真正的深度研究报告不是让 AI "写"出来的,而是"研究"出来的。这两个字差别大了。
最近几个月,几个产品让我眼前一亮:Gemini Deep Research、Manus Wide Research,还有 OpenAI 的 Deep Research。它们都在做同一件事——让 AI 具备真正的"研究能力"。
这事儿得从"上下文窗口陷阱"说起。
一、上下文窗口陷阱
这个方案的巧妙之处在于规避了上下文窗口问题。
传统方式是一个 Agent 处理所有任务,越往后上下文越拥挤,质量必然下降。而 Manus 的方式是每个 Agent 都从零开始,大家都是"满血"状态,不存在谁挤占谁的问题。
官方有个案例——研究 250 位 AI 研究员。
第 1 位到第 250 位,每位的详细程度都一样:完整的背景、研究方向、代表作、核心论文。这换成传统 AI 根本做不到——早就因为上下文爆炸而开始胡编乱造了。
技术实现细节
剥开产品外壳,Manus 的架构其实挺讲究的。核心思想来自一篇叫《CodeAct》的论文:让 AI 像程序员一样工作——写代码、运行代码、看结果、改代码、再运行。
ReAct 模式
每个 Agent 的执行逻辑是一个循环:观察(Observation)→ 思考(Thought)→ 行动(Action)→ 观察...不断迭代,直到任务完成。
这不是简单的"调用工具",而是边思考边行动。搜索结果不相关?换关键词。代码执行报错?检查原因、修改命令、重试。
1 | ┌─────────────────────────────────────────────┐ |
沙箱隔离
每个 Agent 跑在独立的虚拟机环境里。这不是多线程,而是真正的隔离——独立的文件系统、独立的网络、独立的进程空间。
Manus 用了沙箱技术,这样就算某个 Agent 被诱导执行了危险命令,也影响不到其他 Agent 和宿主系统。
任务分解:DAG 结构
主 Agent 把复杂任务拆成有向无环图(DAG)。清楚知道哪些步骤可以并行,哪些必须等前置条件。
比如"研究 50 家风电公司"的执行图:
1 | [主 Agent:任务分解] |
工具集
Manus 提供了 29 种工具,分成几类:
| 类别 | 工具示例 | 用途 |
|---|---|---|
| 命令执行 | Shell、Python | 执行任意代码和系统命令 |
| 文件操作 | 读写 txt/md/pdf/xlsx | 处理各种格式的文档 |
| 网络能力 | 搜索、浏览器、端口部署 | 获取信息、部署服务 |
| 系统能力 | 进程管理、软件安装 | 配置运行环境 |
这些工具让 Agent 能真正"动手做事",而不是只会生成文本。比如研究一家公司,它可以:搜索公司官网、爬取财报数据、用 Python 分析财务指标、把结果写入表格。
动态质量检测
Manus 不是按预设流程走到黑。每次执行完一个步骤,都会判断:结果可信吗?需要调整方向吗?
1 | def quality_check(result): |
代码执行报错?调整命令重试。搜索结果太少?换搜索引擎或关键词。这种自我纠错能力,让它在遇到问题时不会死磕,而是会寻找替代方案。
状态管理
每个任务维护一个 todo.md 文件,实时更新进度:
1 | # TODO |
这样做的好处是:任务中断后可以恢复;用户随时能看到进展;中间结果有地方存储,不会丢失。
当然这些分析都是我们基于Manus的产品、宣传资料和外部人员的分析做的推测,我们实际并不知道Manus内部的方案。仅供分析和学习。
四、真正的"研究"是什么?
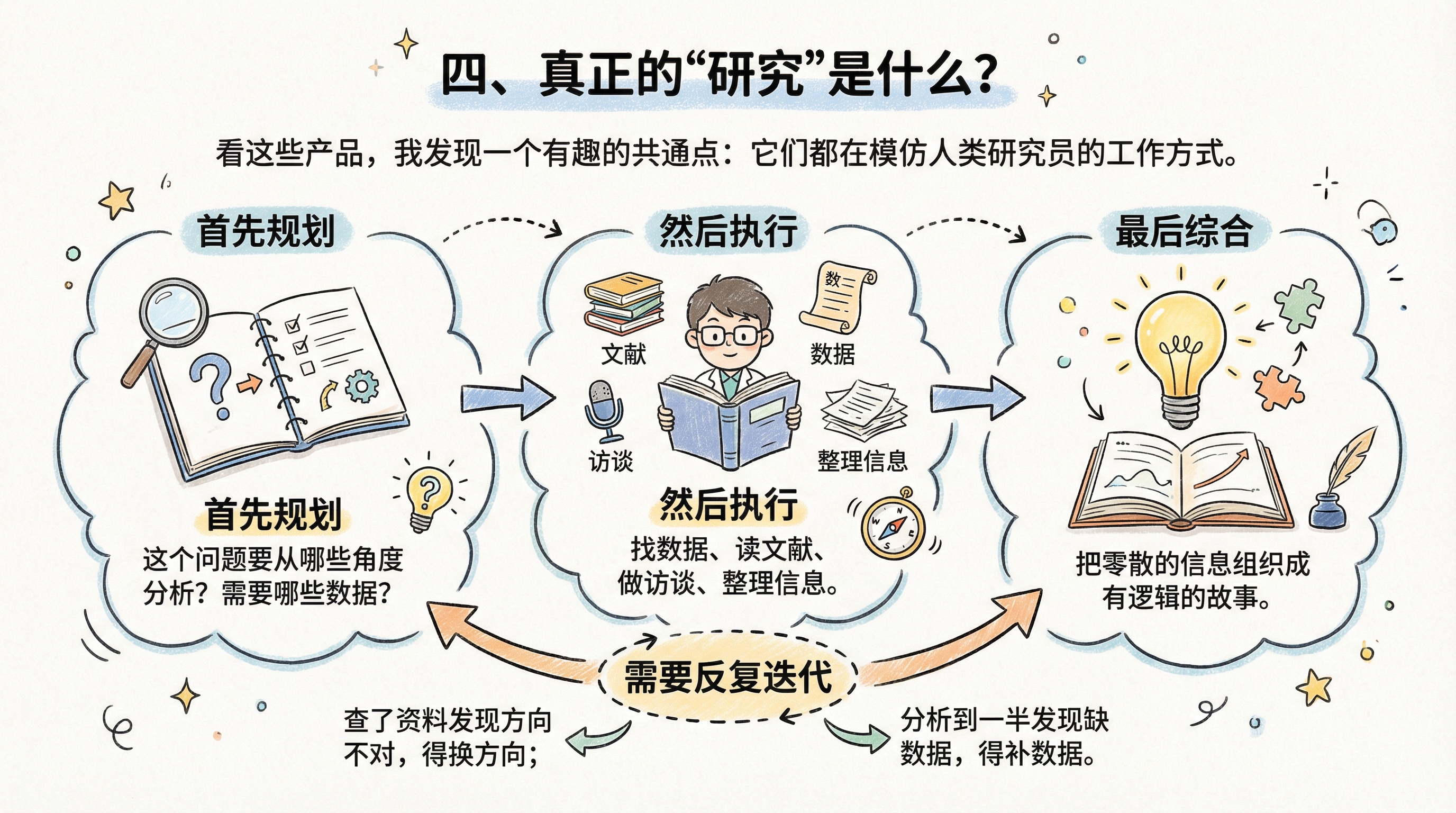
看这些产品,我发现一个有趣的共通点:它们都在模仿人类研究员的工作方式。
人类研究员怎么做深度报告?
- 首先规划:这个问题要从哪些角度分析?需要哪些数据?
- 然后执行:找数据、读文献、做访谈、整理信息。
- 最后综合:把零散的信息组织成有逻辑的故事。
关键在于,这不是一次性能完成的。需要反复迭代——查了资料发现方向不对,得换方向;分析到一半发现缺数据,得补数据。
传统的 LLM chat 模式,本质上是一次性生成。给你个 prompt,你吐出结果。这是"写作",不是"研究"。
真正的深度研究 agent,应该具备:
① 规划能力:能理解任务,制定研究策略,知道先查什么后查什么。
② 工具能力:会用搜索引擎、读数据库、解析文档,不只是从训练数据里抠信息。
③ 迭代能力:能根据中间结果调整方向,不是按预定流程走到黑。
④ 验证能力:能交叉验证信息来源,不是捡到什么信什么。
⑤ 综合能力:能把碎片信息拼成完整故事,不是简单的信息罗列。
Gemini Deep Research 和 Manus Wide Research,本质上都是在往这个方向努力。只是侧重点不同——前者重"深",后者重"广"。
五、一些思考
高质量的资料源
就像研究员一样,要想生成高质量的报告,必须要有高质量的数据源作为基础。
如上面提到过的,这方面搜索引擎具有优势,他们拥有全面性,时效性高的搜索资料。
一些专业的网站也有行业方面的专业资料,比如金融领域相关的,IT技术相关的、白酒方面相关的
电商方面相关的,旅游行业相关的、出行方面相关的、法律行业相关的,科普方面相关的,他们能够提供垂类专业的资料,如果要生成这方面的报告,找这些行业相关的网站信息是最好的。当然如果这些资料是公开的,可以通过搜索因为+专业的搜索词进行搜索获取,所以搜索引擎的重要性在AI的深度调研报告生成中占很重要的地位。
但是搜索引擎并不轻易把它的能力无偿的暴露出来,比如谷歌,它提供付费的搜索API,价格不低。Bing已经把它的搜索API下掉了。还有一些第三方的服务,或许是通过爬虫的方式进行搜索,比如Travily、Brave、SerpAPI等,也提供收费的服务。总的来说,好东西都是有价格的。这些搜索引擎增加了反爬虫的机制,我几个月前还能绕过这些限制,现在也不行了,他们都很聪明,不会轻易让你免费使用的。
从 Manus网站的输出来看,我怀疑它们买了某个或者某几个服务器服务商的服务,可以针对用户的请求,得到搜索引擎的列表 (SERP), 这是猜测,前端并看不出来,因为它们并不可能去做个搜索引擎。专业的人做专业的事。它们拿到搜索结果列表后,通过它们的AI浏览器,也就是虚拟机的浏览器去浏览网络,获取网页的内容。它们叫cloud browser,应该是基于browserbase开发的。沙盒技术和Browser我放在下一个拆解文章中在再专门介绍,这一篇还是专门关注调研报告的实现。
识别用户的意图
专业的用户会提供详细的、简洁的、对 AI 友好的提示词,但是大部分用户并不能很好的表达自己的意图,比如:
请帮我分析Apple的市场行情
这里的Apple指的是苹果电脑公司还是水果苹果🍎呢?非常有歧义。还有的提示词含糊不清。在Insight的实现在,我们首先实现的就是对用户的提示词进行澄清。理论上对于非常模糊的提示词,比如Apple这里例子,我们需要进一步询问用户,反问用户的意图,但是Insight还没进一步的实现这个功能,而是自动进行澄清,它是怎么实现的呢?
生成报告大纲
接下来专门有个agent(StructurePlannerNode)负责生成报告的节点,主要确定报告的主要大纲和方向。

区分报告的种类进行规划搜索任务
接下来针对报告的大纲, Planner Agent针对金融投资领域、技术开发领域、商业分析领域、政策相关领域、通用领域等各种领域制定搜索计划,为每个章节搜索足够的信息备用。
执行搜索
Search Agent 会根据搜索计划,逐步实现相关内容的搜索。
它会根据项目提供的工具,进行搜索。目前提供了travily、github、谷歌学术、知乎、微信公众号等网站的搜索,我其实还是期望能直接搜索google的搜索结果和一些顶级的专业网站的搜索内容。
搜索的结果内容如果太长,还会对它们进行summary,以便压缩上下文。
此节点还会针对每个章节进行内容的总结。
现在万事俱备了,所有的大纲和材料都准备好了,可以进行报告的编写了。有请 ContentWriter Agent。
内容的编写
ContentWriter 负责报告的编写,它根据大纲和材料进行内容的创作。
说起创作来,针对内容创作的场景,我们为了提高创作产品的质量,经常采用Reflection模式,针对生成的内容进行打分,要不要进行优化。
所以这个Agent生成后,会调用Reflector Agent进行打分,以便决定要不要调用Revisor节点进行订正。你看报告生成的日志也能观察到这一点。
除非生成的报告片段达到了“优”的级别,否则就会尝试补充和订正,直到达到了 5 轮的反复订正才算通过。
所以你会看到Insight生成的报告的质量还是很高的,不像一个玩具或者示例deep research产品的报告那么简略或者偏离主题。

Reportor Agent
最后这个Agent把各个章节合在一起,生成一个完整的markdown的报告。
会生成合理的章节,并进行编号。
另外还有的Podcast Agent,可以生成播客的脚本。如果用户请求中要求生成播客,那么此Agent就会自动生成。
工作流程
完整的工作流 (graph)如下:
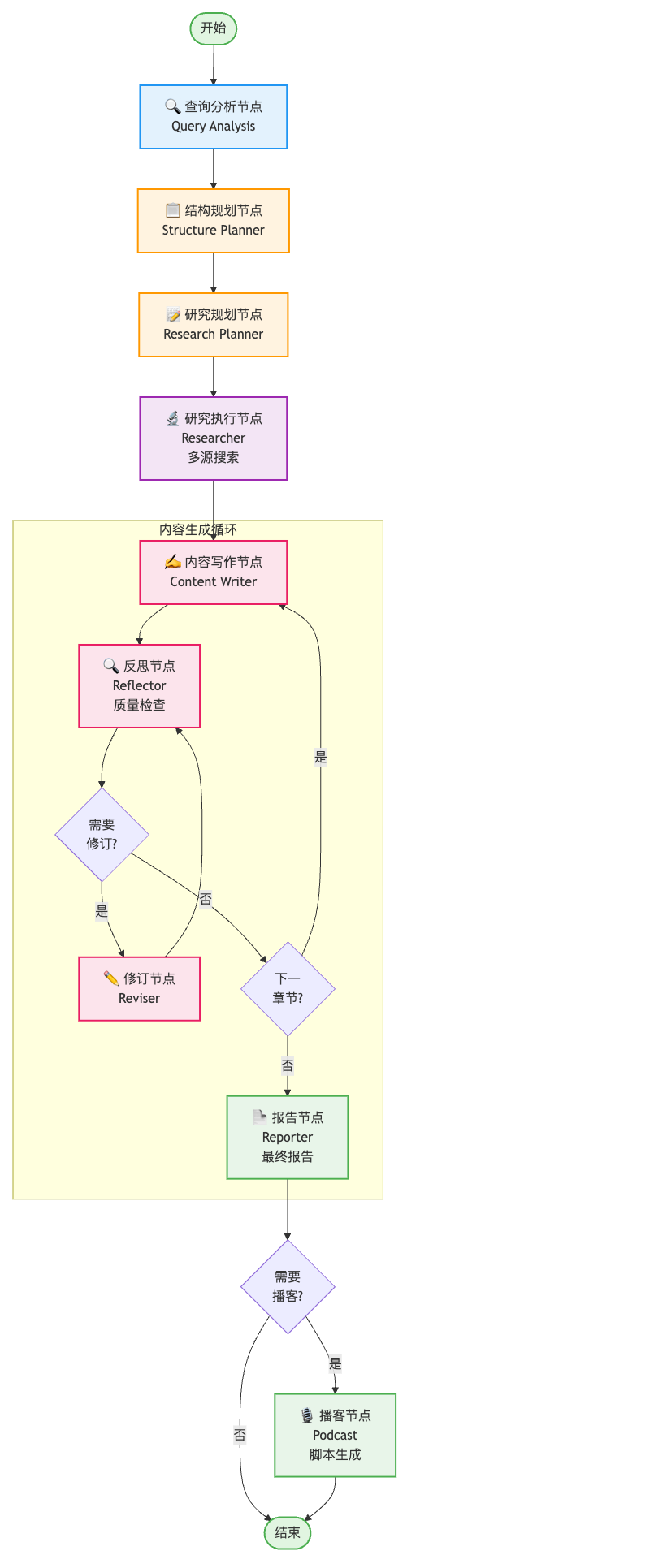
工程开发
报告中缺乏图表,可以加强数据的采集和图表的展示。
报告中缺乏图片的润色,网上搜索的图片经常文不对题,不过我已经有方案了。
参考资料:
