现在谈起大数据几乎等价于谈论Hadoop及其它的生态圈产品。但是现在一个下一代的计算框架已经长大,而且声名显赫。那就是Spark。你或许已经听说过它以及它的诸多好处。
自从发布之日起,Hadoop就被认为是Google大数据工具的等价实现。它帮助很多公司处理先前不可想象的大数据。围绕着它的两个主要部件(HDFS,分布式一致性的文件系统,和MapReduce, 分布式的计算框架), 一堆相关的工具涌现, 补充并提高它的功能。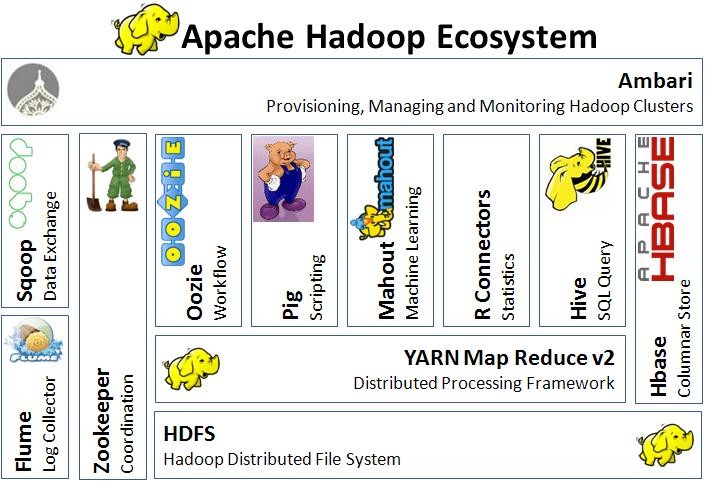
在YARN上运行Spark
Spark自0.6.0版本起就支持运行在 YARN (Hadoop 下一代产品) 上, 在后续的版本中逐步加强。
基于ALS算法的简易在线推荐系统
根据作者的后一篇文章的介绍,这应该是他在Intel做实习生的时候两个半月做个一个实习项目: 《Spark上流式机器学习算法实现”终期检查报告 》
原文地址: 基于ALS算法的简易在线推荐系统
继前期完成广义线性模型的在线流式机器学习的代码后,我们对spark的mllib中的推荐系统这一部分比较感兴趣,因为推荐系统这一部分在现实生活中也非常实用,尤其是基于地理位置的在线推荐系统目前非常火热,很多商业软件如大众点评,淘点点等都希望能根据用户以往的一些行为和当前所处的地理位置给用户做出最佳的推荐,给用户带来意想不到的惊喜。
在推荐系统领域,目前市面上中文的参考书并不多,我们主要学习了目前就职于hulu公司的项亮编著的《推荐系统实战》这本书,这本书详细的介绍了推荐系统方面的一些典型算法和评估方法,并且结合作者的实际经验给出了很多推荐系统的相关实例,是学习推荐系统不可多得的一本好书,我们也受益匪浅。
在spark的例程中作者是根据movielens数据库(采用spark自带的小型movielens数据库在spark的data/mllib/sample_movielens_data.txt中)通过ALS(alternating leastsquares)算法来做的推荐系统。参考链接 http://spark.apache.org/docs/latest/mllib-collaborative-filtering.html
最初我们也是用上面所说的1500个的数据集进行在线ALS算法的有效性,效果还不错,后面我们采用中等规模的movielens数据集进行测试,取得比较好的效果,具体过程记录如下。数据集的链接如下http://grouplens.org/datasets/movielens/.
这种ALS算法不像基于用户或者基于物品的协同过滤算法一样,通过计算相似度来进行评分预测和推荐,而是通过矩阵分解的方法来进行预测用户对电影的评分。即如下图所示。
大数据计算新贵Spark在国内知名厂商中的应用汇总

MapReduce由于其设计上的约束只适合处理离线计算,在实时查询和迭代计算上仍有较大的不足,而随着业务的发展,业界对实时查询和迭代分析有更多的需求,单纯依靠MapReduce框架已经不能满足业务的需求了。Spark由于其可伸缩、基于内存计算等特点,且可以直接读写Hadoop上任何格式的数据,成为满足业务需求的最佳候选者。
Spark作为Apache顶级的开源项目,项目主页见http://spark.apache.org。在迭代计算,交互式查询计算以及批量流计算方面都有相关的子项目,如Shark、Spark Streaming、MLbase、GraphX、SparkR等。从13年起Spark开始举行了自已的Spark Summit会议,会议网址见http://spark-summit.org。Amplab实验室单独成立了独立公司Databricks来支持Spark的研发。
为了满足挖掘分析与交互式实时查询的计算需求,腾讯大数据使用了Spark平台来支持挖掘分析类计算、交互式实时查询计算以及允许误差范围的快速查询计算,目前腾讯大数据拥有超过200台的Spark集群,并独立维护Spark和Shark分支。Spark集群已稳定运行2年,他们积累了大量的案例和运营经验能力,另外多个业务的大数据查询与分析应用,已在陆续上线并稳定运行。在SQL查询性能方面普遍比MapReduce高出2倍以上,利用内存计算和内存表的特性,性能至少在10倍以上。在迭代计算与挖掘分析方面,精准推荐将小时和天级别的模型训练转变为Spark的分钟级别的训练,同时简洁的编程接口使得算法实现比MR在时间成本和代码量上高出许多。
Spark SQL 初探: 使用大数据分析2000万数据
去年网上曾放出个2000W的开房记录的数据库, 不知真假。 最近在学习Spark, 所以特意从网上找来数据测试一下, 这是一个绝佳的大数据素材。 如果数据涉及到个人隐私,请尽快删除, 本站不提供此类数据。你可以写个随机程序生成2000W的测试数据, 以CSV格式。
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行计算框架,Spark基于map reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
Spark是一个高效的分布式计算系统,相比Hadoop,它在性能上比Hadoop要高100倍。Spark提供比Hadoop更上层的API,同样的算法在Spark中实现往往只有Hadoop的1/10或者1/100的长度。Shark类似“SQL on Spark”,是一个在Spark上数据仓库的实现,在兼容Hive的情况下,性能最高可以达到Hive的一百倍。
Apache Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
2014年处, Apache 基金会宣布旗下的 Apache Spark 项目成为基金会的顶级项目,拥有顶级域名 http://spark.apache.org/。 Spark 的用户包括:阿里巴巴、Cloudera、Databricks、IBM、英特尔和雅虎等知名厂商。
Spark SQL是支持在Spark中使用Sql、HiveSql、Scaca中的关系型查询表达式。它的核心组件是一个新增的RDD类型SchemaRDD,它把行对象用一个Schema来描述行里面的所有列的数据类型,它就像是关系型数据库里面的一张表。它可以从原有的RDD创建,也可以是Parquet文件,最重要的是它可以支持用HiveQL从hive里面读取数据。
在2014年7月1日的Spark Summit上,Databricks宣布终止对Shark的开发,将重点放到Spark SQL上。在会议上,Databricks表示,Shark更多是对Hive的改造,替换了Hive的物理执行引擎,因此会有一个很快的速度。然而,不容忽视的是,Shark继承了大量的Hive代码,因此给优化和维护带来了大量的麻烦。随着性能优化和先进分析整合的进一步加深,基于MapReduce设计的部分无疑成为了整个项目的瓶颈。 详细内容请参看 Shark, Spark SQL, Hive on Spark, and the future of SQL on Spark
当前Spark SQL还处于alpha阶段,一些API在将将来的版本中可能会有所改变。
我也翻译几篇重要的Spark文档,你可以在我的网站找到。 Spark翻译文档
本文主要介绍了下面几个知识点:
- Spark读取文件夹的文件
- Spark filter和map使用
- Spark sql语句调用
- 自定义Spark sql的函数
Spark 配置指南
Spark可以在三个地方配置系统:
- Spark属性控制大部分的应用参数。 这些属性可以通过SparkConf对象, 或者Java系统属性.
- 环境变量可以为每台机器配置,比如IP地址, 通过每个节点上的conf/spark-env.sh脚本.
- 可同通过log4j.properties配置日志.
