最近在设计一个多分区多副本的消息系统,以前对kafka有一些了解,在阅读了阿里的RocketMQ、小米的Pegasus等分布式系统后,再仔细阅读的kafka的复制设计,整理出本篇文档,可以和其它系统做一个对比。
Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
- 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能。
- 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
- 支持通过Kafka服务器和消费机集群来分区消息。
- 支持流式处理。
7年过去了, kafka已经成为一个羽翼丰满的发布订阅平台、消息存储、流处理的工具。财富500强企业中有三分之一的公司使用了kafka平台。也就是在昨天(2017年11月1日),kafka发布了它的1.0.0版本。
本文主要参考了Jun Rao(饶军)的Intra-cluster Replication in Apache Kafka, Jun Rao毕业于清华大学,哥读到博士,后来在IBM、LinkedIn工作,在LinkedIn期间任Kafka组的技术leader。2014年Kafka一帮人成立了Confluent公司,推广Kafka的商业应用,Jun Rao是共同创始人。
复制提供了高可用, 即使有些节点出现了失败:
- Producer可以继续发布消息
- Consumer可以继续接收消息
有两种方案可以保证强一致的数据复制: primary-backup replication 和 quorum-based replication。两种方案都要求选举出一个leader,其它的副本作为follower。所有的写都发给leader, 然后leader将消息发给follower。
基于quorum的复制可以采用raft、paxos等算法, 比如Zookeeper、 Google Spanner、etcd等。在有 2n + 1个节点的情况下,最多可以容忍n个节点失败。
基于primary-backup的复制等primary和backup都写入成功才算消息接收成功, 在有n个节点的情况下,最多可以容忍n-1节点失败,比如微软的PacifiaA。
这两种方式各有优缺点。
1、基于quorum的方式延迟(latency)可能会好于primary-backup,因为基于quorum的方式只需要部分节点写入成功就可以返回。
2、在同样多的节点下基于primary-backup的复制可以容忍更多的节点失败,只要有一个节点活着就可以工作。
3、primary-backup在两个节点的情况下就可以提供容错,而基于quorum的方式至少需要三个节点。
Kafka采用了第二种方式,也就是主从模式, 主要是基于容错的考虑,并且在两个节点的情况下也可以提供高可用。
万一一个节点慢了怎么办?首先这种情况是很少发生的,万一发生了可以设置timeout参数处理这种情况。
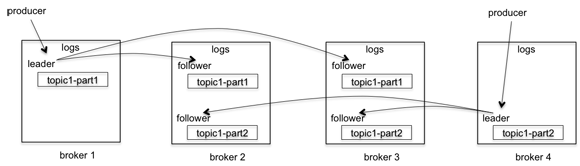
kafka的复制是针对分区的。比如上图中有四个broker,一个topic,2个分区,复制因子是3。当producer发送一个消息的时候,它会选择一个分区,比如topic1-part1分区,将消息发送给这个分区的leader, broker2、broker3会拉取这个消息,一旦消息被拉取过来,slave会发送ack给master,这时候master才commit这个log。
这个过程中producer有两个选择:一是等所有的副本都拉取成功producer菜收到写入成功的response,二是等leader写入成功就得到成功的response。第一个中可以确保在异常情况下不丢消息,但是latency就下来了。后一种latency提高很多,但是一旦有异常情况,slave还没有来得及拉取到最新的消息leader就挂了,这种情况下就有可能丢消息了。
一个Broker既可能是一个分区的leader,也可能是另一个分区的slave,如上图所示。
kafka实际是保证在足够多的slave写入成功的情况下就认为消息写入成功,而不是全部写入成功。这是因为有可能一些节点网络不好,或者机器有问题hang住了,如果leader一直等着,那么所有后续的消息都堆积起来了, 所以kafka认为只要足够多的副本写入就可以饿。那么,怎么才认为是足够多呢?
Kafka引入了 ISR的概念。ISR是in-sync replicas的简写。ISR的副本保持和leader的同步,当然leader本身也在ISR中。初始状态所有的副本都处于ISR中,当一个消息发送给leader的时候,leader会等待ISR中所有的副本告诉它已经接收了这个消息,如果一个副本失败了,那么它会被移除ISR。下一条消息来的时候,leader就会将消息发送给当前的ISR中节点了。
同时,leader还维护这HW(high watermark),这是一个分区的最后一条消息的offset。HW会持续的将HW发送给slave,broker可以将它写入到磁盘中以便将来恢复。
当一个失败的副本重启的时候,它首先恢复磁盘中记录的HW,然后将它的消息truncate到HW这个offset。这是因为HW之后的消息不保证已经commit。这时它变成了一个slave, 从HW开始从Leader中同步数据,一旦追上leader,它就可以再加入到ISR中。
kafka使用Zookeeper实现leader选举。如果leader失败,controller会从ISR选出一个新的leader。leader 选举的时候可能会有数据丢失,但是committed的消息保证不会丢失。
Leader failure
There are 3 cases of leader failure which should be considered -
- The leader crashes before writing the messages to its local log. In this case, the client will timeout and resend the message to the new leader.
- The leader crashes after writing the messages to its local log, but before sending the response back to the client
Atomicity has to be guaranteed: Either all the replicas wrote the messages or none of them
The client will retry sending the message. In this scenario, the system should ideally ensure that the messages are not written twice. Maybe, one of the replicas had written the message to its local log, committed it, and it gets elected as the new leader. - The leader crashes after sending the response. In this case, a new leader will be elected and start receiving requests.
When this happens, we need to perform the following steps to elect a new leader.
1.Each surviving replica in ISR registers itself in Zookeeper.
2. The replica that registers first becomes the new leader. The new leader chooses its LEO as the new HW.
3. Each replica registers a listener in Zookeeper so that it will be informed of any leader change. Everytime a replica is notified about a new leader:
If the replica is not the new leader (it must be a follower), it truncates its log to its HW and then starts to catch up from the new leader.
4. The leader waits until all surviving replicas in ISR have caught up or a configured time has passed. The leader writes the current ISR to Zookeeper and opens itself up for both reads and writes.
(Note, during the initial startup when ISR is empty, any replica can become the leader.)
参考文档
- https://www.confluent.io/blog/apache-kafka-goes-1-0/
- https://engineering.linkedin.com/kafka/intra-cluster-replication-apache-kafka
- https://cwiki.apache.org/confluence/display/KAFKA/Kafka+Replication
- Intra-cluster Replication in Apache Kafka
- Kafka Tutorial - Fault Tolerance
- https://dzone.com/articles/kafka-topic-architecture-replication-failover-and
- http://meuslivros.github.io/kafka/ch04s04.html
- https://www.confluent.io/blog/hands-free-kafka-replication-a-lesson-in-operational-simplicity/
- https://engineering.linkedin.com/kafka/benchmarking-apache-kafka-2-million-writes-second-three-cheap-machines
- https://www.confluent.io/product/multi-datacenter/
