原文: Faster time parsing , 可以学习一下作者优化程序的方法。
在Ravelin ,我们大量的数据都携带时间戳(timestamp)。大部分时间戳都以字符串形式存储在BigQuery中,而我们的大多数Go结构都使用Go time.Time类型表示时间。
很遗憾这就是我们的现实情况。我们真的有很多很多数据,所以我们真的有很多很多时间戳。一段时间以来,我总结出一个结论,随着时间的推移,我确信这个结论是正确的:
Friends don’t let friends represent time in databases as strings. 真心是哥们的话就不要在数据库把时间表示成字符串类型
不管咋地,自己的苦还得自己咽下去,既然我们已经这么设计了,我们还得坚持下去,但这不意味着我们破罐子破摔了,我们可以尽力而为。对于我来说,现在做得最好的方案就是找到一种比time.Parse 更快的方法解析 RFC3339 格式的时间戳。
事实证明这很容易。time.Parse 有两个参数:一个描述要解析的数据格式(特殊字符串),另一个是需要解析的数据字符串。format参数不只是选择合适的格式。format参数描述应如何解析数据。time.Parse 不仅解析时间,还必须解析、理解和实现一种解析时间的描述。如果我们编写一个只是解析RFC3339的专用解析函数,它应该会比time.Parse 更快。
但是在动手之前,让我们先写一个快速的基准测试,看看time.Parse 有多快:
1
2
3
4
5
6
7
8
9
func BenchmarkParseRFC3339(b *testing.B) {
now := time.Now().UTC().Format(time.RFC3339Nano)
for i := 0 ; i < b.N; i++ {
if _, err := time.Parse(time.RFC3339, now); err != nil {
b.Fatal(err)
}
}
}
下面数据是测试的结果:
1
2
name time /op
ParseRFC3339-16 150 ns ± 1 %
接下来我们开始写自己专用的 RFC3339 解析函数。它索然无味,而且也不漂亮,但是至少它可以工作。
(它真的很长且不漂亮,所以与其把它包含在这篇文章中,让大家滚动过去,不如这里有一个链接 ,指向最终版本,并应用下面讨论的所有优化。如果你想象一个很长的函数,调用strconv.Atoi 的次数很多,你就会明白这一点)
我们使用基础测试代码测试新的解析函数,我们得到下面的结果:
1
2
name old time /op new time /op delta
ParseRFC3339-16 150 ns ± 1 % 45 ns ± 4 % -70.15 % (p=0.000 n=7 +8 )
相比较而言,新的函数真的很快。完美,结束。
等等, 还未结束
如果我们采样 CPU profile ,我们观察到很多时间都花费在调用strconv.Atoi 上。
1
2
3
4
5
6
7
8
9
10
11
12
13
> go test -run ^$ -bench BenchmarkParseRFC3339 -cpuprofile cpu.prof
> go tool pprof cpu.prof
Type : cpu
Time : Oct 1 , 2021 at 7 :19 pm (BST)
Duration: 1.22 s, Total samples = 960 ms (78.50 %)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 950 ms, 98.96 % of 960 ms total
Showing top 10 nodes out of 24
flat flat% sum% cum cum%
380 ms 39.58 % 39.58 % 380 ms 39.58 % strconv.Atoi
370 ms 38.54 % 78.12 % 920 ms 95.83 % github.com/philpearl/blog/content/post.parseTime
60 ms 6.25 % 84.38 % 170 ms 17.71 % time .Date
strconv.Atoi 转换ASCII字符到整数类型。这是Go标准库的基础实现,所以它一定是经过了很好的编码和优化,所以我们不能优化它吗?
未必,我们的大部分数字正好有2个字节长,或者正好有4个字节长。我们可以编写数字解析函数,针对我们的特殊情况做优化,不需要任何令人讨厌的慢循环:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
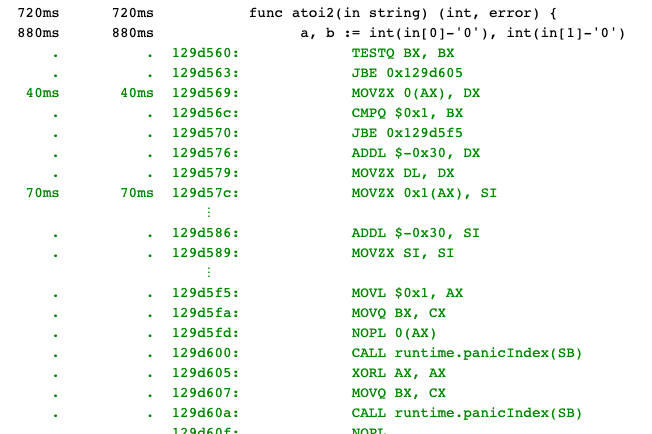
func atoi2(in string ) (int , error) {
a, b := int (in[0 ]-'0' ), int (in[1 ]-'0' )
if a < 0 || a > 9 || b < 0 || b > 9 {
return 0 , fmt.Errorf("can't parse number %q" , in)
}
return a*10 + b, nil
}
func atoi4(in string ) (int , error) {
a, b, c, d := int (in[0 ]-'0' ), int (in[1 ]-'0' ), int (in[2 ]-'0' ), int (in[3 ]-'0' )
if a < 0 || a > 9 || b < 0 || b > 9 || c < 0 || c > 9 || d < 0 || d > 9 {
return 0 , fmt.Errorf("can't parse number %q" , in)
}
return a*1000 + b*100 + c*10 + d, nil
}
如果再运行我们的基准测试,可以看到我们又做了一次更深入的性能提升。
1
2
name old time /op new time /op delta
ParseRFC3339-16 44.9 ns ± 4 % 39.7 ns ± 3 % -11.51 % (p=0.000 n=8 +8 )
好了,我们现在不仅写了一个定制的时间解析器,而且还实现了定制的数字解析器。非常完美,结束。
等等, 当然还未结束
啊哈,让我们在看一眼现在的CPU profile, 并且看一些汇编代码。在atoi2 中有两个slice长度检查(下面绿色的汇编代码,调用panicIndex之前),不是有一个边界检查的技巧 吗?
以下是根据此技巧进行修正后的代码。函数开始处的_ = in[1] 给了编译器充足的提示,这样我们在调用它的时候不用每次都检查是否溢出了:
1
2
3
4
5
6
7
8
func atoi2(in string ) (int , error) {
_ = in[1 ]
a, b := int (in[0 ]-'0' ), int (in[1 ]-'0' )
if a < 0 || a > 9 || b < 0 || b > 9 {
return 0 , fmt.Errorf("can't parse number %q" , in)
}
return a*10 + b, nil
}
虽然是一点小小的改变,但也带来明显的改变:
1
2
name old time /op new time /op delta
ParseRFC3339-16 39.7 ns ± 3 % 38.4 ns ± 2 % -3.26 % (p=0.001 n=8 +7 )
atoi2 非常短。为什么它不被内联的?如果我们简化错误处理,是不是有效果?如果我们删除对fmt.Errorf 的调用,并将其替换为一个简单的错误类型,这将降低atoi2 函数的复杂性。这可能足以让Go编译器决定不作为单独的代码块而是直接在调用函数中内联这个函数。
1
2
3
4
5
6
7
8
9
10
var errNotNumber = errors.New("not a valid number" )
func atoi2(in string ) (int , error) {
_ = in[1 ]
a, b := int (in[0 ]-'0' ), int (in[1 ]-'0' )
if a < 0 || a > 9 || b < 0 || b > 9 {
return 0 , errNotNumber
}
return a*10 + b, nil
}
这是最终的形态,基准测试结果有了显著的提升。
1
2
name old time /op new time /op delta
ParseRFC3339-16 38.4 ns ± 2 % 32.9 ns ± 5 % -14.39 % (p=0.000 n=7 +8 )
我们的优化故事真的就此结束了。为了优化120纳秒的时间我们做了大量的工作。必看120纳秒很小,加起来却对程序提升不少,这些优化将Ravelin的一些机器学习特征提取管道组件的运行时间减少了一个小时甚至更多。如我前面所说,我们真的有很多很多的数据和时间戳。