在使用Go语言的过程中,无论你是实现web应用程序,还是控制台输入输出,又或者是网络操作,不可避免的会遇到IO操作,使用到io.Reader和io.Writer接口。也也许对这两个接口和相关的一些接口很熟悉了,但是你脑海里确很难形成一个对io接口的继承关系整天的概貌,原因在于godoc缺省并没有像javadoc一样显示官方库继承关系,这导致了我们对io接口的继承关系记忆不深,在使用的时候还经常需要翻文档加深记忆。本文试图梳理清楚Go io接口的继承关系,提供一个io接口的全貌。
[译]Java火焰图
在我的前一天转的一篇文章中([转]go's march to low latency gc),Twitch的Rhys Hiltner使用火焰图(FlameGraph)来分析Go程序的性能给我留下了深刻的印象,它使用Brendan Gregg创建的火焰图工具生成直观的图像,很方便的分析Go的各个方法占用的CPU的时间。
因为我的一部分时间还是使用Java开发,所以就想到有没有Java相关的工具生成火焰图呢?答案当然是肯定的,而且它更早的应用于Java程序的性能分析。
火焰图工具的作者Brendan Gregg专门写了一篇文章:Java Flame Graphs,介绍如何生成火焰图的。这就是本文要翻译的文章。
Netflix深度使用了火焰图工具,他们专门写了一篇文章Java in Flames,介绍他们是如何使用的,而且前段时间他们又写了一篇文章: 如何使用火焰图分析性能,每天为Netflix节省一千三百万分钟的计算时间,文中介绍了他们如何使用火焰题找到耗时的问题所在,为公司节省了大量的时间和金钱。(Brendan Gregg就是Netflix的员工,他的站点觉得是一个值得阅读的地方,还有很多其它性能相关的专题,比如Linux性能工具 http://www.brendangregg.com/linuxperf.html)
既然火焰图这么有效,你难道不想了解一下吗?
以下是Brendan Gregg文章的翻译。

继续了解Java的纤程库 - Quasar
前一篇文章Java中的纤程库 - Quasar中我做了简单的介绍,现在进一步介绍这个纤程库。
Quasar还没有得到广泛的应用,搜寻整个github也就pinterest/quasar-thrift这么一个像样的使用Quasar的库,。并且官方的文档也很简陋,很多地方并没有详细的介绍,和Maven的集成也不是很好。这些都限制了Quasar的进一步发展。
但是,作为目前最好用的Java coroutine的实现,它在某些情况下的性能还是表现相当出色的,希望这个项目能够得到更大的支持和快速发展。
因为Quasar文档的缺乏,所以使用起来需要不断的摸索和在论坛上搜索答案,本文将一些记录了我在Quasar使用过程中的一些探索。
[转]列出所有的Maven依赖
转发一个脚本,以列表形式显示maven中的依赖。
原文: List all your Maven dependencies
1 | # first grab all dependencies |
输出结果如下所示:
1 | asm:asm:jar:1.5.3 |
理解RxJava的线程模型
ReactiveX是Reactive Extensions的缩写,一般简写为Rx,最初是LINQ的一个扩展,由微软的架构师Erik Meijer领导的团队开发,在2012年11月开源,Rx是一个编程模型,目标是提供一致的编程接口,帮助开发者更方便的处理异步数据流,Rx库支持.NET、JavaScript和C++,Rx近几年越来越流行了,现在已经支持几乎全部的流行编程语言了,Rx的大部分语言库由ReactiveX这个组织负责维护,比较流行的有RxJava/RxJS/Rx.NET,社区网站是 reactivex.io。
Netflix参考微软的Reactive Extensions创建了Java的实现RxJava,主要是为了简化服务器端的并发。2013年二月份,Ben Christensen 和 Jafar Husain发在Netflix技术博客的一篇文章第一次向世界展示了RxJava。
RxJava也在Android开发中得到广泛的应用。
ReactiveX
An API for asynchronous programming with observable streams.
A combination of the best ideas from the Observer pattern, the Iterator pattern, and functional programming.
虽然RxJava是为异步编程实现的库,但是如果不清楚它的使用,或者错误地使用了它的线程调度,反而不能很好的利用它的异步编程提到系统的处理速度。本文通过实例演示错误的RxJava的使用,解释RxJava的线程调度模型,主要介绍Scheduler、observeOn和subscribeOn的使用。
Java中的纤程库 - Quasar
最近遇到的一个问题大概是微服务架构中经常会遇到的一个问题:
服务 A 是我们开发的系统,它的业务需要调用 B、C、D 等多个服务,这些服务是通过http的访问提供的。 问题是 B、C、D 这些服务都是第三方提供的,不能保证它们的响应时间,快的话十几毫秒,慢的话甚至1秒多,所以这些服务的Latency比较长。幸运地是这些服务都是集群部署的,容错率和并发支持都比较高,所以不担心它们的并发性能,唯一不爽的就是就是它们的Latency太高了。
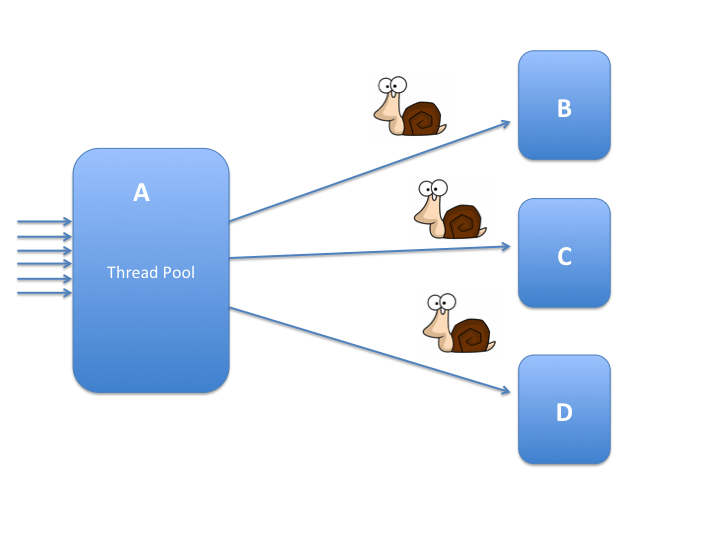
系统A会从Client接收Request, 每个Request的处理都需要多次调用B、C、D的服务,所以完成一个Request可能需要1到2秒的时间。为了让A能更好地支持并发数,系统中使用线程池处理这些Request。当然这是一个非常简化的模型,实际的业务处理比较复杂。
可以预见,因为系统B、C、D的延迟,导致整个业务处理都很慢,即使使用线程池,但是每个线程还是会阻塞在B、C、D的调用上,导致I/O阻塞了这些线程, CPU利用率相对来说不是那么高。
当然在测试的时候使用的是B、C、D的模拟器,没有预想到它们的响应是那么慢,因此测试数据的结果还不错,吞吐率还可以,但是在实际环境中问题就暴露出来了。
[转]使用Nginx 和 RTMP 模块搭建视频直播系统
原文: Setting Up Adaptive Streaming with Nginx by Licson。
最近我在为一个组织搭建视频直播系统。对于视频直播来说我是新手,经过一番调研,最终还是觉得Nginx + RTMP module是一个好的选择。
搭建这个系统还是很困难的。经过了好几天的测试和摸索,我得到了一种比较好的配置,值得给大家分享。

