目录 [−]
这个系列的文章是介绍如何使用Go语言来进行数据分析和机器学习。
Go机器学习的库目前还不是很多,功能海没有Python的丰富,希望在未来的几年里能有更多的功能丰富库面试。
这篇文章利用golearn库, 使用kNN方法来对Iris数据集进行分析。
Iris数据集
Iris数据集也称为鸢尾花数据集,或者叫做费雪鸢尾花卉数据集或者安德森鸢尾花卉数据集。是一类多重变量分析的数据集。它最初是埃德加·安德森从加拿大加斯帕半岛上的鸢尾属花朵中提取的地理变异数据,后由罗纳德·费雪作为判别分析的一个例子,运用到统计学中。
其它比较流行的数据集还有Adult,Wine,Car Evaluation等(1)。
Iris数据集包含了150个样本,都属于鸢尾属下的三个亚属,分别是山鸢尾(setosa)、变色鸢尾(versicolor)和维吉尼亚鸢尾(virginica)。四个特征被用作样本的定量分析,它们分别是花萼和花瓣的长度和宽度。基于这四个特征的集合,费雪发展了一个线性判别分析以确定其属种。
下面是这三种鸢尾的花,非常的漂亮:
 |  |  |
下图是鸢尾花数据集的散布图, 第一个种类与另外两个种类是线性可分离的,后两个种类是非线性可分离的:
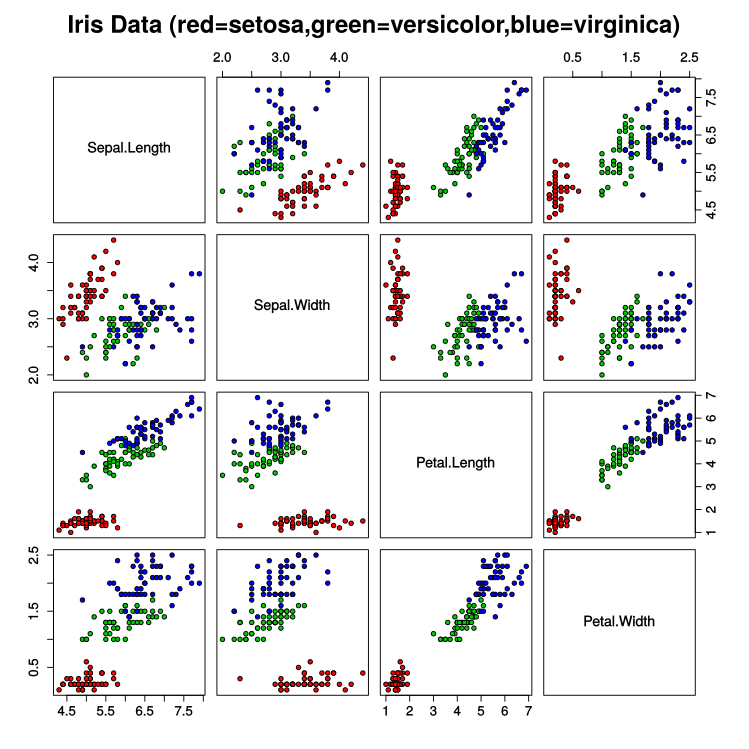
以上内容主要参考维基百科和百度百科关于Iris数据集的介绍。
这个数据集在网上很容易搜到,也可以在 golearn 项目中下载。
kNN K近邻算法
分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
简单说, 如果你住在高档小区,周围都是"高端人口", 那么可以判定你就是"高端人口", 然后就不会被......
k 代表最近的k个邻居。
训练数据和预测
下面就让我们看看 golearn使用kNN算法分析鸢尾花数据集的例子。
|
|
#12 行加载鸢尾花数据集, base提供了读取CSV文本文件的方法。
#18 行创建一个kNN分类器, 距离的计算使用欧几里德方法,此外还支持manhattan、cosine距离计算方法。第二个参数支持linear和kdtree。
#18 还指定了K为2。
#21 将鸢尾花数据集按照参数分成两份,它使用随机数和这个参数比较,所以分成的数据的结果大致是这个比例。一部分用于训练数据,一部分用于测试。接着#22开始训练数据。
#25 使用测试预测数据,并将预测结果打印出来。
#32 ~ #36 是评估预测模型,并将评估结果输出。
评估
首先看一下评估结果
|
|
这里有几个概念需要说明一下。
- ConfusionMatrix: 混淆矩阵,它描绘样本数据的真实属性与识别结果类型之间的关系,是评价分类器性能的一种常用方法,用于有监督学习。
- True Positives: 真正,TP, 被模型预测为正的正样本;可以称作判断为真的正确率
- False Positives: 假正,FP,误报, 被模型预测为正的负样本;可以称作误报率
- True Negatives: 真负,TN, 被模型预测为负的负样本 ;可以称作判断为假的正确率
- False Negatives: 假负,FN,漏报, 被模型预测为负的正样本;可以称作漏报率
- Precision: 精确率, 正确预测正负的个数/总个数,它表示的是预测为正的样本中有多少是真正的正样本。 $$P = \frac{TP}{TP+FP}$$,
- Recall: 召回率,它表示的是样本中的正例有多少被预测正确了, $$R = TPR = \frac{TP}{TP+FN}$$
- F1 Score: 为了能够评价不同算法的优劣,在Precision和Recall的基础上提出了F1值的概念,来对Precision和Recall进行整体评价。F1的定义如下:
F1值 = 正确率 * 召回率 * 2 / (正确率 + 召回率)
Python代码实现
使用sklearn很容易实现上面的逻辑。
|
|
