问题概述
在分布式系统中,宕机是需要考虑的重要组成部分。日志技术是宕机恢复的重要技术之一。日志技术应用广泛,早些更是广泛应用在数据库设计实现中。本文先介绍基本原理概念,最后通过redis介绍生产环境中的实现方法。
Redo Log
数据库设计中,需要满足ACID,尤其是在支持事务的系统中。当系统遇到未知错误时,可以恢复到一个稳定可靠的状态。有一个很简单的思路,就是记录所有对数据库的写操作日志。那么一旦发生故障,即使丢失掉内存中所有数据,当下一次启动时,通过复现已经记录的数据库写操作日志,依然可以回到故障之前的状态(如果在写操作作日志的时候发生故障,那么这次数据库操作失败)。
操作流程简单如下(假设每次数据变化,都提交):
- 更新的操作方式依次记录到磁盘日志文件。
- 更新内存中的数据。
- 返回更新成功结果。
恢复流程:
- 读取日志文件,依次修改内存中的数据。
优点:
- 日志文件有序,可以通过append的方式写入磁盘,性能很高。
- 简单可靠,应用广泛。可以把内存中的数据,做备份在磁盘中。
缺点:
- 使用时间一长,恢复宕机的时间很慢。
解决办法
先具体化下,如果我们内存中保留一个a的值,记录了写操作比如 a = 4; a++; a--; 当这些操作上千万、亿之后,恢复非常慢。甚至可能最后一条就是a=0,按照之前的算法,我们却跑了很长时间。
那么根据这个场景,很容易想到一个解决方案。
操作流程:
- 日志文件记录
begin check point - 在某个时刻,把内存中的数值,直接snapshot或dump到磁盘上。(比如直接记录a=4)
- 日志文件记录
end check point
恢复流程:
- 扫描日志文件,找到最后的
end check point中配对的begin check point。 - 读入dump文件。
- 依次回放记录的日志操作。
优点:
- 应用广泛,包括 mysql,oracle。
一些棘手的问题:
- 在做snapshot的时候,往往不能停止数据库的服务,那么很可能记录了
begin check point之后的日志。那么在重新load begin checkpoint之后的日志时,最后恢复的数据很有可能不对。比如我们记录的是a++这样的日志, 那么重复一条日志,就会让a的值加1。反之如果我们记录是幂等的,比如一直是 a=5 这种操作,那么就对最后结果没有影响。很显然,设计幂等操作系统很麻烦。 - 设计一个支持snapshot的内存数据结构,也比较麻烦。
典型的是通过copy-on-write机制。和操作系统中的概念一样。当这个数据结构被修改,就创建一份真正的copy。老数据增加一份dirty flag。如果没有修改就继续使用之前的内存。这样在做snapshot的时候,保证我们的dump数据是begin check point这个时刻的数据。显然这个也比较麻烦。
还有一种支持snapshot的思路是begin check point后,不动老的数据。内存中的数据在新的地方,日志也写在新的地方。最后在end check point做一次merge。这个实现起来简单,但是内存消耗不小。
Redis是如何解决日志问题的
Redis 是一个基于内存的database,不同于memcached,他支持持久化。另外由于redis处理client request 和 response 都是在一个thread里面,也没有抢占式的调度系统,核心业务都是按照event loop顺序执行,而磁盘写日志又开销很大,所以redis实现日志功能做了很多优化。并且提供2种持久化方案。我们需要在不同的场景下,采用不同的方式配置。
snapshotting
某个时刻,redis会把内存中的所有数据snapshot到磁盘文件。更通俗的说法是fork一个child process,把内存中的数据序列化到临时文件,然后在main event loop 中原子的更换文件名。redis,利用了操作系统VM的copy-on-write机制,在不阻塞主线程的情况下,利用子进程和父进程共享的data segment实现snapshot。具体是代码实现在rdb.c, function at rdbSaveBackground
优点:
- 简单可靠,如果database 不大,执行的效果非常好。
缺点:
- 如果database size 很大,每一次snapshot时间非常长。不得不配置大的间隔,提高了宕机时数据丢失的风险。
为了解决上面的问题,redis增加了AOF。
Append Only File(AOF)
在database术语中,也被叫做WAL。如果开启的AOF的配置,redis会记录所有写操作到日志文件中。那么redis同样会遇到之前我们提到过的问题。
- 即便是追加写,磁盘的操作依然比内存慢好几个数量级,频繁的操作容易产生瓶颈。
- 如果数据量操作频繁,会产生大量的重复日志数据,导致恢复时间太长。比如记录一条微博的浏览量,会记录大量重复的
+1日志。
那么redis是如何解决的呢?
- 文件写操作消耗的时间很长,redis会先把记录日志写在内存buffer中,在每一次event loop 结束之后,根据配置判断是否做写操作。每个buffer的大小有限制,这样每次写操作时间不会太长。
- 即便是调用write操作,OS并没有立即写入磁盘,redis 同样提供了一些方案决定刷新OS IO buffer的时机(1秒、从不、每次)。
- redis 提供一种AOF重写的方式
rewriteAppendOnlyFile来处理AOF文件过大情况。
前面我们知道了,这种check point的机制还是比较麻烦的。那么redis是这么设计的。
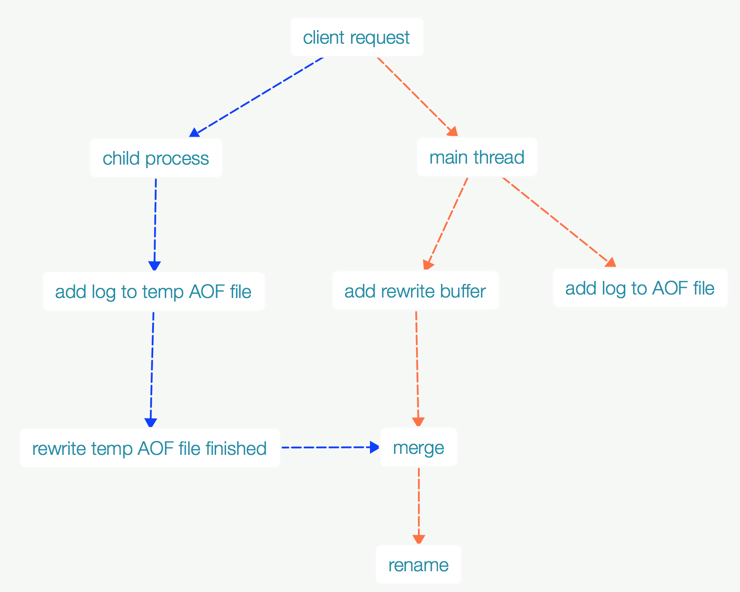
- 为了避免加锁,redis 依然创建了一个child process,利用VM的copy-on-write,共享数据。同时保证主线程依然可以处理client请求。
- 根据KV的类型,先从内存读取数据,然后再写数据到磁盘,和之前的AOF文件无关。
- 那么当子进程rewrite AOF的过程中,main thread依然可以处理新的client request。新增的数据会被放在rewrite buffer中,而且写到原有的AOF文件中。
- child process完成后会通知主线程。主线程有一个定时任务,也就是会不断轮询child process是否已经完成(通过信号量)。
- 主线程会merge 变化的数据到temp file。
- 主线程原子的rename到一个新的AOF文件,之前的AOF就不起作用了。
优点:
- 除了merge 和 rename需要阻塞主线程,rewrite不会阻塞主线程。(前提是使用bgrewrite command)。
最后
这些都是性能和稳定性之间做的权衡,根据不同场景需要调整。
