
Kafka为broker,producer和consumer提供了很多的配置参数。 了解并理解这些配置参数对于我们使用kafka是非常重要的。
本文列出了一些重要的配置参数。
官方的文档 Configuration比较老了,很多参数有所变动, 有些名字也有所改变。我在整理的过程中根据0.8.2的代码也做了修正。
Kafka为broker,producer和consumer提供了很多的配置参数。 了解并理解这些配置参数对于我们使用kafka是非常重要的。
本文列出了一些重要的配置参数。
官方的文档 Configuration比较老了,很多参数有所变动, 有些名字也有所改变。我在整理的过程中根据0.8.2的代码也做了修正。
当你编写kafka Producer时, 会生成KeyedMessage对象。
1 | KeyedMessage<K, V> keyedMessage = new KeyedMessage<>(topicName, key, message) |
这里的key值可以为空,在这种情况下, kafka会将这个消息发送到哪个分区上呢?依据Kafka官方的文档, 默认的分区类会随机挑选一个分区:
The third property "partitioner.class" defines what class to use to determine which Partition in the Topic the message is to be sent to. This is optional, but for any non-trivial implementation you are going to want to implement a partitioning scheme. More about the implementation of this class later. If you include a value for the key but haven't defined a partitioner.class Kafka will use the default partitioner. If the key is null, then the Producer will assign the message to a random Partition.
但是这句话相当的误导人。
编译自官方文档
Apache Kafka是一个分布式消息发布订阅系统。它最初由LinkedIn公司基于独特的设计实现为一个分布式的提交日志系统( a distributed commit log),,之后成为Apache项目的一部分。Kafka系统快速、可扩展并且可持久化。它的分区特性,可复制和可容错都是其不错的特性。
Apache Kafka与传统消息系统相比,有以下不同:
First let's review some basic messaging terminology:
首先来了解一下Kafka所使用的基本术语:
听起来和JMS消息处理差不多?
让我们站的高一点,从高的角度来看,Kafka集群的业务处理就像这样子:
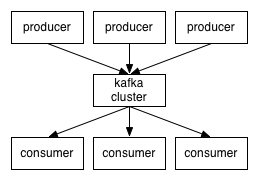
Client和Server之间的交流通过一条简单、高性能并且不局限某种开发语言的TCP协议。除了Java Client外,还有非常多的其它编程语言的Client。
