Java程序员都知道,Disruptor 是一个高性能的线程间通信的框架,即在同一个JVM进程中的多线程间消息传递,由LMAX开发。
Disruptor性能是如此之高,LMAX利用它可以处理每秒6百万订单,用1微秒的延迟获得吞吐量为100K+。那么Go语言生态圈中有没有这样的库呢?
go-disruptor 就是对Java Disruptor的移植,它也提供了与Java Disruptor类似的API设计,使用起来也算不上麻烦。
至于性能呢,下面就会介绍,这也是本文的重点。
因为Disruptor的高性能, 好多人对它都有所关注, 有一系列的文章介绍Disruptor,比如下列的文章和资源:
也有一些中文的翻译和介绍,比如 并发编程网的Disrutpor专题 。阿里巴巴封仲淹:如何优雅地使用Disruptor 。
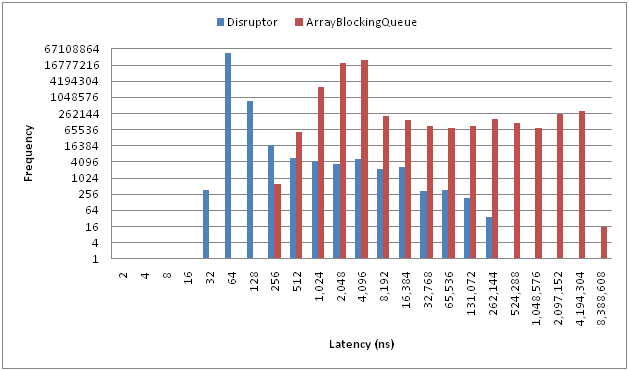
Disruptor由LMAX开发,LMAX目标是要称为世界上最快的交易平台,为了取得低延迟和高吞吐率的目标,它们不得不开发一套高性能的生产者-消费者的消息框架。Java自己的Queue的性能还是有所延迟的,下图就是Disruptor和JDK ArrayBlockingQueue的性能比较。
X轴显示的是延迟时间,Y轴是操作次数。可以看到Disruptor的延迟小,吞吐率高。
Disruptor有多种使用模型和配置,官方的一些模型的测试结果的链接在这里 。
我想做的其实就是go-disruptor和官方的Java Disruptor的性能比较。因为Disruptor有多种配置方式,单生产者和多生产者,单消费者和多消费者,配置的不同性能差别还是蛮大的,所以公平地讲,两者的比较应该使用相同的配置,尽管它们是由不同的编程语言开发的。
我选取的一个测试方案是:3个生产者和一个消费者,如果使用一个生产者Java Disruptor的性能会成倍的提升。
Java Disruptor Java的测试主类如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 public class Main { private static final int NUM_PUBLISHERS = 3 ; private static final int BUFFER_SIZE = 1024 * 64 ; private static final long ITERATIONS = 1000L * 1000L * 20L ; private final ExecutorService executor = Executors.newFixedThreadPool(NUM_PUBLISHERS + 1 , DaemonThreadFactory.INSTANCE); private final CyclicBarrier cyclicBarrier = new CyclicBarrier (NUM_PUBLISHERS + 1 ); private final RingBuffer<ValueEvent> ringBuffer = createMultiProducer(ValueEvent.EVENT_FACTORY, BUFFER_SIZE, new BusySpinWaitStrategy ()); private final SequenceBarrier sequenceBarrier = ringBuffer.newBarrier(); private final ValueAdditionEventHandler handler = new ValueAdditionEventHandler (); private final BatchEventProcessor<ValueEvent> batchEventProcessor = new BatchEventProcessor <>(ringBuffer, sequenceBarrier, handler); private final ValueBatchPublisher[] valuePublishers = new ValueBatchPublisher [NUM_PUBLISHERS]; { for (int i = 0 ; i < NUM_PUBLISHERS; i++) { valuePublishers[i] = new ValueBatchPublisher (cyclicBarrier, ringBuffer, ITERATIONS / NUM_PUBLISHERS, 16 ); } ringBuffer.addGatingSequences(batchEventProcessor.getSequence()); } public long runDisruptorPass () throws Exception { final CountDownLatch latch = new CountDownLatch (1 ); handler.reset(latch, batchEventProcessor.getSequence().get() + ((ITERATIONS / NUM_PUBLISHERS) * NUM_PUBLISHERS)); Future<?>[] futures = new Future [NUM_PUBLISHERS]; for (int i = 0 ; i < NUM_PUBLISHERS; i++) { futures[i] = executor.submit(valuePublishers[i]); } executor.submit(batchEventProcessor); long start = System.currentTimeMillis(); cyclicBarrier.await(); for (int i = 0 ; i < NUM_PUBLISHERS; i++) { futures[i].get(); } latch.await(); long opsPerSecond = (ITERATIONS * 1000L ) / (System.currentTimeMillis() - start); batchEventProcessor.halt(); return opsPerSecond; } public static void main (String[] args) throws Exception { Main m = new Main (); System.out.println("opsPerSecond:" + m.runDisruptorPass()); } }
生产者和消费者类如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public final class ValueAdditionEventHandler implements EventHandler <ValueEvent>{ private long value = 0 ; private long count; private CountDownLatch latch; public long getValue () { return value; } public void reset (final CountDownLatch latch, final long expectedCount) { value = 0 ; this .latch = latch; count = expectedCount; } @Override public void onEvent (final ValueEvent event, final long sequence, final boolean endOfBatch) throws Exception { value = event.getValue(); if (count == sequence) { latch.countDown(); } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public final class ValueBatchPublisher implements Runnable { private final CyclicBarrier cyclicBarrier; private final RingBuffer<ValueEvent> ringBuffer; private final long iterations; private final int batchSize; public ValueBatchPublisher ( final CyclicBarrier cyclicBarrier, final RingBuffer<ValueEvent> ringBuffer, final long iterations, final int batchSize) { this .cyclicBarrier = cyclicBarrier; this .ringBuffer = ringBuffer; this .iterations = iterations; this .batchSize = batchSize; } @Override public void run () { try { cyclicBarrier.await(); for (long i = 0 ; i < iterations; i += batchSize) { long hi = ringBuffer.next(batchSize); long lo = hi - (batchSize - 1 ); for (long l = lo; l <= hi; l++) { ValueEvent event = ringBuffer.get(l); event.setValue(l); } ringBuffer.publish(lo, hi); } } catch (Exception ex) { throw new RuntimeException (ex); } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public final class ValueEvent { private long value; public long getValue () { return value; } public void setValue (final long value) { this .value = value; } public static final EventFactory<ValueEvent> EVENT_FACTORY = new EventFactory <ValueEvent>() { public ValueEvent newInstance () { return new ValueEvent (); } }; }
生产者使用三个线程去写数据,一个消费者进行处理。生产者运行在三个线程中,批处理写入,每次写16个数据。
实际测试每秒能达到 183486238 的吞吐率, 也就是1.8亿的吞吐率。
go-disruptor 下面看看go-disruptor的性能能达到多少。
我们知道,Go语言内置的goroutine之间的消息传递是通过channel实现的,go-disruptor官方网站上比较了go-disruptor和channel的性能,明显go-disruptor要比channel要好:
cenario
Per Operation Time
Channels: Buffered, Blocking, GOMAXPROCS=1
58.6 ns
Channels: Buffered, Blocking, GOMAXPROCS=2
86.6 ns
Channels: Buffered, Blocking, GOMAXPROCS=3, Contended Write
194 ns
Channels: Buffered, Non-blocking, GOMAXPROCS=1
26.4 ns
Channels: Buffered, Non-blocking, GOMAXPROCS=2
29.2 ns
Channels: Buffered, Non-blocking, GOMAXPROCS=3, Contended Write
110 ns
Disruptor: Writer, Reserve One
4.3 ns
Disruptor: Writer, Reserve Many
1.0 ns
Disruptor: Writer, Reserve One, Multiple Readers
4.5 ns
Disruptor: Writer, Reserve Many, Multiple Readers
0.9 ns
Disruptor: Writer, Await One
3.0 ns
Disruptor: Writer, Await Many
0.7 ns
Disruptor: SharedWriter, Reserve One
13.6 ns
Disruptor: SharedWriter, Reserve Many
2.5 ns
Disruptor: SharedWriter, Reserve One, Contended Write
56.9 ns
Disruptor: SharedWriter, Reserve Many, Contended Write
3.1 ns
在与Java Disruptor相同的测试条件下go-disruptor的性能呢?
下面是测试代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 package mainimport ( "fmt" "runtime" "sync" "time" disruptor "github.com/smartystreets/go-disruptor" ) const ( RingBufferSize = 1024 * 64 RingBufferMask = RingBufferSize - 1 ReserveOne = 1 ReserveMany = 16 ReserveManyDelta = ReserveMany - 1 DisruptorCleanup = time.Millisecond * 10 ) var ringBuffer = [RingBufferSize]int64 {}func main () NumPublishers := 3 totalIterations := int64 (1000 * 1000 * 20 ) iterations := totalIterations / int64 (NumPublishers) totalIterations = iterations * int64 (NumPublishers) fmt.Printf("Total: %d, Iterations: %d, Publisher: %d, Consumer: 1\n" , totalIterations, iterations, NumPublishers) runtime.GOMAXPROCS(NumPublishers) var consumer = &countConsumer{TotalIterations: totalIterations, Count: 0 } consumer.WG.Add(1 ) controller := disruptor.Configure(RingBufferSize).WithConsumerGroup(consumer).BuildShared() controller.Start() defer controller.Stop() var wg sync.WaitGroup wg.Add(NumPublishers + 1 ) var sendWG sync.WaitGroup sendWG.Add(NumPublishers) for i := 0 ; i < NumPublishers; i++ { go func () writer := controller.Writer() wg.Done() wg.Wait() current := disruptor.InitialSequenceValue for current < totalIterations { current = writer.Reserve(ReserveMany) for j := current - ReserveMany + 1 ; j <= current; j++ { ringBuffer[j&RingBufferMask] = j } writer.Commit(current-ReserveMany, current) } sendWG.Done() }() } wg.Done() t := time.Now().UnixNano() wg.Wait() fmt.Println("start to publish" ) sendWG.Wait() fmt.Println("Finished to publish" ) consumer.WG.Wait() fmt.Println("Finished to consume" ) t = (time.Now().UnixNano() - t) / 1000000 fmt.Printf("opsPerSecond: %d\n" , totalIterations*1000 /t) } type countConsumer struct { Count int64 TotalIterations int64 WG sync.WaitGroup } func (cc *countConsumer) int64 ) { for lower <= upper { message := ringBuffer[lower&RingBufferMask] if message != lower { warning := fmt.Sprintf("\nRace condition--Sequence: %d, Message: %d\n" , lower, message) fmt.Printf(warning) panic (warning) } lower++ cc.Count++ if cc.Count == cc.TotalIterations { cc.WG.Done() return } } }
实际测试go-disruptor的每秒的吞吐率达到137931020 。
好了,至少我们在相同的测试case情况下得到了两组数据,另外我还做了相同case情况的go channel的测试,所以一共三组数据:
Java Disruptor : 183486238 ops/s
go-disruptor : 137931020 ops/s
go channel : 6995452 ops/s
可以看到go-disruptor的性能要略微低于Java Disruptor,但是也已经足够高了,达到1.4亿/秒,所以它还是值的我们关注的。go channel的性能远远不如前两者。
Go Channel 如果通过Go Channel实现,每秒的吞吐率为 6995452。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 func main () NumPublishers := 3 totalIterations := int64 (1000 * 1000 * 20 ) iterations := totalIterations / int64 (NumPublishers) totalIterations = iterations * int64 (NumPublishers) channel := make (chan int64 , 1024 *64 ) var wg sync.WaitGroup wg.Add(NumPublishers + 1 ) var readerWG sync.WaitGroup readerWG.Add(1 ) for i := 0 ; i < NumPublishers; i++ { go func () wg.Done() wg.Wait() for i := int64 (0 ); i < iterations; { select { case channel <- i: i++ default : continue } } }() } go func () for i := int64 (0 ); i < totalIterations; i++ { select { case msg := <-channel: if NumPublishers == 1 && msg != i { } default : continue } } readerWG.Done() }() wg.Done() t := time.Now().UnixNano() wg.Wait() readerWG.Wait() t = (time.Now().UnixNano() - t) / 1000000 fmt.Printf("opsPerSecond: %d\n" , totalIterations*1000 /t) }