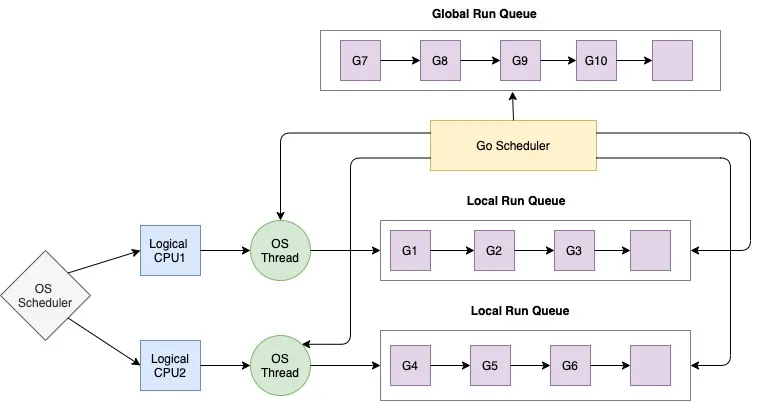
Go 运行时这么做,主要还是减少 P 之间对获取 goroutine 之间的竞争。本地队列 runq 主要由持有它的 P 进行读写,只有在"被偷"的情况下,才可能有"数据竞争"的问题,而这种情况发生概率较少,所以它设计了一个高效的 runq 数据结构来应对这么场景。实际看起来和上面介绍的 PoolDequeue 有异曲同工之妙。
type p struct { id int32 status uint32// one of pidle/prunning/... link puintptr schedtick uint32// incremented on every scheduler call syscalltick uint32// incremented on every system call sysmontick sysmontick // last tick observed by sysmon m muintptr // back-link to associated m (nil if idle) mcache *mcache pcache pageCache raceprocctx uintptr
deferpool []*_defer // pool of available defer structs (see panic.go) deferpoolbuf [32]*_defer
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen. goidcache uint64 goidcacheend uint64
// runqput 尝试将 g 放到本地可运行队列上。 // 如果 next 为 false,runqput 将 g 添加到可运行队列的尾部。 // 如果 next 为 true,runqput 将 g 放在 pp.runnext 位置。 // 如果可运行队列已满,runnext 将 g 放到全局队列上。 // 只能由拥有 P 的所有者执行。 funcrunqput(pp *p, gp *g, next bool) { if !haveSysmon && next { // 如果没有 sysmon,我们必须完全避免 runnext,否则会导致饥饿。 next = false } if randomizeScheduler && next && randn(2) == 0 { // 如果随机调度器打开,我们有一半的机会避免运行 runnext next = false }
// 如果 next 为 true,优先处理 runnext // 将当前的goroutine放到 runnext 中, 如果原来runnext中有goroutine, 则将其放到runq中 if next { retryNext: oldnext := pp.runnext if !pp.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) { goto retryNext } if oldnext == 0 { return } // Kick the old runnext out to the regular run queue. gp = oldnext.ptr() }
// 重点来了,将goroutine放入runq中 retry: h := atomic.LoadAcq(&pp.runqhead) // ① t := pp.runqtail if t-h < uint32(len(pp.runq)) { // ② 如果队列未满 pp.runq[t%uint32(len(pp.runq))].set(gp) // ③ 将goroutine放入队列 atomic.StoreRel(&pp.runqtail, t+1) // ④ 更新队尾 return } if runqputslow(pp, gp, h, t) { // ⑤ 如果队列满了,调用runqputslow 尝试将goroutine放入全局队列 return } // 如果队列未满,上面的操作应该已经成功返回,否则重试 goto retry }
runqput 方法的实现非常简单,它首先判断是否需要优先处理 runnext,如果需要,就将 g 放到 runnext 中,然后再将 g 放到 runq 中。 runq 的操作是无锁的,它通过 atomic 包提供的原子操作来实现。 这里使用的内部的更精细化的原子操作,这个也是我后面专门有一篇文章来讲解的。你现在大概把①、④ 理解为Load、Store操作即可。
②、⑤ 分别处理本地队列未满和队列已满的情况,如果队列未满,就将 g 放到队列中,然后更新队尾;如果队列已满,就调用 runqputslow 方法,将 g 放到全局队列中。
③ 处直接将 g 放到队列中,这是因为只有当前的 P 才能操作 runq,所以不会有并发问题。 同时我们也可以看到,我们总是往尾部插入, t总是一直增加的, 取余操作保证了循环队列的特性。
runqputslow 会把本地队列中的一半的 g 放到全局队列中,包括当前要放入的 g。一旦涉及到全局队列,就会有一定的竞争,Go运行时使用了一把锁来控制并发,所以 runqputslow 方法是一个慢路径,是性能的瓶颈点。
runqputbatch
func runqputbatch(pp *p, q *gQueue, qsize int) 是批量往本地队列中放入 g 的方法,比如它从其它 P 那里偷来一批 g ,需要放到本地队列中,就会调用这个方法。它的实现如下:
// runqget 从本地可运行队列中获取一个 G。 // 如果 inheritTime 为 true,gp 应该继承当前时间片的剩余时间。 // 否则,它应该开始一个新的时间片。 // 只能由拥有 P 的所有者执行。 funcrunqget(pp *p) (gp *g, inheritTime bool) { next := pp.runnext // 如果有 runnext,优先处理 runnext if next != 0 && pp.runnext.cas(next, 0) { // ① return next.ptr(), true }
for { h := atomic.LoadAcq(&pp.runqhead) // ② 获取队头 t := pp.runqtail if t == h { // ③ 队列为空 returnnil, false } gp := pp.runq[h%uint32(len(pp.runq))].ptr() // ④ 获取队头的goroutine if atomic.CasRel(&pp.runqhead, h, h+1) { // ⑤ 更新队头 return gp, false } } }
// runqdrain 从 pp 的本地可运行队列中获取所有的 G 并返回。 // 只能由拥有 P 的所有者执行。 funcrunqdrain(pp *p) (drainQ gQueue, n uint32) { oldNext := pp.runnext if oldNext != 0 && pp.runnext.cas(oldNext, 0) { drainQ.pushBack(oldNext.ptr()) // ① 将 runnext 中的goroutine放入队列 n++ }
retry: h := atomic.LoadAcq(&pp.runqhead) // ② 获取队头 t := pp.runqtail qn := t - h if qn == 0 { return } if qn > uint32(len(pp.runq)) { // ③ 居然超出队列的长度了? goto retry }
// runqgrab 从 pp 的本地可运行队列中获取一半的 G 并返回。 // Batch 是一个环形缓冲区,从 batchHead 开始。 // 返回获取的 goroutine 数量。 // 可以由任何 P 执行。 funcrunqgrab(pp *p, batch *[256]guintptr, batchHead uint32, stealRunNextG bool)uint32 { for { h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with other consumers t := atomic.LoadAcq(&pp.runqtail) // load-acquire, synchronize with the producer n := t - h n = n - n/2// ① 取一半的goroutine if n == 0 { if stealRunNextG { // ② 如果要偷取runnext中的goroutine if next := pp.runnext; next != 0 { if pp.status == _Prunning { // ② 如果要偷取runnext中的goroutine,这里会sleep一会 if !osHasLowResTimer { usleep(3) } else { osyield() } } if !pp.runnext.cas(next, 0) { continue } batch[batchHead%uint32(len(batch))] = next return1 } } return0 } if n > uint32(len(pp.runq)/2) { // ③ 如果要偷取的goroutine数量超过一半, 重试 continue }
// ④ 将队列中至多一半的goroutine放入batch中 for i := uint32(0); i < n; i++ { g := pp.runq[(h+i)%uint32(len(pp.runq))] batch[(batchHead+i)%uint32(len(batch))] = g } if atomic.CasRel(&pp.runqhead, h, h+n) { // ⑤ 更新队头 return n } } }
funcglobrunqputbatch(batch *gQueue, n int32) { assertLockHeld(&sched.lock) // 保证锁被持有
sched.runq.pushBackAll(*batch) sched.runqsize += n *batch = gQueue{} }
funcglobrunqget(pp *p, max int32) *g { assertLockHeld(&sched.lock) // 保证锁被持有
if sched.runqsize == 0 { // 如果全局队列为空 returnnil }
n := sched.runqsize/gomaxprocs + 1// 从全局队列中获取goroutine的数量 if n > sched.runqsize { n = sched.runqsize } if max > 0 && n > max { // 如果max大于0,取最小值 n = max } if n > int32(len(pp.runq))/2 { // 如果要获取的goroutine数量超过一半,只取一半,不贪婪 n = int32(len(pp.runq)) / 2 }
sched.runqsize -= n
gp := sched.runq.pop() // 从全局队列中获取一个goroutine n-- for ; n > 0; n-- { // 从全局队列中获取n-1个goroutine gp1 := sched.runq.pop() runqput(pp, gp1, false) // 将goroutine放入本地队列 } return gp // 返回获取的goroutine }