以毋须特别指定, Oracle jdk会自动选择合适的Selector。 如果想设置特定的Selector,可以属性:
|
|

