Go 网络编程,大家第一反应就是 gopacket。但如果你用过 Scapy,你会发现 gopacket 的 API 繁琐得让人抓狂。goscapy 把 Scapy 的优雅搬到了 Go 里——流式构建、自动校验和、协议自动推断、一行代码搞定数据包,还能嗅探、发送、收响应。
最早接触到python生态圈的scapy是两年前,在和交换机的同学搞交换机探针的时候,他写了几行python代码就实现了一个发包探测程序,我立马就被scapy吸引了,居然写网络测试程序可以这么简单?
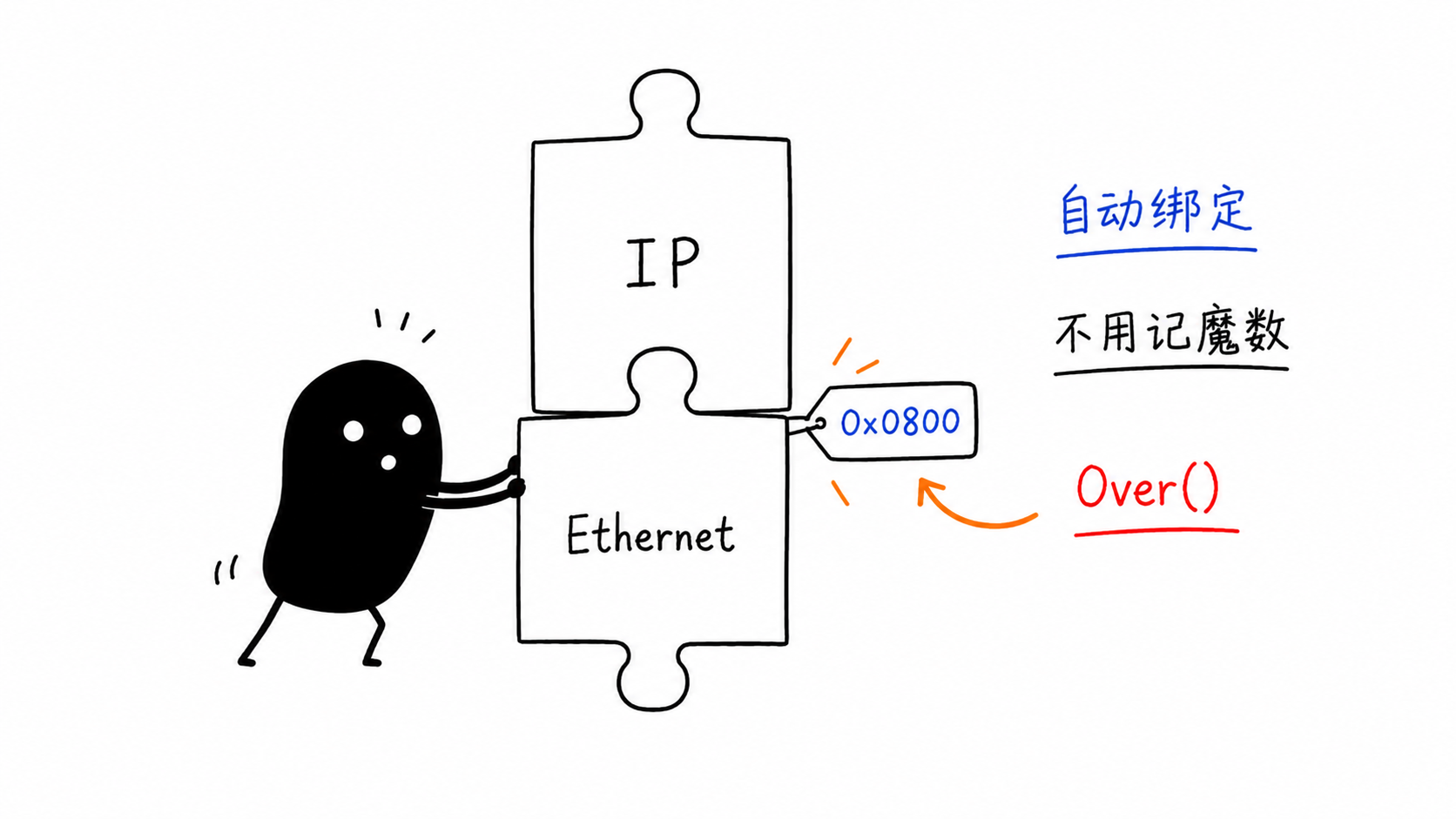
03 数据包解析:自动协议推断
构造包只是故事的一半,解析包是另一半。
goscapy 的 Dissect 能从原始字节自动推断出完整的协议栈:
1
2
3
4
5
6
7
| raw := []byte{0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xaa, 0xbb, ...}
pkt, _ := packet.DissectByProto(raw, "Ethernet")
fmt.Println(pkt.String())
ipLayer := pkt.GetLayer("IP")
srcIP, _ := ipLayer.Get("src")
|
解析引擎靠注册表驱动。每一层解析完后,查 keyField 找到下一层——Ethernet 看看 type 字段(0x0800 → IP),IP 看看 proto 字段(6 → TCP),TCP 看看 dport(80 → HTTP)。VXLAN 这种隧道协议还能递归解析内层包,最多支持 8 层嵌套。
启发式规则也注册了一大堆:UDP 53 端口 → DNS,TCP 80 → HTTP,UDP 4789 → VXLAN,IP proto 47 → GRE……抓到的包基本都能自动识别到应用层。

04 嗅探和收发包:Scapy 的 sr/srp 到 Go
写过 Scapy 的人一定对 sr() 和 sr1() 不陌生——发一个包,自动等响应,还能做协议级匹配。goscapy 把这套逻辑完整搬过来了。
发包
1
2
3
4
5
6
7
8
9
|
pkt := goscapy.NewEthernet().
DstMAC("ff:ff:ff:ff:ff:ff").
Over(goscapy.NewIP().SrcIP("192.168.1.1").DstIP("8.8.8.8")).
Over(goscapy.NewICMP().Type(8).Code(0)).
Packet()
sendrecv.Send(pkt, "eth0")
sendrecv.Sendp(pkt, "eth0")
|
发包收响应
1
2
3
4
5
6
|
sent, reply, err := sendrecv.Sr1(pkt, "eth0", 3*time.Second, nil)
if reply != nil {
ipLayer := reply.GetLayer("IP")
srcIP, _ := ipLayer.Get("src")
}
|
DefaultMatch 自动匹配响应包——ICMP Echo Request 配 Echo Reply(ID 匹配),TCP SYN 配 SYN-ACK(端口翻转 + ack = seq+1),UDP 配端口翻转,DNS 匹 transaction ID,ARP 配 IP 交换。不用写一行匹配逻辑。

gopacket 更适合:需要解析冷门协议、对 pcap 文件读写有强需求、已经重度依赖 libpcap 生态的项目。
goscapy 更适合:网络工具开发、安全扫描、协议测试、网络监控探测——任何需要快速构造和收发数据包的场景。纯 Go 部署简单,API 用起来舒服。
10 性能:零拷贝序列化
goscapy 在序列化上做了不少优化:
SerializeInto:直接写入目标 buffer,无额外堆分配BuildInto:用户提供 buffer,整个包一次序列化完成RecvInto:收包直接读入用户 buffer,减少一次拷贝- 校验和零拷贝:
checksumIPv4Pseudo 直接折叠多个内存区域,不拼接
WireSize:预计算序列化大小,一次分配精确大小的 buffer
1
2
3
|
buf := make([]byte, 1500)
result, err := pkt.BuildInto(buf)
|
还有 Linux 特有的高性能接收模式——AF_PACKET mmap、零拷贝 (PACKET_QDISC_BYPASS)、io_uring 原始套接字——适合高频探测场景。这些在 examples 目录里有完整示例(23-packet-mmap、21-zerocopy、22-uring-raw-socket)。
11 丰富的示例库
goscapy 自带了 50+ 个示例,覆盖从基础到高级的几乎所有场景:
- 基础:ping、traceroute、TCP SYN 扫描、ARP 扫描
- 协议:DNS 客户端、DHCP 客户端、NTP 客户端
- 隧道:VXLAN 封装、GRE 隧道、ERSPAN
- 高级:PCAP 读写、TCP 流重组、BPF 过滤
- 性能:零拷贝收包、io_uring、packet mmap、批量发送
- 无线:802.11 WiFi 帧、蓝牙 HCI/L2CAP、Zigbee、LoRaWAN
- 安全:p0f 指纹、端口扫描、ARP 扫描
每个示例都是可编译运行的小程序,直接 go run 就能跑。
项目地址:github.com/smallnest/goscapy
纯 Go,MIT 协议,零 C 依赖。go get github.com/smallnest/goscapy 就能用。
如果你在做网络工具、安全扫描、协议测试、监控探测——试试 goscapy,可能会让你重新爱上 Go 网络编程。