treap 是一棵二叉树,它同时维护二叉搜索树 (BST) 和堆的属性, 所以由此得名 (tree + heap ⇒ treap)。
从形式上讲,treap (tree + heap) 是一棵二叉树,其节点包含两个值,一个 key 和一个 priority ,这样 key 保持 BST 属性,priority 是一个保持 heap 属性的随机值(至于是最大堆还是最小堆并不重要)。相对于其他的平衡二叉搜索树,treap的特点是实现简单,且能基本实现随机平衡的结构。属于弱平衡树。
treap 由 Raimund Siedel 和 Cecilia Aragon 于 1989 年提出。
treap 通常也被称为“笛卡尔树”,因为它很容易嵌入到笛卡尔平面中:
具体来说,treap 是一种在二叉树中存储键值对 (X,Y) 的数据结构,其特点是:按 X 值满足二叉搜索树的性质,同时按 Y 值满足二叉堆的性质。如果树中某个节点包含值 (X₀,Y₀),那么:
左子树中所有节点的X值都满足 X ≤ X₀ (BST 属性)
右子树中所有节点的X值都满足 X₀ ≤ X (BST 属性)
左右子树中所有节点的Y值都满足 Y ≤ Y₀ (堆属性。这里以最大堆为例)
在这种实现中, X是键(同时也是存储在 Treap 中的值),并且 Y称为优先级 。如果没有优先级,则 treap 将是一个常规的二叉搜索树。
优先级(前提是每个节点的优先级都不相同)的特殊之处在于:它们可以确定性地决定树的最终结构(不会受到插入数据顺序的影响)。这一点是可以通过相关定理来证明的。
Treap维护堆性质的方法用到了旋转,且只需要进行两种旋转操作,因此编程复杂度较红黑树、AVL树要小一些。
红黑树的操作:插入 以最大堆为例
如果当前节点的优先级比父节点大就进行2. 或3. 的操作
如果当前节点是父节点的左子叶就右旋
如果当前节点是父节点的右子叶就左旋。
删除
因为 treap满足堆性质,所以只需要把要删除的节点旋转到叶节点上,然后直接删除就可以了。具体的方法就是每次找到优先级最大的子叶,向与其相反的方向旋转,直到那个节点被旋转到了叶节点,然后直接删除。
查找
和一般的二叉搜索树一样,但是由于 treap的随机化结构,Treap中查找的期望复杂度是 O(logn)
以上是 treap 数据结构的背景知识,如果你想了解更多而关于 treap 的知识,你可以参考
Go 运行时的 treap 和用途 在 Go 运行时 sema.go#semaRoot 中,定义了一个数据结构 semaRoot:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 type semaRoot struct { lock mutex treap *sudog nwait atomic.Uint32 } type sudog struct { g *g next *sudog prev *sudog elem unsafe.Pointer acquiretime int64 releasetime int64 ticket uint32 isSelect bool success bool waiters uint16 parent *sudog waitlink *sudog waittail *sudog c *hchan }
这是Go语言互斥锁(Mutex)底层实现中的关键数据结构,用于管理等待获取互斥锁的goroutine队列。我们已经知道,在获取 sync.Mutex 时,如果锁已经被其它 goroutine 获取,那么当前请求锁的 goroutine 会被 block 住,就会被放入到这样一个数据结构中 (所以你也知道这个数据结构中的 goroutine 都是唯一的,不重复)。
semaRoot 保存了一个平衡树,树中的 sudog 节点都有不同的地址 (s.elem) ,每个 sudog 可能通过 s.waitlink 指向一个链表,该链表包含等待相同地址的其他 sudog。对具有相同地址的 sudog 内部链表的操作时间复杂度都是O(1).。扫描顶层semaRoot列表的时间复杂度是 O(log n) ,其中 n 是具有被阻塞goroutine的不同地址的数量(这些地址会散列到给定的semaRoot)。
semaRoot 的 treap *sudog 其实就是一个 treap, 我们来看看它的实现。
增加一个元素(入队) 增加一个等待的goroutine(sudog)到 semaRoot 的 treap 中,如果 lifo 为 true,则将 s 替换到 t 的位置,否则将 s 添加到 t 的等待列表的末尾。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 func (root *semaRoot) uint32 , s *sudog, lifo bool ) { s.g = getg() s.elem = unsafe.Pointer(addr) s.next = nil s.prev = nil s.waiters = 0 var last *sudog pt := &root.treap for t := *pt; t != nil ; t = *pt { if t.elem == unsafe.Pointer(addr) { if lifo { *pt = s s.ticket = t.ticket ... } else { if t.waittail == nil { t.waitlink = s } else { t.waittail.waitlink = s } t.waittail = s s.waitlink = nil if t.waiters+1 != 0 { t.waiters++ } } return } last = t if uintptr (unsafe.Pointer(addr)) < uintptr (t.elem) { pt = &t.prev } else { pt = &t.next } } s.ticket = cheaprand() | 1 s.parent = last *pt = s for s.parent != nil && s.parent.ticket > s.ticket { if s.parent.prev == s { root.rotateRight(s.parent) } else { if s.parent.next != s { panic ("semaRoot queue" ) } root.rotateLeft(s.parent) } } }
① 是遍历 treap 的过程,当然它是通过搜索二叉树的方式实现。 addr就是我们一开始讲的treap的key,也就是 s.elem。addr 已经在 treap 中,如果存在,那么就把 s 加入到 addr 对应的 sudog 链表中,或者替换掉 addr 对应的 sudog。
这个addr, 如果对于sync.Mutex来说,就是 Mutex.sema字段的地址。
1 2 3 4 type Mutex struct { state int32 sema uint32 }
所以对于阻塞在同一个sync.Mutex上的goroutine,他们的addr是相同的,所以他们会被加入到同一个sudog链表中。sync.Mutex锁,他们的addr是不同的,那么他们会被加入到这个treap不同的节点。
进而,你可以知道,这个rootSema是维护多个sync.Mutex的等待队列的,可以快速找到不同的sync.Mutex的等待队列,也可以维护同一个sync.Mutex的等待队列。
③就是设置这个节点的优先级,它是一个随机值,用于保持treap的平衡。这里有个技巧就是总是把优先级最低位设置为1,这样保证优先级不为0.因为优先级经常和0做比较,我们将最低位设置为1,就表明优先级已经设置。
④ 就是将这个新加入的节点旋转到合适的位置,以保持treap的平衡。这里的旋转操作就是上面提到的左旋和右旋。稍后看。
移除一个元素(出队) 对应的,还有出对的操作。这个操作就是从treap中移除一个节点,这个节点就是一个等待的goroutine(sudog)。
dequeue 搜索并找到在semaRoot中第一个因addr而阻塞的goroutine。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 func (root *semaRoot) uint32 ) (found *sudog, now, tailtime int64 ) { ps := &root.treap s := *ps for ; s != nil ; s = *ps { if s.elem == unsafe.Pointer(addr) { goto Found } if uintptr (unsafe.Pointer(addr)) < uintptr (s.elem) { ps = &s.prev } else { ps = &s.next } } return nil , 0 , 0 Found: ... if t := s.waitlink; t != nil { *ps = t ... } else { for s.next != nil || s.prev != nil { if s.next == nil || s.prev != nil && s.prev.ticket < s.next.ticket { root.rotateRight(s) } else { root.rotateLeft(s) } } if s.parent != nil { if s.parent.prev == s { s.parent.prev = nil } else { s.parent.next = nil } } else { root.treap = nil } tailtime = s.acquiretime } ... return s, now, tailtime }
① 是遍历 treap 的过程,当然它是通过搜索二叉树的方式实现。 addr就是我们一开始讲的treap的key,也就是 s.elem。如果找到了,就跳到 Found 标签。如果没有找到,就返回 nil。
④是检查这个地址上是不是有多个等待的goroutine,如果有,就把这个节点替换成链表中的下一个节点。把这个节点从treap中移除并返回。
这里的旋转操作就是上面提到的左旋和右旋。
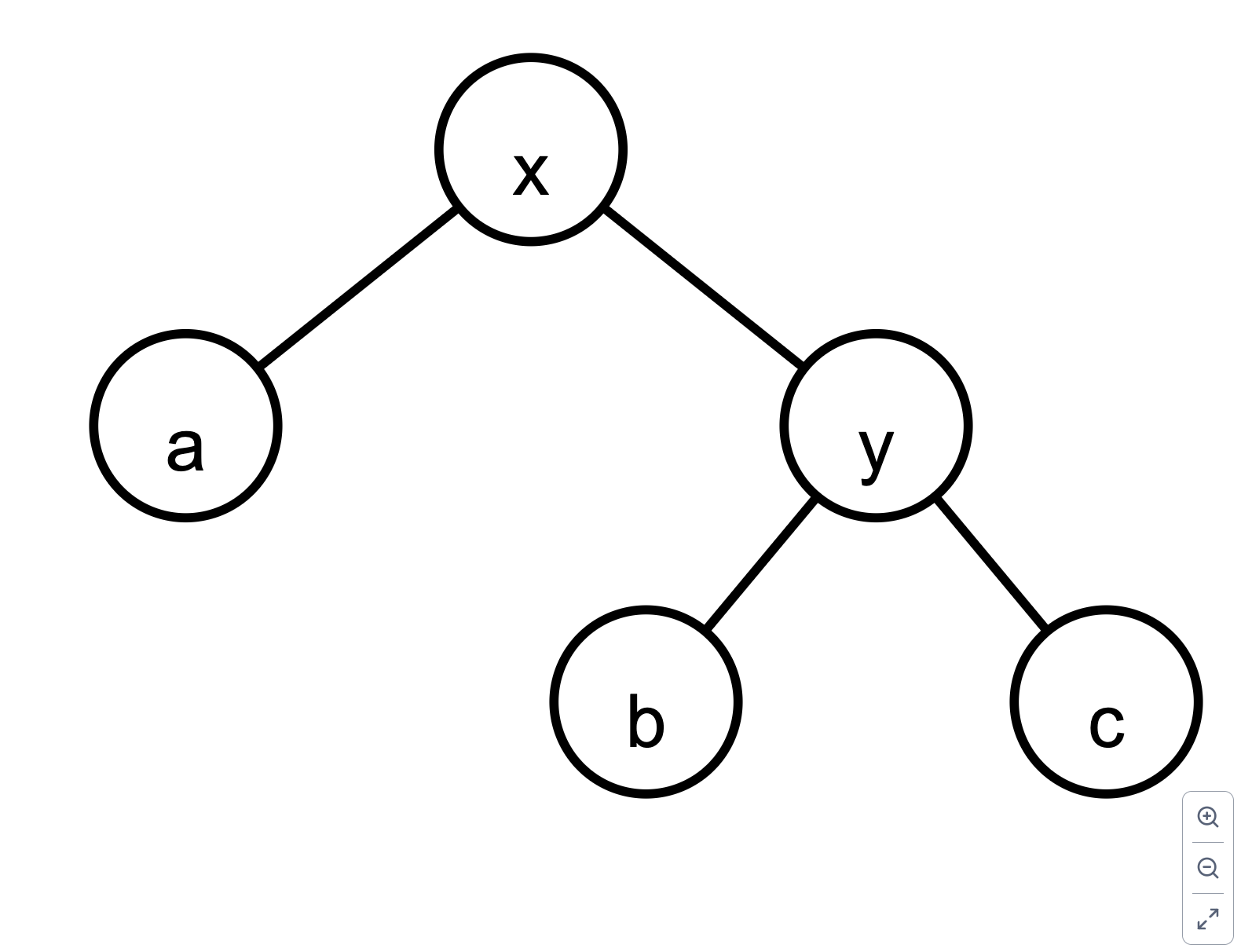
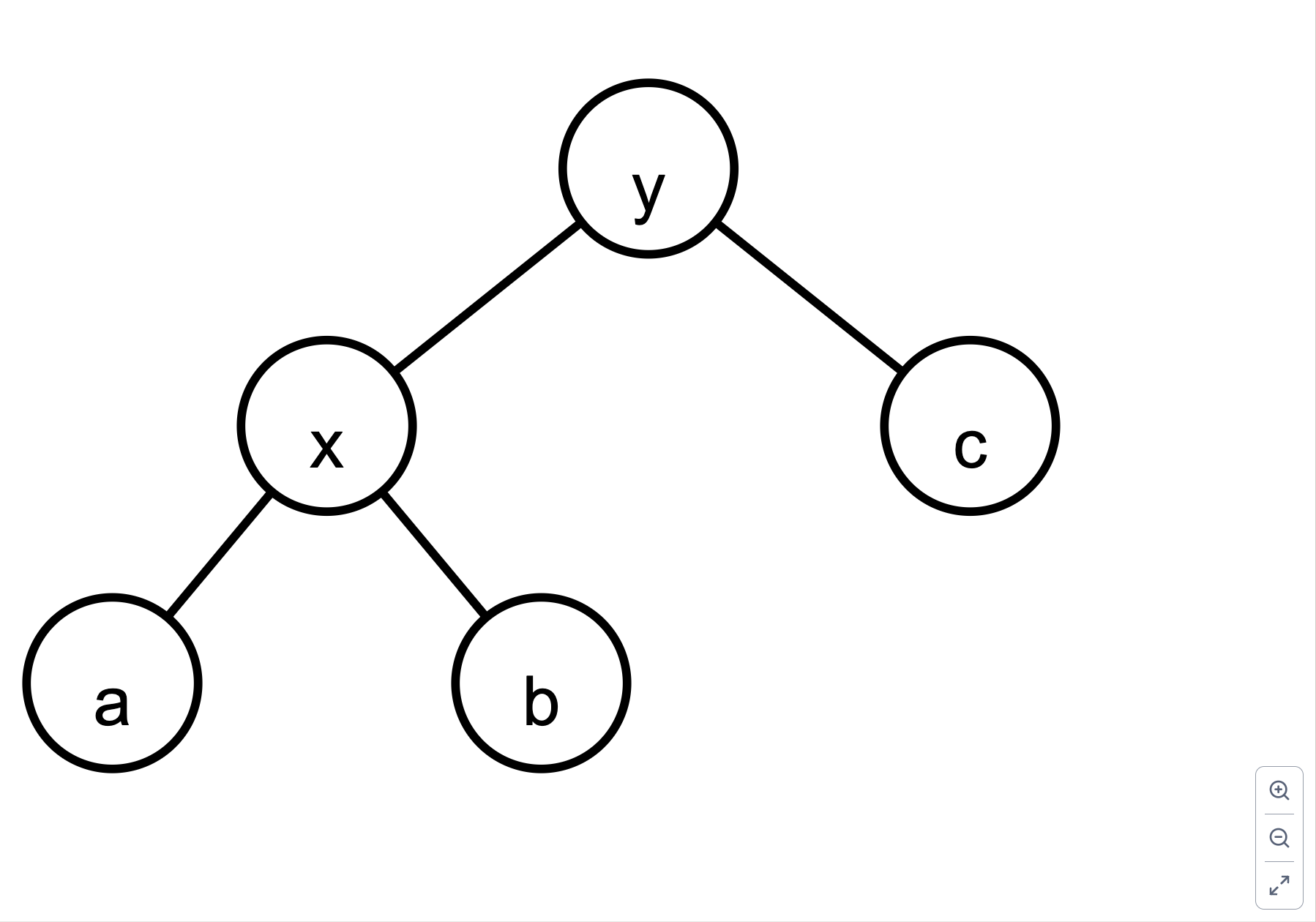
左旋 rotateLeft rotateLeft 函数将以 x 为根的子树左旋,使其变为 y 为根的子树。(x a (y b c)),旋转后变为 (y (x a b) c)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 func (root *semaRoot) p := x.parent y := x.next b := y.prev y.prev = x x.parent = y x.next = b if b != nil { b.parent = x } y.parent = p if p == nil { root.treap = y } else if p.prev == x { p.prev = y } else { if p.next != x { throw("semaRoot rotateLeft" ) } p.next = y } }
具体步骤:
将 y 设为 x 的父节点(②),x 设为 y 的左子节点(①)。
将 b 设为 x 的右子节点(③),并更新其父节点为 x(④)。
更新 y 的父节点为 p(⑤),即 x 的原父节点。如果 p 为 nil,则 y 成为新的树根(⑥)。
根据 y 是 p 的左子节点还是右子节点,更新对应的指针(⑦)。
左旋为
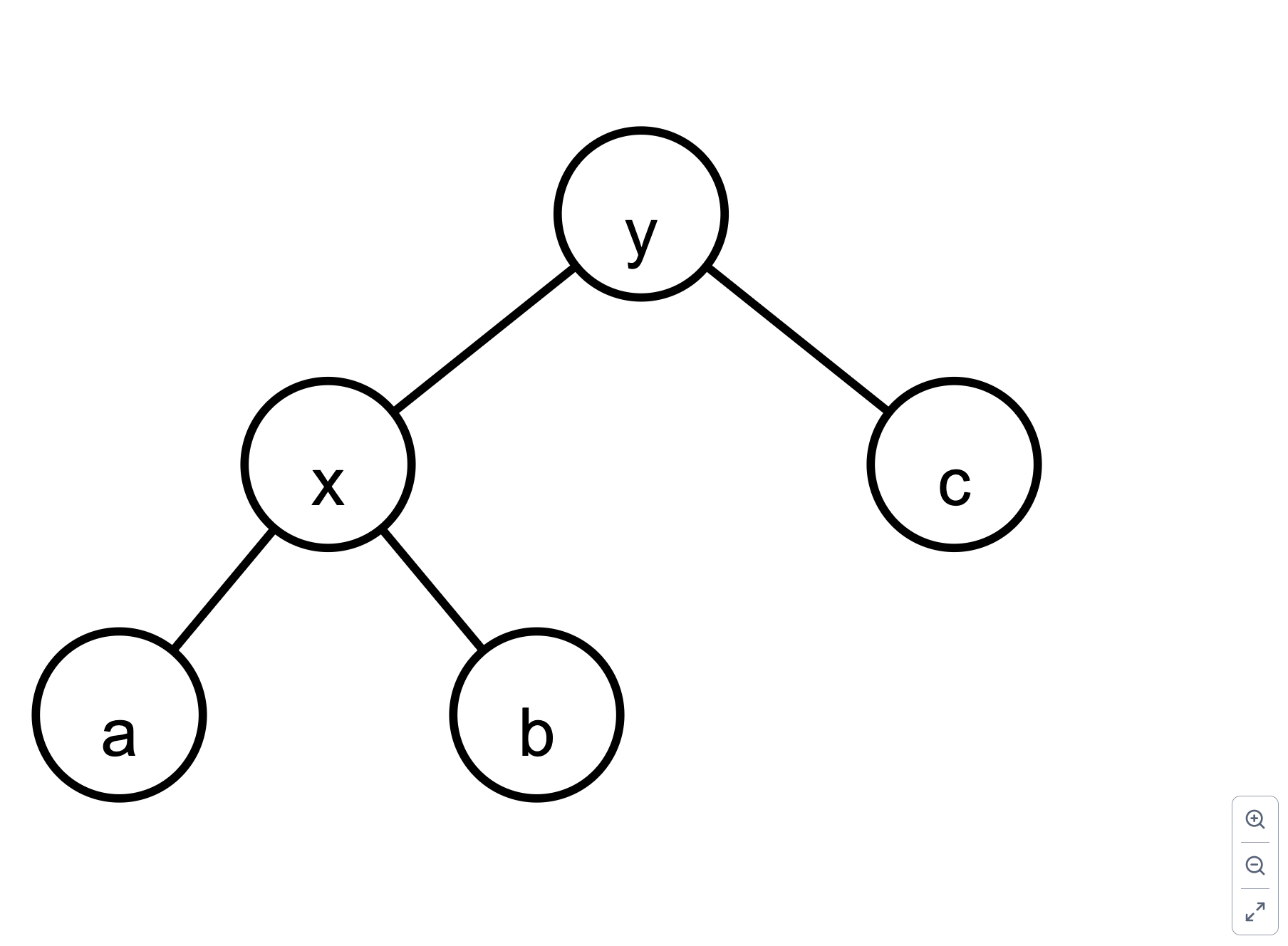
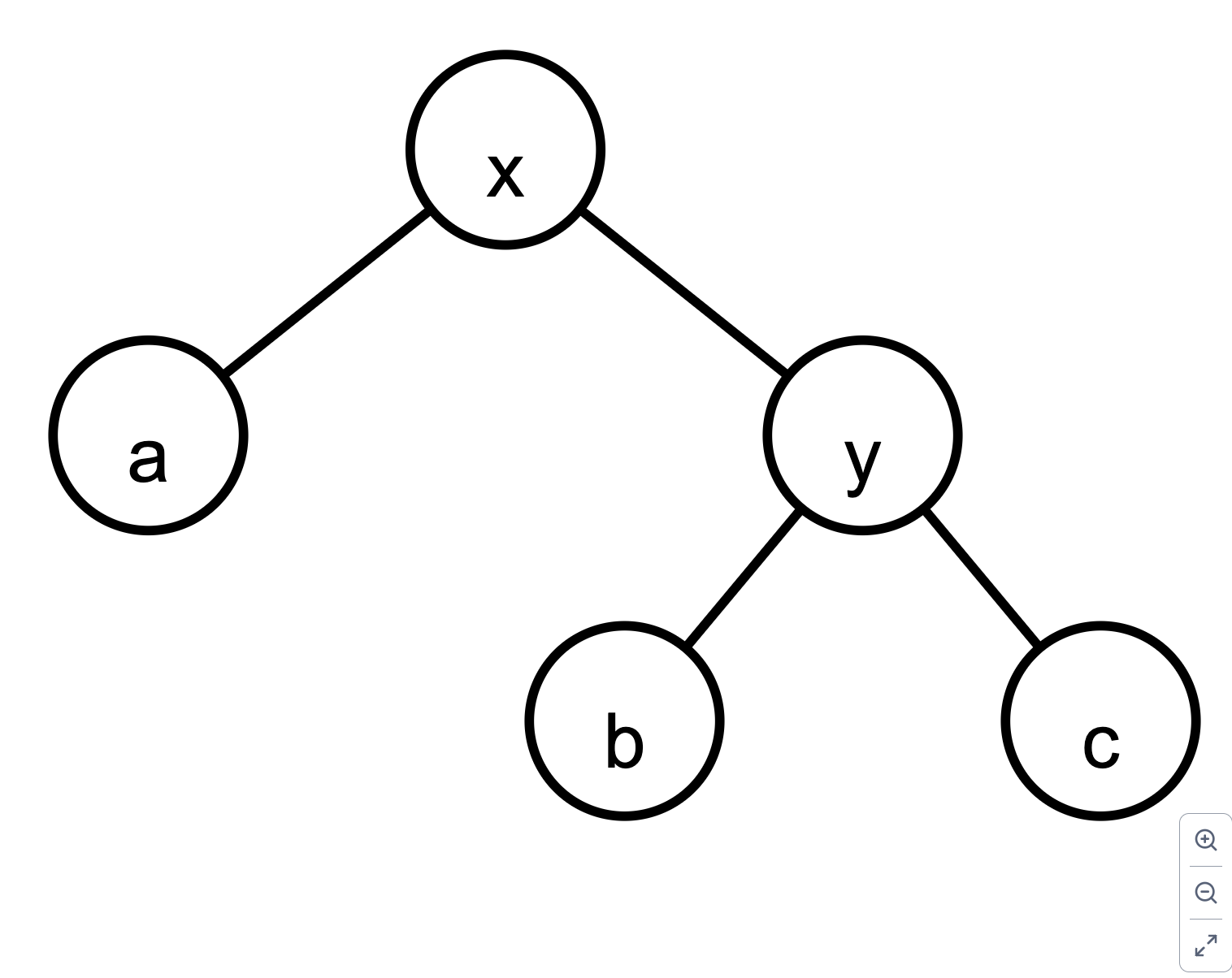
右旋 rotateRight rotateRight 旋转以节点 y 为根的树。(y (x a b) c) 变为 (x a (y b c))。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 func (root *semaRoot) p := y.parent x := y.prev b := x.next x.next = y y.parent = x y.prev = b if b != nil { b.parent = y } x.parent = p if p == nil { root.treap = x } else if p.prev == y { p.prev = x } else { if p.next != y { throw("semaRoot rotateRight" ) } p.next = x } }
具体步骤:
将 y 设为 x 的右子节点(①), x 设为 y 的父节点(②)
将 b 设为 y 的左子节点(③),并更新其父节点为 y(④)
更新 x 的父节点为 p(⑤),即 y 的原父节点。如果 p 为 nil,则 x 成为新的树根(⑥)
根据 x 是 p 的左子节点还是右子节点,更新对应的指针(⑦)
右旋为
理解了左旋和右旋,你就理解了出队代码中这一段为什么把当前节点旋转到叶结点中了:
1 2 3 4 5 6 7 8 for s.next != nil || s.prev != nil { if s.next == nil || s.prev != nil && s.prev.ticket < s.next.ticket { root.rotateRight(s) } else { root.rotateLeft(s) } }
整体上看,treap这个数据结构确实简单可维护。左旋和右旋的代码量很少,结合图看起来也容易理解。 出入队的代码也很简单,只是简单的二叉搜索树的操作,加上旋转操作。
这是我介绍的Go秘而不宣的数据结构第三篇,希望你喜欢。你还希望看到Go运行时和标准库中的哪些数据结构呢,欢迎留言。
我会不定期的从关注者列表并点赞文章的同学中选出一位,送出版商和出版社的老师赠送的书,欢迎参与。