距离上一次2021年Go生态圈rpc框架benchmark的测试整整一年了。一年来,各个RPC框架也获得长足的进展,rpcx也在众多网友的支持下做了一些有益的优化和精简,所以是时候再做一次国内几个常用框架的性能比较了。
每次性能结果的发布,必然引来众多的人的注目,也引来更多的争议。这是很正常的。一个benchmark不代表评价一个框架的优劣,一个benchmakr测试也不足以代表测试所有的应用场景。在不同的业务形态下、巨大的连接数差别、消息的格式不同、消息大小的不同、部署环境的不同都可能导致某些场景下某个框架的结果比较好,某个框架的结果比较差。我们将讨论和焦点放在还有哪些可以性能提升的点上即可。某个框架的优化点或许能够其它框架带来一些优化的提示。
另外,在实际使用微服务框架的时候,大部分的性能瓶颈在于业务代码,而不是框架本身,所以重点优化业务代码也非常的重要。
本文测试的不同框架底层传输的协议是不同,比如grpc是通过HTTP2.0,kitex支持TTHeader、HTTP2等协议,arpc使用自研的协议,rpcx使用自研的协议,标准库rpc使用自研的协议。
测试的消息体编解码采用统一的protobuf。
YangruiEmma 指出测试公平性的修正建议, kitex采用的protobuf生成是官方的方式,但是其它几个框架采用的是gogo/protobuf,性能上会有所不同。这是一个问题,因为kitex创建pb代码的时候配合使用的是官方的pb库。不过字节的同学说采用自研的protobuf库,会更快
本测试并未记录CPU和内存的消耗。这是一个缺陷。 因为CPU和内存会一直变化,没太想好如何科学的记录测试时的CPU和内存使用值。
本次测试针对五种常见的rpc框架进行了测试:
- rpcx, 最早的Go生态圈微服务框架之一,被新浪、好未来等公司使用
- kitex, 字节跳动出品的微服务框架
- arpc: 一个性能优异的rpc框架 by lesismal
- grpc: Google发起的一个开源rpc框架,支持跨语言,使用广泛。该系统基于HTTP/2 协议传输,使用Protocol Buffers 作为接口描述语言。
- 标准库的rpc/std_rpc: Go标准库自带的rpc框架,目前处于维护状态
测试采用了各框架的最新版本:
- rpcx: v1.7.8
- kitex: v0.3.4
- arpc: v1.2.9
- grpc: v1.48.0
- std_rpc: v1.8.4
为了尽量保持一致性的测试,所有的测试都是在相同的测试环境下,相同的测试逻辑,相同的测试消息进行的:
- 测试环境(已经服役6年的老机器,两台,一台做server,一台做client)
- CPU型号: Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz / 2颗
- 物理核: 6个; 逻辑核: 12核
- 内存: 64G
- 开启网卡多队列
- 都采用protobuf作为消息体的编码方式,编码后的消息体大小为581个字节
- 在客户端统计,统计吞吐量(throughputs)和延迟(lantency, 包括最大值,平均值,中位数值,和p99.9的值, 最小值都小于1毫秒,所以未统计)
- 对于延迟,我们还需要关注它的长尾情况,所以需要关注中位数和p99.9。p99.9指千分之999的请求的延迟都小于某个时间。
主要分为三个场景进行测试。
- TCP连接数为10, 长连接。并发数为100、200、500、1000、2000、5000的情况
主要测试高并发的情况下各框架最大的能力,包括吞吐量和延迟。 - TCP连接数为10,并发数为200,长连接。 吞吐量为10万/秒、15万/秒、18万/秒的情况下的延迟
主要测在吞吐保持一致的情况下,各个框架的延迟情况和长尾情况。延迟或长尾太大意味着使用这个吞吐率是不合适。 - TCP连接数为1000,并发数为1000,长连接。
主要测试大连接数比较高的情况下各框架的性能。主要是想针对字节的kitex这种自研的netpoll,看看是否更适合这种大量连接数的情况。
这里并发数是指客户端启动的goroutine数量,多个goroutine可能共享同一个client(连接)。
所有的各框架的测试代码都放在了rpcx-benchmark。测试的命令非常简单,如下面的介绍中所示,所以你可以下载下来自己测试验证,也欢迎提供优化补丁,补充更多的rpc框架等等。
场景一: TCP连接数为10, 长连接。并发数为100、200、500、1000、2000、5000的情况
- 服务端启动:
./server -s xxx.xxx.xxx.xxx:8972// xxx.xxx.xxx.xxx是服务端监听的IP地址 - 客户端测试:
./client -c 2000 -n 1000000 -s xxx.xxx.xxx.xxx:8972// 这里的并发数是2000, 测试总共发送1百万个请求
测试原始数据:
吞吐量
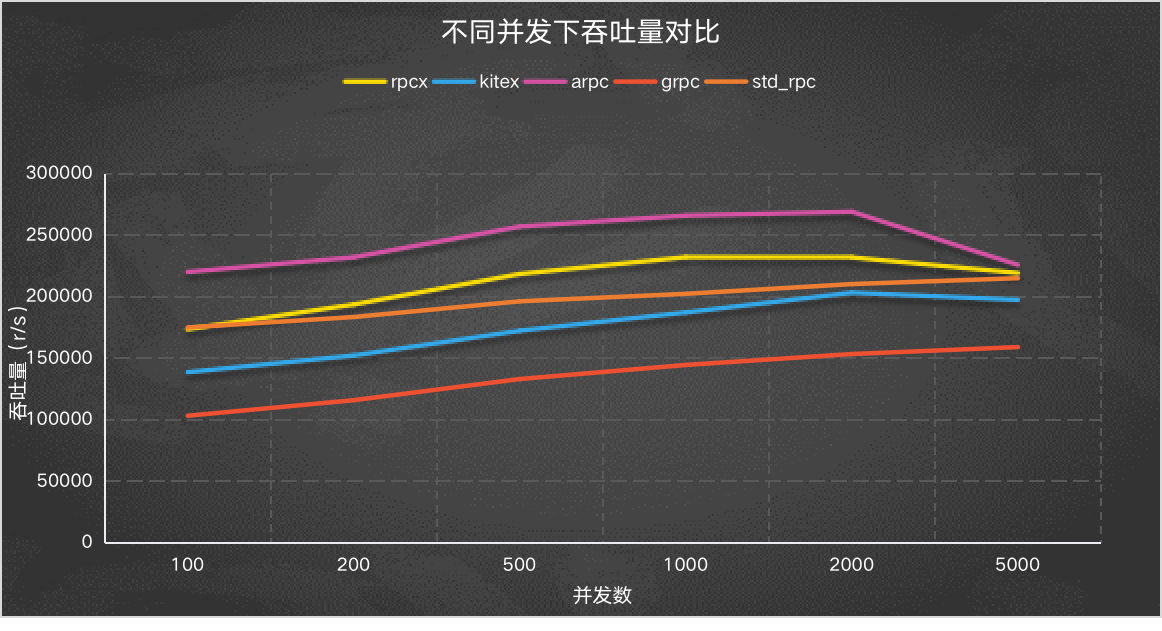
Y轴是吞吐量/秒,越高越好。可以看到arpc框架吞吐非常的好,去年的测试也是arpc表现比较好,其次是rpcx、标准的rpc、kitex、grpc。
可以看到在并发量比较大的情况下,除了grpc, 其它都能达到18万个请求/秒的吞吐量。
平均延迟
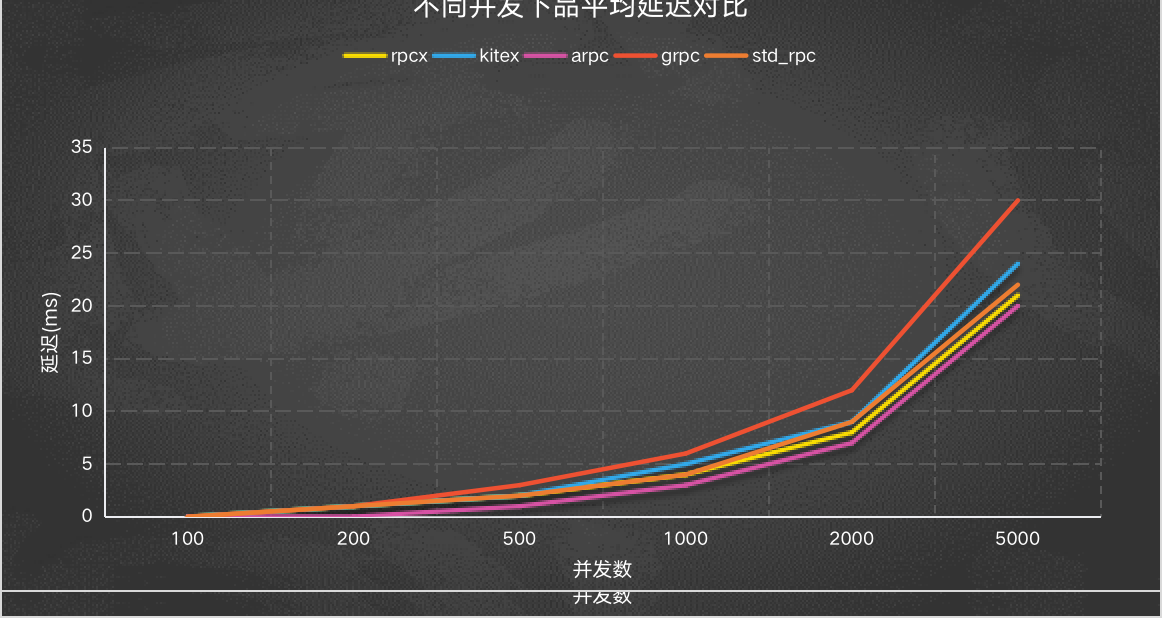
Y轴是平均延迟,越低越好,可以看到grpc的延迟较高。延迟正好和上面的吞吐量相反。
P99.9 延迟
另外一个我们可能比较关注长尾的情况,可以选取中位数或者p99.9观察。 下面是p99.9的情况。
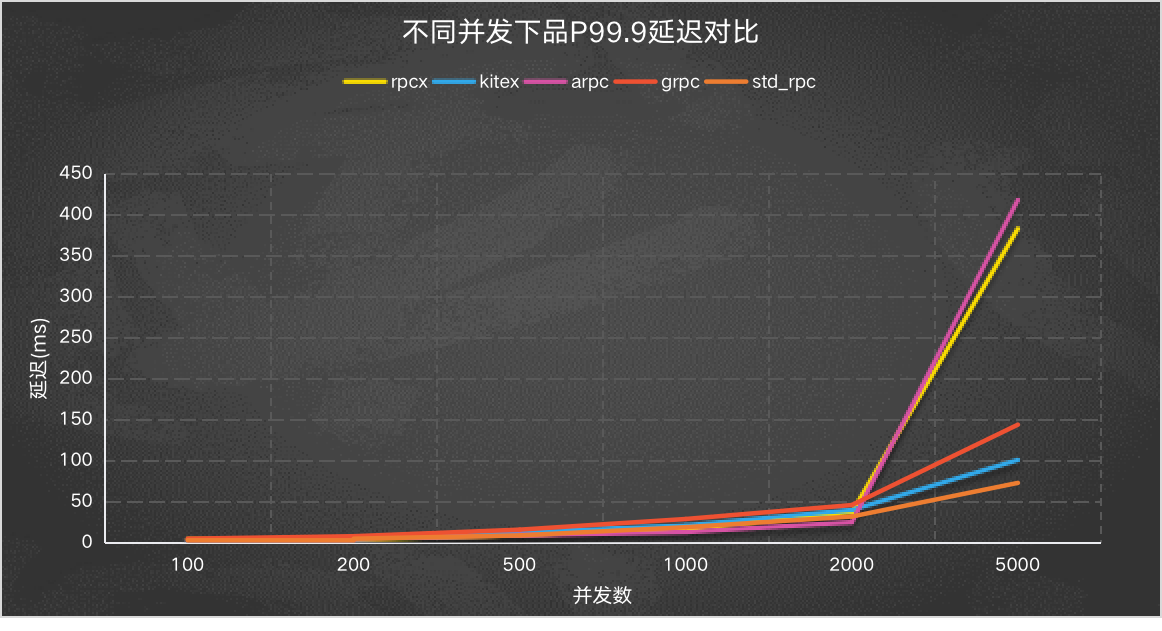
当然,并发数为5000的情况下比较是无意义的,因为在并发数为5000的情况下,各框架的吞吐量是不一样的,在吞吐量高的情况下延迟也会大。
所以为了在公平的情况下观察长尾情况,我设计了下面的测试。
场景二: TCP连接数为10,并发数为200,长连接。 吞吐量为10万/秒、15万/秒、18万/秒的情况下的延迟
为了观察延迟,我们需要保证吞吐量都尽量一样,在相同的吞吐量情况下观察延迟和长尾情况更科学。
所以场景二就是在并发数为200的情况下,针对吞吐量为10万/秒、15万/秒、18万/秒三个场景,观察框架的延迟和P99.9延迟。
测试原始数据:
平均延迟
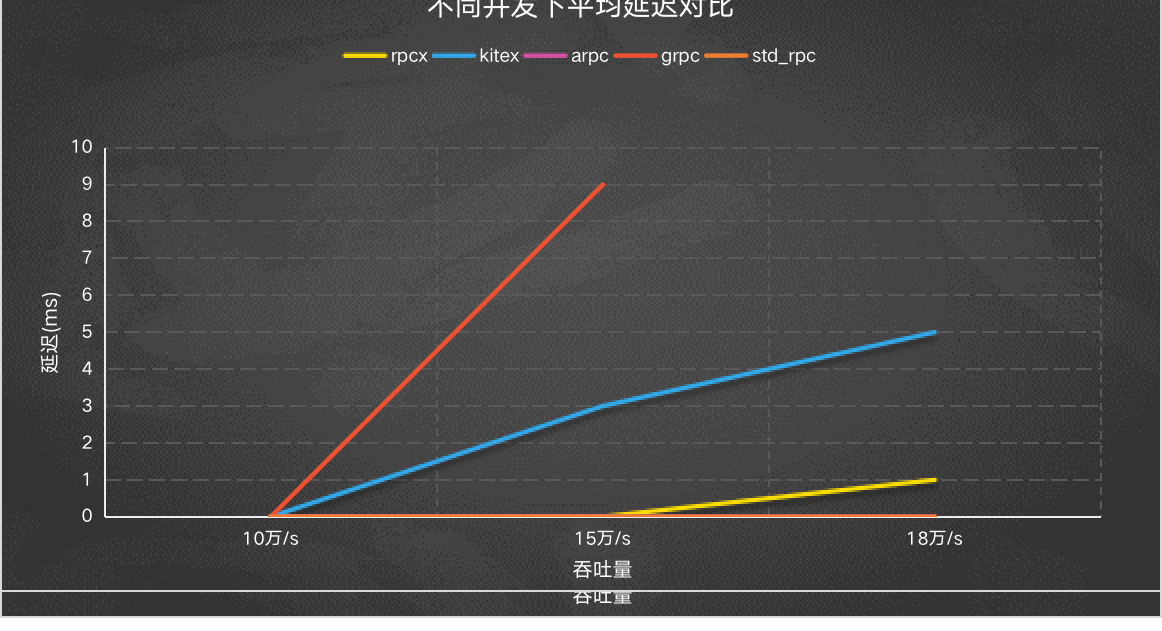
平均延迟看起来grpc比较高,因为它达不到18万/秒的吞吐,所以它的最后一个数值是没有的。kitex相对较高,这个还得具体看是不是kitex有一些具体的调优。 基本上是和吞吐量成负相关的。
P99.9 延迟
长尾的情况,下面是p99.9的情况。
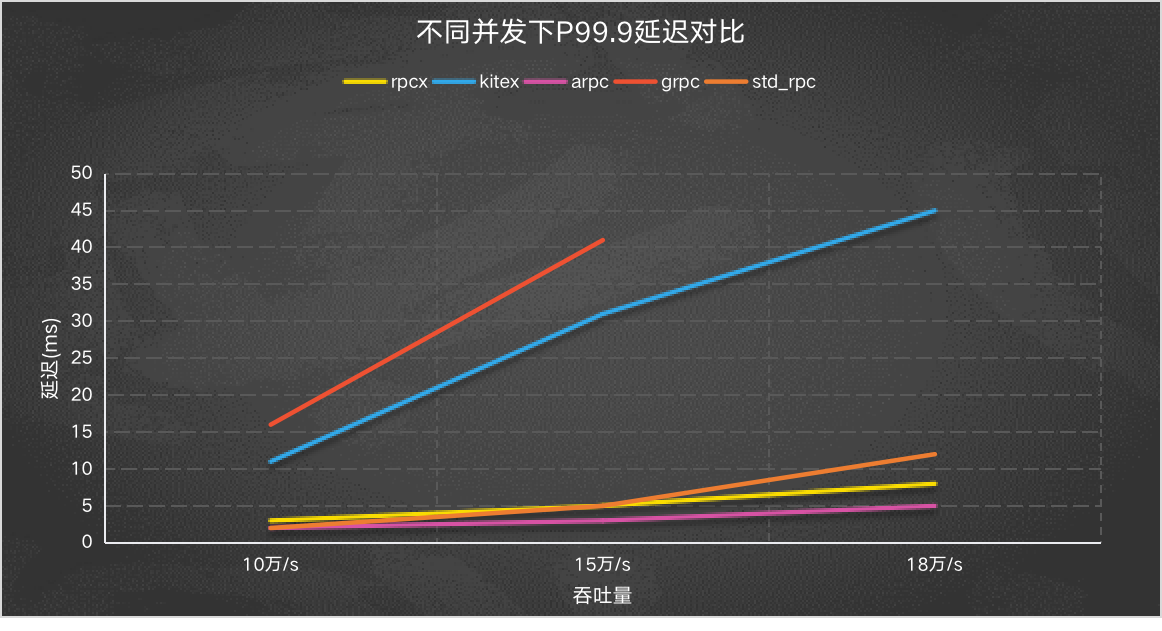
arpc、rpcx和标准rpc的P99.9延迟还是比较好的。
场景三: TCP连接数为1000,并发数为1000,长连接。
观察在大量连接情况下各框架的表现(吞吐率和延迟)。这个场景并没有选择巨量的连接数,而是选择了一个较常见的1000的连接数做测试,连接为长连接。
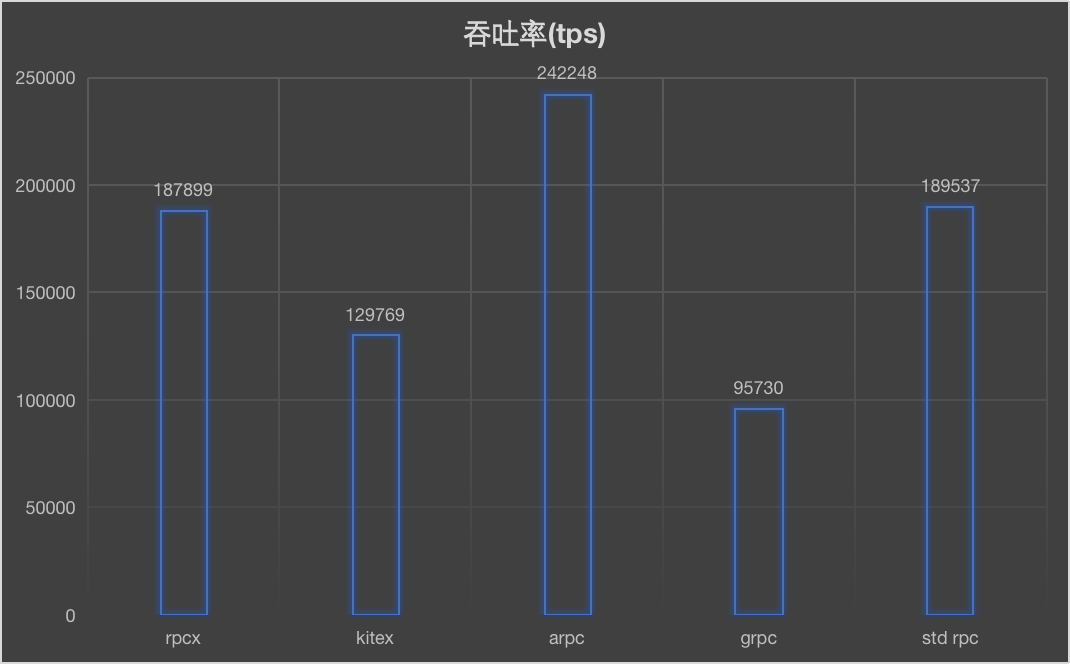
arpc在连接数比较多的情况下明显要好于其它框架,其次就是rpcx和标准rpc框架。
平均耗时和P99.9耗时也符合这个情况,具体原始数据参考
总体来看,rpcx的性能还是不错的,希望在以后的日子,参考兄弟rpc框架,做进一步的优化。
欢迎在本文留言区进行探讨。
