这是百度网络监控工具 nettools 开源系列的第四篇。前三篇分别介绍了 bitflip/baize(UDP 丢包与改包检测工具和Agent)、lidar(TCP SYN 端口可达性探测),它们解决的都是「服务器之间」「点到点」的探测问题——前提是:探测机和被探测对象,至少有一端在我们手里。
但有一类设备,我们既无法在它上面装 agent,也没法在它对面的机房里放一台探测机。这就是今天的主角 evr 要解决的困境。
这也是我更深入的了解网络包的构造,把网络探测玩出花了来,对我的网络编程的功力大增的一个很好的场景。
项目地址:https://github.com/baidu/nettools
文档:https://nettools.rpcx.io
一、evr 探测的困境:探测机进不去客户机房
先说一个真实的场景。
百度有大量的云客户,我们提供的 EVR(Edge Virtual Router,边缘虚拟路由器) 设备作为客户侧网络接入百度云网络的边界节点。EVR 往上连百度的骨干/城域网络,往下连客户自己的虚拟网络(VXLAN overlay)。
EVR - 边缘虚拟路由器,通常用于在虚拟化环境中实现路由功能。EVR 位于网络的边缘,用于连接内部网络和外部网络(如客户机房)。
现在问题来了:我们需要监控「百度网络 → EVR」这一段链路的健康度——有没有丢包、延迟多大、有没有改包。按照前几个工具的套路,我们的方案应该是:
- 在 EVR 设备上装个 agent?—— 不行。EVR 是网络设备/客户侧设备,我们没有权限往里塞监控程序。
- 在 EVR 对面(客户机房内)放一台探测机,做点到点探测?—— 更不行。那是客户的机房,正常情况我们不可能在客户的物理环境里申请一台探测机常驻。
lidar 那一套「发 SYN,靠对端内核 TCP 协议栈自动回 SYN-ACK/RST」的思路,在这里也不灵——EVR 不是一台服务器,它不会帮你跑 TCP 协议栈三次握手,或者说不允许我们高频的探测。
1 | 百度侧 边缘设备 |
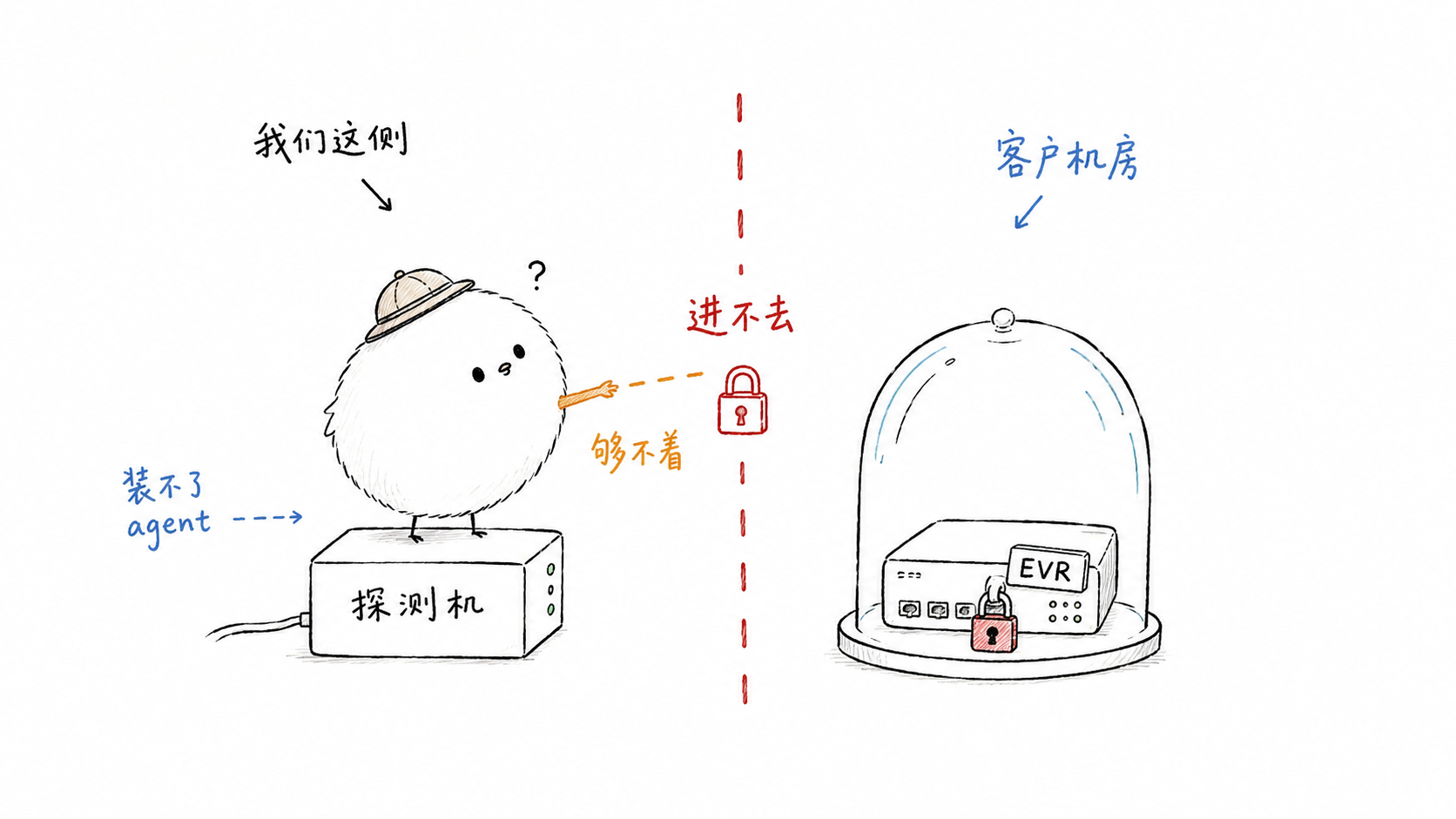
困境的本质是:被探测对象不可控,且它对面也无法部署探测机。 我们需要一个 「单边」 就能完成的探测方案——只在百度侧放一台机器,让 EVR 设备自己「帮我们把包送回来」。
答案藏在 EVR 设备的工作原理里:它是一个 VXLAN VTEP(VXLAN Tunnel End Point)。而 VTEP 有一个非常好用的特性——它会忠实地按照内层 IP 头转发解封后的内层帧。这就给了我们「构造一个会被反射回来的 VXLAN 包」的可能。
要理解这个技巧,得先看懂 VXLAN 的包结构。
二、VXLAN:把二层帧塞进 UDP 里
VXLAN(Virtual Extensible LAN,RFC 7348)是数据中心 overlay 网络的事实标准。它要解决的核心问题是:传统 VLAN 只有 12 位 VLAN ID,最多 4096 个二层网络,在大规模多租户云环境里完全不够用。
VXLAN 的做法简单粗暴又有效:把一个完整的二层以太网帧,整个塞进一个 UDP 数据报里,通过三层网络传输。这样原本受限于物理二层域的网络,可以跨越任意三层网络延展,VNI(VXLAN Network Identifier)有 24 位,支持约 1600 万个 overlay 网络。
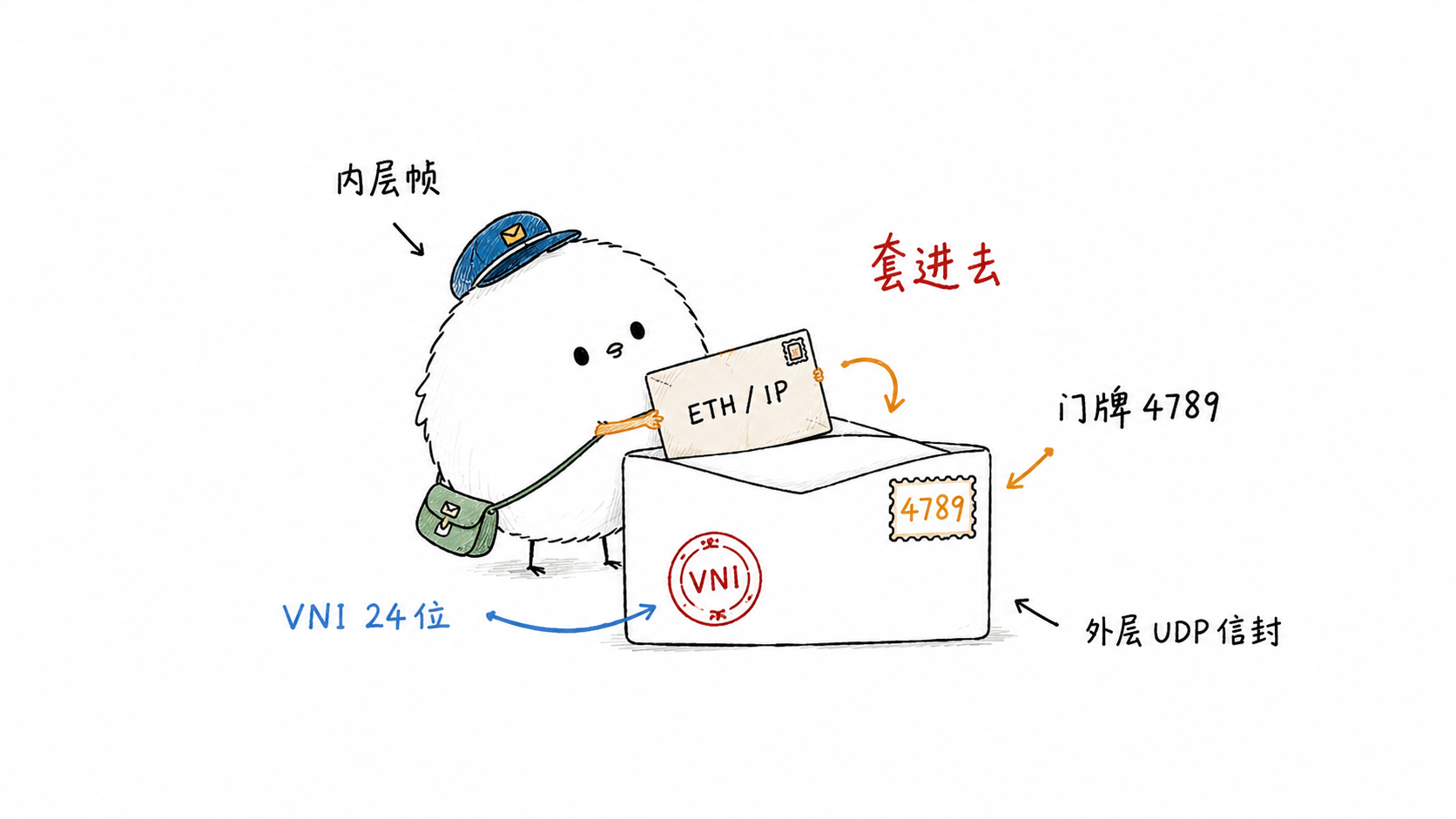
它的包结构从外到内是这样的:
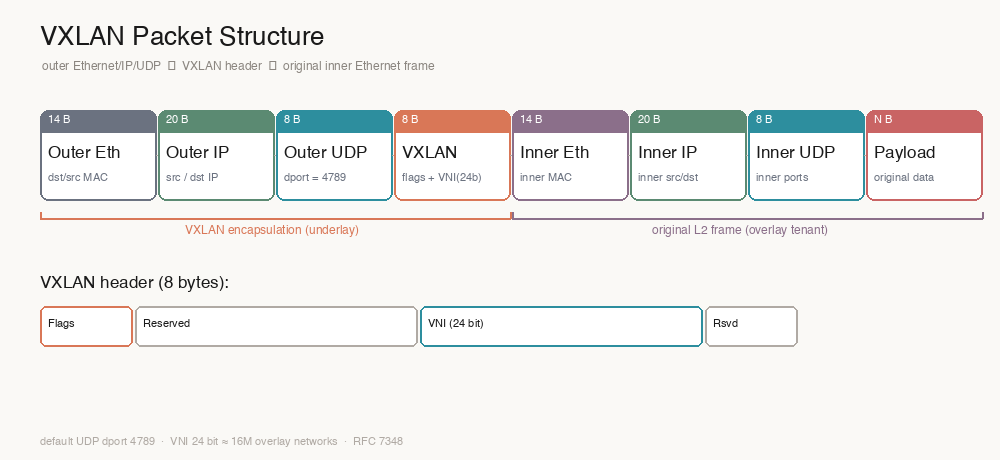
一层层拆开看:
| 层 | 大小 | 关键字段 | 作用 |
|---|---|---|---|
| 外层 Ethernet | 14 B | 物理 MAC | underlay 二层转发 |
| 外层 IP | 20 B | src / dst IP | underlay 三层路由(VTEP 之间) |
| 外层 UDP | 8 B | dport = 4789 | VXLAN 标准端口,VTEP 据此识别 |
| VXLAN header | 8 B | flags + VNI(24 位) | 标识 overlay 网络 |
| 内层 Ethernet | 14 B | 租户 MAC | 被封装的原始二层帧开始 |
| 内层 IP | 20 B | 内层 src / dst | overlay 里的真实通信地址 |
| 内层 UDP/TCP | 8 B | 内层端口 | 租户的真实流量 |
| Payload | N B | 业务数据 | 原始负载 |
| 其中 8 字节的 VXLAN header 结构是: |
1 | 0 1 2 3 |
I 位(第 5 位)置 1 表示 VNI 有效,剩下的 24 位就是 VNI。
VTEP 的工作模型:它从外层 UDP/4789 收到一个 VXLAN 包,剥掉外层 Eth/IP/UDP 和 VXLAN header,拿到内层的原始以太网帧,然后按内层 IP 头继续转发。
注意最后这句话——「按内层 IP 头继续转发」。这就是 evr 整个设计的命门所在:如果我把内层 dst IP 填成我自己,VTEP 解封后不就把包转回给我了吗?
三、evr 工具:让 EVR 自己把包反射回来
实现原理:自环内层帧 + payload 内嵌 EVR 源 IP
evr 的核心是一个反直觉但极其精简的设计——「自环内层帧」。
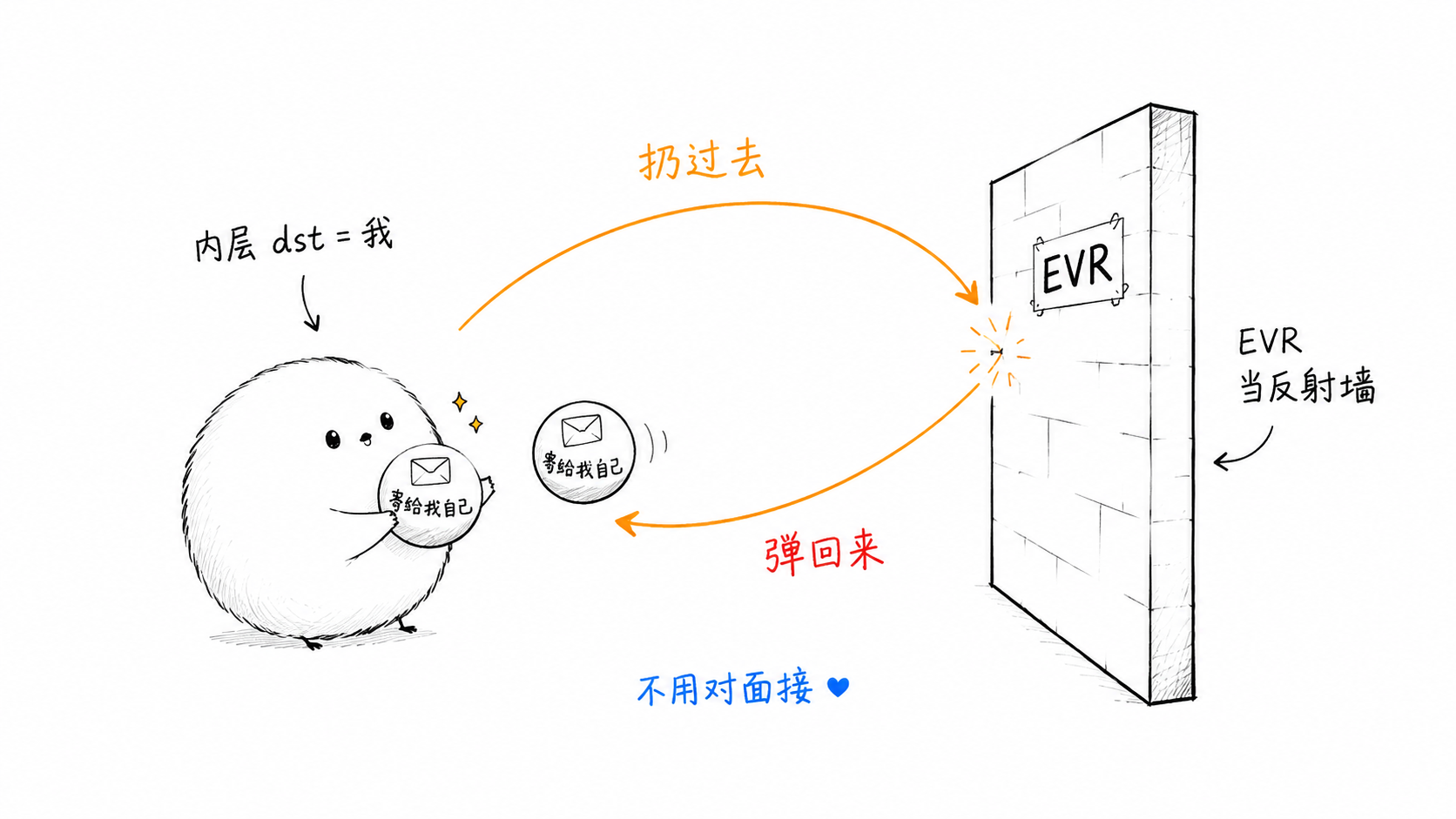
先看一个绕不开的硬约束:VTEP 是按内层 IP 头转发解封后的帧的。所以要让反射的包能回到探测机,内层 dst IP 就必须填探测机本机——填别的地址,包就被转到别处去了,根本回不来。这一点没得选。
真正有选择空间的是内层 src IP。最「自然」的想法是:把每个目标 EVR 的源 IP 填进内层 src IP,回包时靠这个 src IP 区分「是哪个目标反射回来的」。多目标时,本机收到一堆 dst=本机、src=各个 EVR 的回包,按 src IP 分流即可。
但 evr 偏偏没这么做——它把内层 src IP 也填成了本机(src = dst = 本机,自环)。这样一来,那个本可用来标识目标的内层 src IP 就被「浪费」掉了,回包里全是 src=本机, dst=本机,彼此长得一模一样,没法区分目标了。
那为什么要主动放弃这个天然的标识位?这里其实有一个技巧:
当出现故障的时候,我们要使用traceroute的功能,通过设置TTL,回获取内层的回包经过的路径。通过设置src IP为探测机的IP,我们就能够让ICMP的回包发送给探测机,这样就可以把回程的路径都探测出来了。
evr 的三招合起来是这样:
第一招:内层 src IP 和 dst IP 都填探测机的本机地址。
1 | // agent.go:内层 src == 内层 dst == 本机 IP |
EVR 解封 VXLAN 后看到内层 dst = 本机,自然就把内层帧转回本机。本机的 raw socket 直接收到回包,不需要在对端起任何 server,也不需要单独申请回包用的 IP/端口。
第二招:把「真正的目标标识」嵌进 payload。
既然内层 src/dst 都被占用成本机了,那「这个包是探测哪个 EVR 的」靠什么区分?答案是把目标 EVR 的IP 写进 payload 的第 24~28 字节:
1 | // codec/packet.go:EVRCHECK 协议头 |
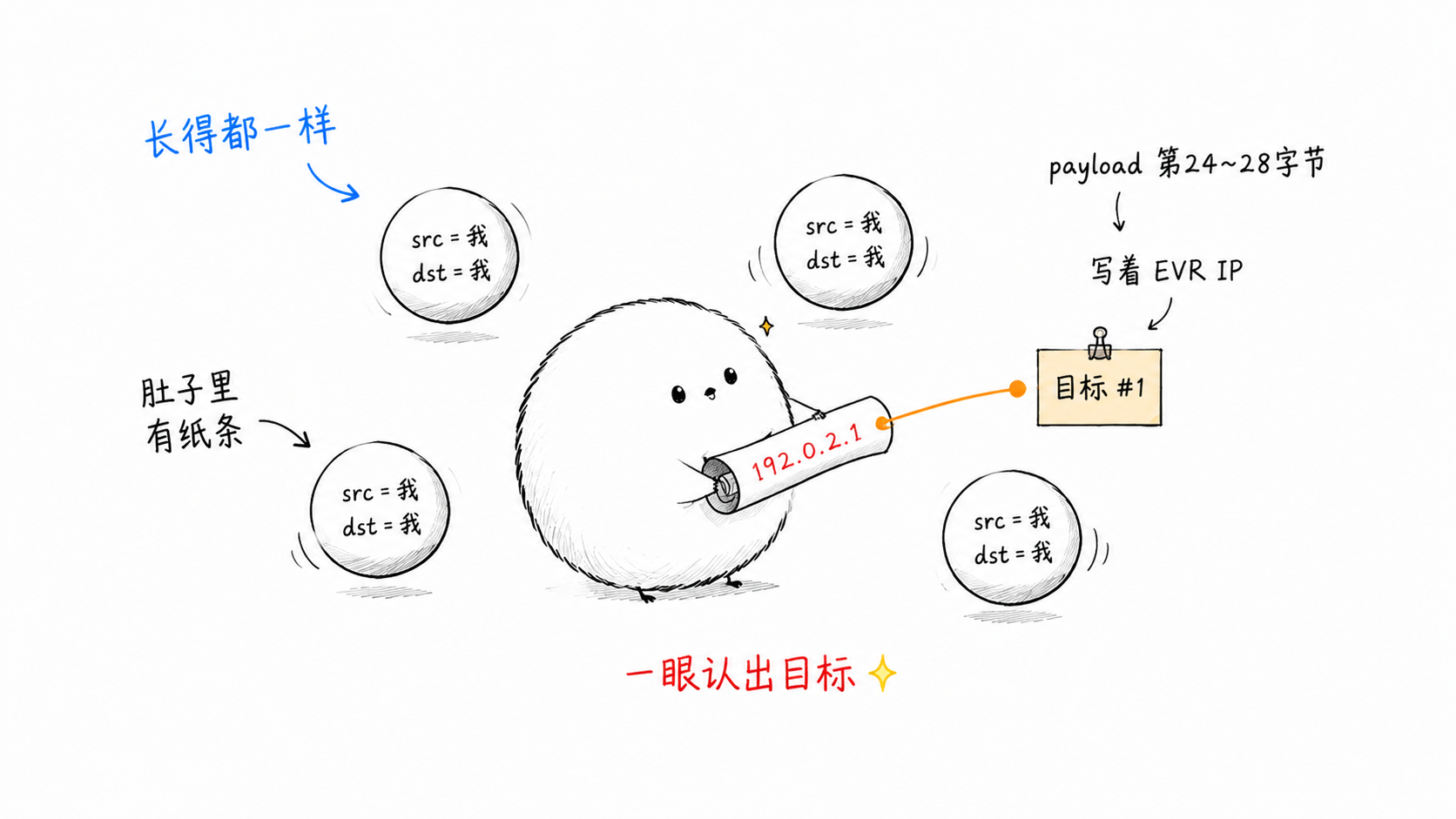
回包时解析 payload 里的这 4 字节,一步定位回目标:
1 | // agent.go:handlePacket 收到回包 |
本质上,evr 把「目标标识」从 IP 头搬到了 payload 里,让 EVR 的 VXLAN 反射动作天然变成一次「单源对多目标」的回包匹配。代价仅仅是 4 字节 payload + 解析时多读 4 字节。
第三招:外层源 IP 可以 spoof。
evr 用 ipv4.NewRawConn 包了一层(等价于开启 IP_HDRINCL),让内核不再自己生成外层 IP 头,而是原样发出我们手工拼好的外层 IPv4 头。这样外层 src IP 可以填成 mock_src——一个虚假的IP地址。当然这个功能是可选的。
这有什么好处呢?
为了在Evr上识别出来探测包,我们其实是在Evr中做了一些特殊的配置的,使用和客户不同的VNI,识别出『探测机』的源IP,有不同的路由策略。但这也带来的一个问题: 如果探测机有故障,需要切换探测机的时候,需要在Evr上改配置。
为线上的网络设备修改配置流程上很复杂,需要评审改配方案、需要等待变更窗口,需要在凌晨的时候操作等。所以不能及时的更改探测机。但是如果我们使用mockIP,那么就可以分分钟的把探测切到新的探测机上,不需要修改Evr的配置。这也是我们的一个技巧。
完整的一发一收流程:
1 | 发送侧 回程侧 |
整个过程只在百度侧部署一台 evr,EVR 设备本身充当了反射器——困境破解。
使用方法
evr 由 JSON 配置驱动,每个 target 用 vtep#evrSrc[#mockSrc] 三段式表达:
1 | { |
三段式的含义:
| 段 | 必填 | 含义 |
|---|---|---|
vtepIP |
是 | EVR VTEP 的 IP(外层目的地址) |
evrSrcIP |
是 | 「目标」标识,嵌入 payload 用于回包匹配 |
mockSrcIP |
否 | 外层源 IP;为空则用 client_addr |
| 启动: |
1 | # 配置文件启动(推荐,线上用 systemd 以 root 拉起) |
evr 需要 sudo(或 CAP_NET_RAW)来创建 raw socket、启用 IP_HDRINCL、设置 IP TOS 并挂载 BPF。它仅在 Linux 上有意义,macOS 只能用于编译开发。
四、evr 中的技巧与高频 FAQ
evr 看似简单,但藏了几个值得拿出来单独说的工程技巧。
技巧 1:BPF 内核层过滤,别让无关 UDP 流量打扰
读 socket 用的是 ip4:udp raw socket,它默认会收到本机所有 UDP 报文。在万兆网卡、几十万 pps 的探测机上,内核把海量无关包拷到用户态,性能直接崩。
解法是在内核层用 cBPF 过滤,只放行三个条件同时命中的包:
1 | (1) IPv4 协议号 = UDP (17) |
只有这三条都满足才投递到用户态,几乎零开销。而写 socket 上则反过来装一个「全丢」的 BPF——阻止内核给这个发送 socket 排队任何回包。
技巧 2:源端口轮转覆盖 ECMP 多路径
和 bitflip/lidar 一样,evr 也面临多路径覆盖问题。两个固定地址之间,五元组固定则 ECMP 哈希结果不变,永远只走一条链路。evr 通过 client_port_range 配置一段源端口,每发一轮就让 srcPort + 1,在统计意义上覆盖 ECMP 哈希全空间。
技巧 3:4 种 Salt 模式抓 bitflip
payload 第 28 字节往后是 Salt 填充,按 seq % 4 在四种模式间轮换,专门用来检测链路上的位翻转:
0xFF全 1 —— 暴露任何「1 变 0」的翻转0x00全 0 —— 暴露任何「0 变 1」的翻转0x5A交替位 (01011010) —— 适配 NIC 串行链路的奇偶错误- 互补
0xAAAA / 0x5555—— 专治 1's complement 校验和漏检的「互补翻转」,这是普通 UDP/TCP checksum 唯一无法察觉的一类 bitflip
回包时如果 payload 长度等于发送长度,就和对应 Salt 比对,命中差异即记一条 [client bitflip] 日志。这套 Salt 实现与 baize/kuiniu 完全共用。
高频 FAQ
Q:mock_src 是怎么生效的?内核为什么不会把它改回去?
evr 在写端用 ipv4.NewRawConn(conn) 包了一层,等价于开启 IP_HDRINCL。开启后内核不再生成自己的 IP 头,而是原样发出我们手工拼的外层 IPv4 头,其中 src 就是 mock_src。如果不包这一层,内核会前置一份自己的 IP 头,导致双层 IP 封装且 mock_src 失效。
Q:rate_in_span 是单 target 速率还是总速率?
是所有 target 的总速率。比如 12 个 target、rate_in_span=2000/s,每个 target 平均只有约 166 pps。要提高单 target 速率,就减少 target 数量或调大 rate_in_span。
Q:为什么内层 src 和 dst 都填本机 IP?
这样 EVR 反射回来的内层帧 dst 就是本机,本机 raw socket 直接收得到,无需在对端起 server、无需单独申请回包 IP。这是 evr 破解「对面进不去」困境的核心招式。src IP也填写本机IP是为了定位的时候traceroute的需要。
Q:为什么 evr 必须用 sudo?
需要创建 ip4:udp raw socket、启用 IP_HDRINCL、设置 IP TOS/DSCP 并挂载 BPF。Linux 上需要 CAP_NET_RAW,最简单就是 sudo 或 systemd 以 root 启动。
Q:和 baize / kuiniu 怎么选?
普通业务网络长期监控用 baize;AI 训练的 GPU NIC 互联(RoCE)用 kuiniu;机房 VXLAN/EVR 路径与 EVR 设备本身的探测用 evr——关键区别是 evr 不需要在对端起 server,EVR 设备本身就是反射器。
evr 把一个看似无解的困境——「探测机进不去客户机房,被探测设备又装不了 agent」——通过对 VXLAN VTEP 反射特性的巧妙利用,变成了一个单边即可完成的探测。这背后是同一套技术栈在不同网络场景下的复用:raw socket 构造报文、BPF 内核过滤、源端口轮转覆盖 ECMP、Salt 检测 bitflip、时间桶统计。
这只是 nettools 的冰山一角。后续还有网关设备监控、定位工具,以及巨量监控数据的处理方案。
项目地址:https://github.com/baidu/nettools
欢迎 Star、试用、提 Issue 和 PR。
