他把 Karpathy 的自动研究方法搬到了软件开发领域,然后离开了电脑
一位中国开发者借鉴人工智能先驱的思路,让多个 AI 智能体在无人监督的情况下自主完成代码编写、审核与合并。
撰文 / 2026年5月
三月的一个深夜,旧金山,Andrej Karpathy 在 GitHub 上发布了一个仅 600 行 Python 代码的项目。他没有召开新闻发布会,没有录制精心编排的产品演示,只在仓库里放了一份简洁的说明文档和一段不到十分钟的介绍视频。
几天之内,这个名为 AutoResearch 的项目收获了超过 5 万个星标。那段视频的播放量攀升至 860 万次。
Karpathy 的构想直截了当:让一个 AI 智能体在单张 GPU 上自主运行机器学习实验。它会修改训练代码,跑一个五分钟的快速实验,然后检查一个名为 val_bpb 的验证指标。如果指标改善了,就提交这次修改;如果没有,就回滚,一切归零,重新来过。
整个过程不需要人类参与。不需要审批会议,不需要代码审查,不需要凌晨三点被叫醒检查训练曲线。Agent 自己提出假设,自己执行实验,自己判断结果——然后自己决定是保留还是丢弃。
几个小时之内,它可以完成大约十二次这样的实验循环。一觉醒来,你可能会发现模型变好了。也可能发现一切毫无进展,但至少你没有浪费自己的时间。
一个念头
远在太平洋另一侧,一位名叫 smallnest 的中国开发者在看到这个项目后,产生了一个想法。
"Karpathy 在机器学习领域验证了一个核心机制——量化目标加上自主循环,只保留改进,退化就回滚,"他在后来的一篇文章中写道。"我开始思考:软件开发领域能否复刻同样的魔法?"
这是一个大胆的问题。机器学习的质量评估相对简单——val loss 下降就是好,不下降就是不好。软件工程则完全不同:一段代码可能功能正确但结构混乱,可能安全合规但性能低下,可能测试充分但命名糟糕。"代码好不好"从来不是一个数字能回答的问题。
但 smallnest 认为,或许可以把它变成一个数字能回答的问题。
他的思路是这样的:把 Karpathy 的"修改 train.py → 跑五分钟实验 → val loss 改善才保留",替换成"实现 GitHub Issue → 跑测试 → 多维评分达标才合并"。
如果 Karpathy 用一个指标衡量机器学习实验的成败,那他就用五个维度衡量一段代码的质量:正确性占 35%,测试覆盖占 25%,代码质量占 20%,安全性占 10%,性能占 10%。五个维度加权计算,总分 100 分制,只有达到 85 分才算通过。
低于 85 分?不合并,不妥协。反馈驱动下一轮改进,继续迭代,直到达标或者系统判断这个问题暂时无解。

两个 Agent 的故事
但 smallnest 做了一件 Karpathy 没有做的事。
AutoResearch 是一个 Agent 自我循环——自己改代码,自己评估结果,自己决定保留还是回滚。这在机器学习领域可以接受,因为 metric 是客观的、无情的、不带偏见的。val loss 降了就是降了,争论没有意义。
软件开发不行。一个 Agent 审核自己写的代码,就像一个学生给自己的考试打分——你可以相信诚实的自我评估,但你不应该指望它能发现所有的错误。
smallnest 引入了第二个 Agent。
在他的系统中,三个 AI Agent——OpenAI 的 Codex、Anthropic 的 Claude 和开源的 OpenCode——轮流担任实现者和审核者。奇数轮,Codex 先审核代码再实现功能,Claude 再审核 Codex 的实现并补充自己的方案。偶数轮,角色互换。OpenCode 作为第三方力量,在关键节点提供独立视角。每个 Agent 在审核对方的工作时都会从自己的视角发现问题,而不同模型的盲区各不相同。
后来他在 README 中写道:"Codex 可能忽略一个边界条件的处理,Claude 可能没有注意到一个性能隐患,OpenCode 又可能从完全不同的角度审视问题。当它们交叉审核时,一个的盲区往往恰好是另一个的强项。"
与此同时,评分标准也在实践中得到了校准。最初他设定了 9.0/10 的达标线,但经过更多实验后,他将阈值调整为 85/100——一个更务实的数字,既保持了质量门槛,又给 Agent 留下了足够的改进空间。他还加入了一个 -c(continue)模式:当一轮迭代未能达标时,系统可以选择继续当前会话而不是重新开始,保留已有的上下文和进展。
这种设计让他想起了一个更早的实验。2025 年底,澳大利亚开发者 Geoffrey Huntley 在博客上发表了一篇题为《Ralph Wiggum》的文章,提出了一种激进的方法:写一份详细的功能规格文档(PRD),然后让一个 AI Agent 在无限循环中自主工作——自己写代码,自己跑测试,自己修复问题。人类只需要写好那份规格文档,然后就可以离开。
这个想法后来被开发者 snarktank 正式实现为开源项目 ralph。Ralph 的设计比 Huntley 最初的 bash 一行命令精巧得多:它把 PRD 拆分为结构化的用户故事(user stories),存储在 prd.json 文件中。每一轮迭代,Ralph 启动一个全新的 AI 实例——干净上下文,没有历史包袱——让它实现一个用户故事,然后运行类型检查和测试。如果通过,就更新 prd.json 标记为完成;如果不通过,就保持原状,下一轮换一个全新的 Agent 重试。
Ralph 最值得注意的设计是它的记忆模型。尽管每一轮迭代的 Agent 都是全新实例,但系统通过四条通道保持知识积累:Git 历史记录了所有代码变更;progress.txt 以追加模式记录每轮迭代的学习心得;prd.json 跟踪哪些故事已经完成;而 AGENTS.md 文件则充当了一种目录级别的知识库——Agent 在每轮结束后把发现的模式、陷阱和约定写入这个文件,后续迭代的 Agent(以及人类开发者)都能自动读取这些经验。
但 Ralph 的局限也很明显:它是单 Agent 自审——同一个 Agent 写代码、跑测试、判断通过与否,没有外部审核视角。质量完全取决于测试的覆盖面和规格文档的严谨程度。
smallnest 认为这不是最优解。"实践中我们发现,单 Agent 的效果远不如双 Agent 对抗,"他说。这是他在文章中为数不多的带有个人判断的陈述之一。大部分时候,他更喜欢用数据说话。

十分钟
理论听起来优雅。但在软件工程领域,优雅的理论和可运行的系统之间往往隔着一道深不见底的鸿沟。
smallnest 用一个真实的 GitHub Issue 做了验证。
Issue #21 要求为一个名为 Job 的结构体添加三个功能:Agent 选择、超时控制和自动重试。系统评估这是一个中等复杂度的任务——涉及结构体扩展、超时控制逻辑和 API 增强。
他输入了 Issue 编号。然后,他离开了。

系统开始了第一轮迭代。Codex 被要求审核并实现这个功能。它读取了项目代码,理解了 Job 结构体的设计,然后——什么也没做。第一轮评分:1.0 分。功能完全未实现。
在 Karpathy 的 AutoResearch 中,这样的结果会触发一次 git revert,实验重置。但在 smallnest 的系统中,这个"失败"不是终点,而是反馈。审核 Agent 记录下了第一轮的具体问题:代码只读取了结构,没有做任何修改。这份反馈被原封不动地传递给下一轮的 Agent。
第二轮,Claude 接手。这一次,超时控制逻辑被实现了,API 也做了增强。Claude 的审核者发现了进展,但仍指出了一些不足。评分:5.0 分。距离 9.0 的达标线还很远,但方向是对的。
反馈再次传递。第三轮,Codex 拿着前两轮的审核记录再次出发。这一次,它补全了缺失的测试用例,修复了边界条件处理,完善了错误信息的上下文。
评分:9.0 分(90/100)。
系统自动执行 git commit、创建 Pull Request、合并代码。整个流程无需人工确认。从开始到结束,大约十分钟。
时间戳显示,这个过程从 17:38 开始,17:47 结束。三次迭代,最终评分超过 85 分的达标线。
递归
smallnest 没有止步于一个 Issue。他开始把 AutoResearch 推向更远的地方——不只是修修补补,而是从零开始建造。
他试了三件事。
第一件:把 AutoResearch 用在新项目的开发上。不是在已有代码库上修 Bug 或加功能,而是面对一个空目录,从第一行代码开始。这完全改变了问题的性质。AutoResearch 最初是为"处理 GitHub Issue"设计的——Issue 天然有明确的需求描述和验收标准。但一个全新项目没有 Issue,只有一个人脑中的模糊构想。smallnest 需要先把构想拆解为一组结构化的 Issue,然后才能按下启动键。这迫使他思考一个更根本的问题:在多大程度上,"写清楚你想要什么"本身就是编程?
第二件:让 AutoResearch 开发自己。这是一个递归的实验——用自动化工具来改进自动化工具本身。他把 AutoResearch 的代码库当作一个普通项目,创建 Issue 描述想要改进的功能,然后让系统自己处理。三个 AI Agent 阅读 AutoResearch 的源码,理解它的架构,提出修改方案,互相审核,然后合并。一个由 AI 编写的改进,被另一个 AI 审核,然后自动合入——改进的对象恰好是协调这一切的系统本身。这听起来像是一个科幻故事的设定,但它确实在运行。
第三件最为出人意料。他用 AutoResearch 开发了一个叫 DoubleTake 的项目——一个"谁是卧底"命令行网络游戏。
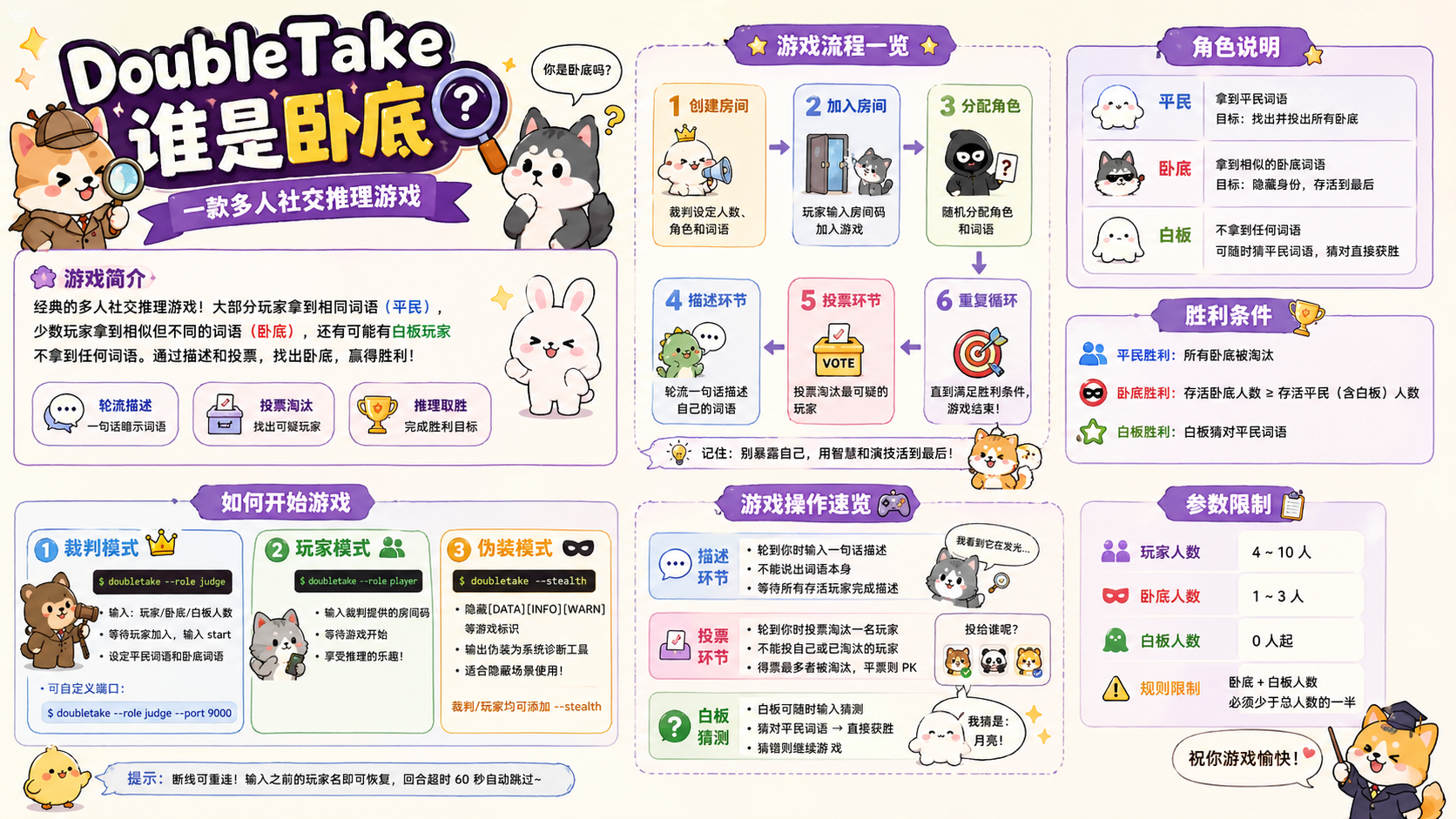
"谁是卧底"是一款在中国流传极广的聚会游戏:每位玩家拿到一个词,大多数人是平民拿到同一个词,少数人是卧底拿到一个相似但不同的词,偶尔还有人什么都不拿。大家轮流用一句话描述自己的词,然后投票淘汰最可疑的人。平民要找出卧底,卧底要活到最后。
DoubleTake 是这个游戏的命令行实现——没有图形界面,没有手机 App,只有终端窗口和键盘。它采用客户端-服务器架构:一台机器当裁判,其他机器当玩家,通过局域网联机。支持四到十人游戏,支持一到三个卧底,支持白板玩家,支持断线重连,甚至还有一个 --stealth 伪装模式,把游戏输出伪装成系统诊断工具的格式——据说是为了让你在看起来像在工作的终端里偷偷玩游戏。
这个项目的有趣之处不在于游戏本身,而在于它是怎么被写出来的。一个涉及网络编程、并发处理、游戏状态管理的完整项目——包含客户端、服务器、游戏逻辑、命令行交互——不是由一个程序员坐在电脑前一行行敲出来的,而是由 AutoResearch 的三个 AI Agent 通过 Issue 驱动逐步构建的。人类定义了"我要一个谁是卧底游戏",然后离开了。回来的时候,代码已经写好了。
宪法
smallnest 的系统有一个核心文件,他称之为 program.md。这个文件定义了 AI Agent 可以做什么、不可以做什么,以及代码必须遵循的规范。
他使用了"宪法"这个词。这不是一个随意的比喻。在法律体系中,宪法是一切规则的规则——它不直接管理日常事务,但它界定了所有其他规则的有效边界。program.md 在他的系统中扮演了同样的角色。
Agent 可以修改源代码目录,可以创建测试文件,可以运行测试和代码检查工具。但 Agent 不可以修改依赖管理文件,不可以删除任何现有文件,不可以推送到远程仓库,不可以关闭 Issue,不可以修改 autoresearch 目录中的规则文件。
这些限制不是出于对 AI 的不信任,而是出于对系统复杂性的尊重。一个小小的 autoresearch 项目牵涉到 Git 操作、GitHub API 调用、多个 AI Agent 的协调、测试框架的运行——任何一个环节的失控都可能产生连锁反应。宪法的作用是在创新和稳定之间划出一条清晰的边界。

并非所有问题都适合交给机器
smallnest 很清楚,不是所有的 GitHub Issue 都应该交给 AI 处理。
他设计了一套筛选机制。系统会先排除那些标记为"不会修复""重复""无效""需要讨论"的 Issue,排除标题包含"进行中"或"草稿"的条目,排除正文写明"请勿实现"的请求,排除已经有 PR 关联的任务。
然后,它根据优先级标签、问题类型和创建时间计算一个分数。关键缺陷的权重高于新功能请求,新创建的 Issue 权重高于积压两年的老问题。
最后,系统评估复杂度。修复一个拼写错误?预算三轮迭代,十分钟。添加一个新功能模块?预算五轮,半小时。重新设计系统架构?预算五轮,一小时。
这是一个务实的框架。它承认 AI Agent 在处理简单的、边界清晰的任务时表现优秀,但在面对需要大量设计决策的复杂架构问题时可能力不从心。它不试图用自动化解决所有问题,而是精确地界定自动化的适用范围。
三万人
smallnest 把项目开源了。他给它取了一个和 Karpathy 一样的名字——AutoResearch——然后把它放到了 GitHub 上。
第一天,三万人来了。
他们不是被营销吸引来的。没有广告,没有推广帖子,没有精心策划的发布日程。他们是因为看到了一个演示——一个 AI 自主处理 GitHub Issue、写代码、审核、合并的全流程录屏——然后点进了仓库。三万人,二十四小时之内。
对于一个没有背景音乐、没有花哨界面的开源开发者工具来说,这个数字是罕见的。它说明了一件事:有一大批开发者正在等待这样的工具。不是等待某个具体的软件产品,而是等待一种可能性——离开电脑,代码照写的可能性。
但真正的考验不在 GitHub。
后来,smallnest 做了一件比开源更难的事:他把 AutoResearch 搬进了百度。
百度不是 GitHub。一家拥有数万名工程师的互联网公司有一套完全不同的基础设施——代码托管在 iCode 上,项目跟踪在 iCafe 上,开发工具使用 Ducc 。这些系统经过多年打磨,彼此深度耦合,任何外部工具想要接入都必须穿越一层又一层的 API 和权限体系。更重要的是,百度的工程师们已经形成了自己的工作流。你不可能要求他们为了一个实验性工具改变习惯。
smallnest 没有要求任何人改变习惯。他做的是适配——让 AutoResearch 的核心循环(提出方案、实现代码、审核评分、自动合并)跑在百度的基础设施之上。iCode 替代了 GitHub 作为代码仓库,iCafe 替代了 GitHub Issues 作为任务来源,Ducc 替代了传统的配置文件管理。对百度的工程师来说,界面没变,流程没变,变的是幕后——有些 Issue 的处理速度突然快了很多。
开源社区也在生长。一位贡献者为项目添加了对小米大模型 MIMO 的支持,这意味着除了 OpenAI 和 Anthropic 的商业模型之外,国产大模型也能参与 AutoResearch 的多 Agent 循环。另一位贡献者接入了阿里云效平台——一条从开源社区到企业内部的桥梁。
这些贡献看似零散,但它们指向同一个方向:AutoResearch 正在从一个个人实验项目,变成一个可以被不同团队、不同公司、不同基础设施适配的通用框架。核心循环不变——量化目标、自动迭代、只保留改进——但外面那一层壳可以是 GitHub,可以是百度 iCode,也可以是任何一家公司内部的研发平台。
三个项目,同一颗心脏
smallnest 的项目并不是 Karpathy AutoResearch 思想在软件开发领域的唯一回响。
一位网名为"花叔"的开发者几乎在同时创建了"达尔文.skill"——一个将同样的自动优化循环应用于 AI 技能(Skill)开发的项目。花叔的格言颇有诗意:"女娲造 Skill,达尔文让 Skill 进化。"
与 Karpathy 和 smallnest 的项目不同,达尔文.skill 优化的不是代码或训练参数,而是提示词——那些用来指导 AI 行为的自然语言指令。它用一套精密的八维度评估体系替代了 val loss:前六个维度评估结构质量(完整性、清晰度、可执行性、一致性、鲁棒性和可维护性),满分 60 分;后两个维度评估实际效果(效果达成度和效率),满分 40 分。总分 100 分,结构分与效果分各占其重。
达尔文.skill 最独特的设计是它的"棘轮机制"(Ratchet Mechanism)——每一轮迭代中,只有当新版本的得分严格高于上一轮时,才会被保留。这个名字来自机械学中的棘轮:只能向前转动,不能倒退。这和 Karpathy 的"val loss 改善才保留"是同一思路,但达尔文.skill 在每一轮优化后都暂停,等待人类确认。花叔把这称为"人在回路"——人类不必参与每一行提示词的编写,但最终的审美判断仍然属于人。
三个项目——Karpathy 的 AutoResearch、smallnest 的 AutoResearch for Development、花叔的达尔文.skill——形成了一条有趣的演进线。它们的核心机制相同:量化目标、自动迭代、只保留改进。但在被优化的资产、质量保证的机制、以及人类参与的程度方面,每个项目都做出了不同的选择。
Karpathy 的系统最简单也最决绝:一个指标,一个 Agent,完全无人监督。它的哲学是信任数学——val loss 不会说谎。
smallnest 的系统居中:多个维度,多个 Agent 交叉审核,大部分自动化但在关键节点保留了人类介入的能力。它信任的是 AI 之间的制衡——用 Claude 审核 Codex,用 Codex 审核 Claude,用 OpenCode 提供第三方视角。他在 README 中将这种方法与 Ralph 做了一个直接对比:"autoresearch 信任 LLM 的判断力(通过评分),Ralph 信任工具链(测试和 lint)。autoresearch 没有跨迭代的记忆,Ralph 有四通道的知识持久化。autoresearch 是端到端的(从 Issue 到 PR 到合并),Ralph 只做到代码完成。"
花叔的达尔文.skill 最谨慎:八个维度,双重评估(结构加效果),每轮暂停等待人类确认。它信任的是人——让机器做探索,让人类做裁决。

Karpathy 的项目可以完全自主运行,因为机器学习的 metric 足够客观。花叔的项目每轮暂停等待人类确认,因为 AI 技能的好坏最终需要人的主观判断。smallnest 的项目居于两者之间——大部分自动化,但通过多 Agent 交叉审核和可调的评分阈值(85/100)来平衡自主性和质量。
这种差异并非偶然。它反映了一个更深层的问题:在什么场景下,我们可以信任机器自主判断"什么是好的"?机器学习有 val loss 作为几乎无争议的度量标准。软件工程试图用多维度加权评分加上多 Agent 交叉审核来近似同样的客观性。AI 技能的开发者则认为,至少在目前,人类的判断仍然不可替代。三个项目,三种对"信任"的回答。
离开电脑
smallnest 的文章以一个简洁的表格结束。表格对比了五种开发方式:传统开发、AI 辅助编程、Ralph Wiggum 方法、Karpathy 的 AutoResearch,以及他自己的项目。
在表格的最后一行,他列出了一个问题:"离开电脑后?"
传统开发,停。AI 辅助编程,停。Ralph Wiggum,继续跑。Karpathy AutoResearch,继续跑。他的项目,继续跑。
这是一个令人不安的表格。它暗示着一个正在发生的变化:软件开发正在从一种必须由人类持续参与的活动,转变为一种可以被描述、被参数化、然后被委托给机器执行的流程。
当然,事情远没有这么简单。smallnest 的系统目前只能处理边界清晰的、中等复杂度的 GitHub Issue。面对需要深度架构思考或复杂业务逻辑的任务,它仍然力不从心。它的评分体系虽然试图量化代码质量,但 85 分的代码并不一定比 80 分的代码在真实世界中更好用。三个 AI Agent 的交叉审核减少了盲区,但没有消除盲区。系统没有跨迭代的记忆——每一轮都是一次新的对话,不记得上一轮学到了什么,除非通过反馈文件显式传递。
但这些局限性并不妨碍这个实验的意义。它提出了一个根本性的问题:如果软件开发可以被分解为"明确目标、自动执行、量化评估、只保留改进"的循环,那么人类开发者的角色会发生什么变化?
Karpathy 用 600 行代码证明了机器学习研究可以自动化。smallnest 用一个 shell 脚本和三个 AI Agent 证明了软件开发至少可以部分自动化。花叔证明了 AI 技能的优化同样可以遵循类似的模式——棘轮机制,只进不退。
三位开发者,三个领域,同一套方法论。目标量化,循环自主,只保留改进。人类设定边界,机器在边界内自由探索。
然后,人类离开电脑。
回来的时候,代码可能已经写好了。
