上一个工具 bitflip/baize 解决的是丢包和改包持续检测,在百度baize常常用在点到点之间的常态检测中,比如机房内集群间的监控,专线的检测, 新网络方案测试和灰度观察、核心网络设备的切回前检测等场景。
今天介绍的lidar工具,区别于传统的pingmesh探测方案,是我来百度后创造的第一个特殊的底层网络方案,我将其称之为lidar(激光扫描)方案,是一个很形象的比喻,我会话专门一节详细介绍它的优缺点,在这之前,我们介绍传统的赫赫有名的机房大规模的网络监控方案 pingmesh。
pingmesh 探测以及为什么我们不用它?
PingMesh("Pingmesh: A Large-Scale System for Data Center Network Latency Measurement and Analysis")是微软在SIGCOMM 2015上发表的论文。作者团队来自微软研究院和Azure网络部门。
一句话概括:在所有服务器之间互相ping,测量每一对服务器之间的延迟和丢包,然后做异常检测和根因定位。
听起来很笨。几千台服务器,两两之间全部ping一遍,消息复杂度 O(n²),谁敢这么干?
微软敢,而且早在2015年之前就已经在全量数据中心里跑了。当前他们也做了一些优化,实际并不是所有的服务器之间fullmesh探测,只是保证同一层级之间的设备之间fullmesh,比如同一层级的IB之间的设备都互有探测。
论文作者大部分是微软研究院的。其中最值得关注的是几位:
- Chuanxiong Guo(郭传雄):微软研究院资深研究员,PingMesh是他主导的项目之一。后来曾任字节跳动人工智能实验室(AI Lab)总监,2022年因对数据中心网络设计的贡献当选IEEE Fellow,在数据中心网络领域有较高知名度。2023离开字节创业。
- Lihua Yuan:微软Azure网络团队核心成员,今年四月去了OpenAI。他和团队把PingMesh从论文推进到了Azure全量部署。
- 其他几位作者现在散落各大厂——Google、Meta等等。PingMesh的影响力从作者们的去向就能看出来,论文里的思想被带着在各个云厂商落地。
你可以从微软网站上下载这篇经典论文,它提供了一个很好的设计和分析网络故障的方案,它的探测分析图也深深影响我设计lidar的分析方法。
这个pingmesh设计也没众多的云厂商使用并演化,比如腾讯等,几乎成了机房内网络监控的标配。
百度也在2016年开发了类似的监控系统 netradar, 使用常态的TCP Client/Server进行探测, 支撑了百度网络的黑盒监控多年,不过在我来百度的时候相关的开发人员基本都走了,系统也面临的众多的问题:
- 常态机房间和机房内都超过了阈值,大盘是常态飘红
- 准确率不足,要么是误报、要么是漏报
- 时效性太慢,基本2,3分钟才可能有告警
- TCP的重试机制会导致偶发丢包发现不了
- 误告严重,经常服务器的上下线就导致了误报。尤其6.18、双十一这些节日涉及到大量的服务器的上下线
还有一个重要的问题,一旦Agent有个bug修复或者想扩展一个功能,全网所有的服务器要升级一遍的话,至少需要一个季度才能完成,甚至半年,因为需要小范围的灰度才能逐步的扩展,还得涉及到变更窗口的审批,另外RD和运维也很痛苦,因为这些变更都
lidar 探测
2020/2021年,百度迫切需要一个高时效高准确率的黑盒探测方案,去面对日益增长的云客户的对故障发现和处理的业务需求。
我恰巧刚刚来到百度,我还是第一次接触到众多的网络概念:机房、交换机、路由器、CLOS架构、骨干网、ADC、DC、IB、IC、TOR、ECMP等,对我来说一切都很新奇。面对当前探测的需求,我初始的想法是在前人的基础上(netradar)优化,先来快速解决当前棘手的问题。也做了一些尝试、比如netradar探测频率的提升、聚合程序整体引流和替换等等,在两三个月之后,虽然比最初的情况好些了,但是还是没有从根因上解决问题。
同时,我们团队也在研发骨干网的监控,在百度称之为B1的网络。当时我设计一个我称之为『sonar』的探测方案,采用UDP + Rawsocket的方式构造不同的五元组进行探测,为了解决rawsocket性能低下的问题(它会拦截和复制服务器全部的UDP包),我也是各大论坛寻师问友,后来在slack有人告诉我可以使用bpf,基本上单个服务器rawsocket可以达到6万pps不丢包的性能,当然如果不使用rawsocket而是采用普通的UDP服务器,可以稳定实现80万pps的探测频率,但是又没办法实现狗构造成千上万的PPS。 这都是我们在前期的一些经验的总结,也很有意思,这些都是工程化的过程中才可能获得的宝贵经验,最终我们同学在这个方案的基础上实现了B1骨干网的监控,而且效果非常不错。
这给我了很大的信心。也就是我们也能根据百度自己的网络特点,设计出符合我们自己的网络监控方案。下一步就是解决DCN的网络监控了,我准备替换netradar。彼时netradar还没有移交到我这边的团队。设计的最重要的一点,就是可以快速的验证和部署,时不我待,当时的情况和压力已经不允许我们花半年的时间才去部署一套还不确定的探测方案。
和pingmesh不同,lidar采用一台探测机就可以探测机房内所有的服务器。作为冗余和交叉验证,我们采用机房内一台探测机,机房外一台探测机。如果资源充足,探测机的数量再多一些就更好。
这台探测机从topo数据库中拉取服务器信息,然后选取高质量的服务器作为目标服务器,通过发送TCP SYN包就】进行探测。测试效果不错,后来我们基于这个方案实现了机房内的网络探测1.0。
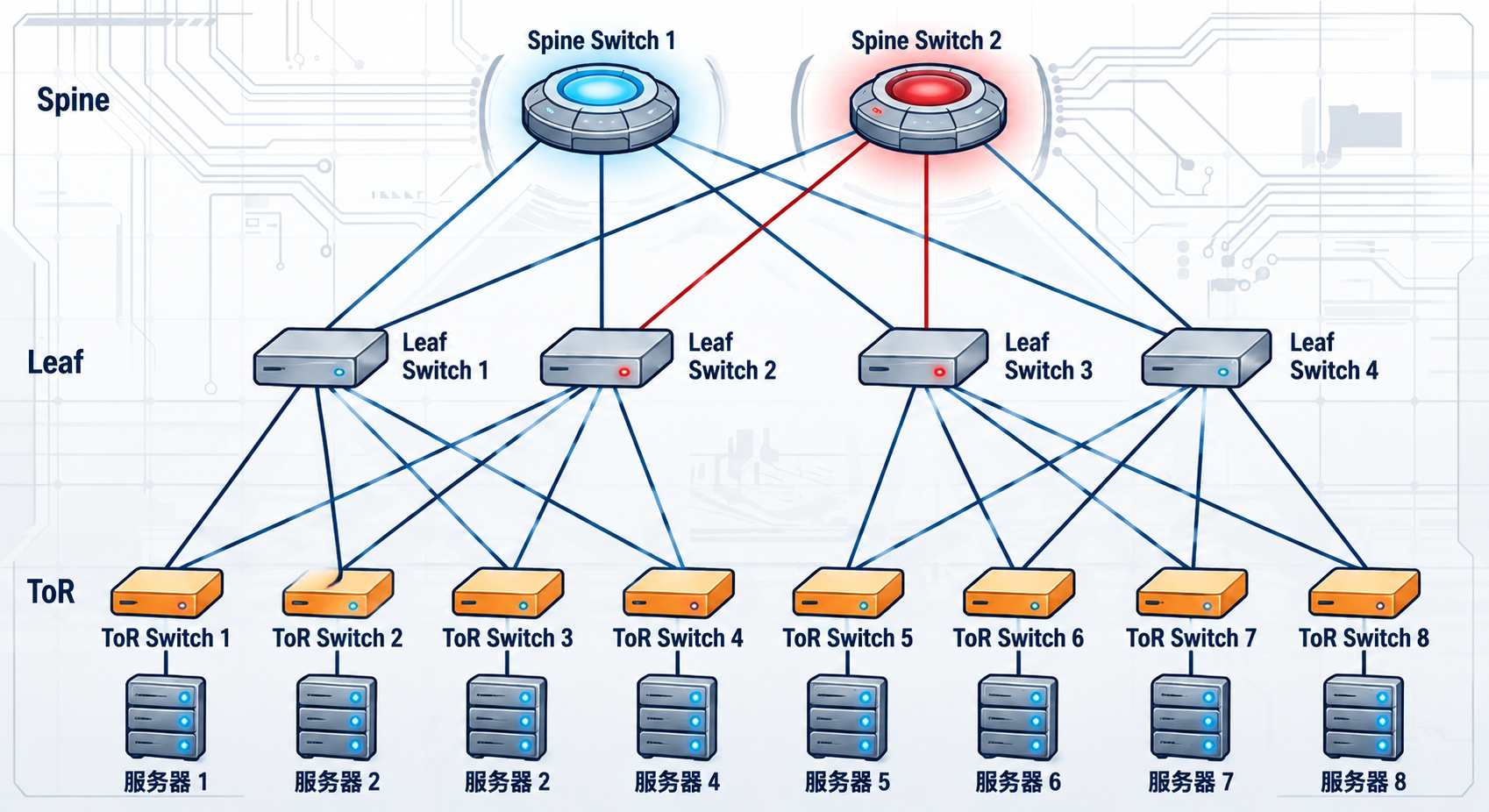
我们以这个简易的网络架构为例。我们在服务器1部署lidar探测程序,它去探测其他服务器的447端口。实际上我们还会从其他机房不是一个探测程序,探测这个机房的这些服务器。
这样,我们在很短的时间就完成了开发工作并部署,并又花了一个季度的时间进行打磨和调优,当然这些优化我们可以快速的进行更新部署,一次变更就完成了。
原理:三种响应,一个答案
lidar 发一个 SYN 出去,目标的内核 TCP 协议栈会自动响应——这是 TCP 协议栈的底层行为,不需要安装任何软件。也是大家都已经熟悉的三次握手阶段的第一步。
收到什么,就知道什么状态:
| 响应 | 含义 |
|---|---|
| SYN-ACK | 端口开放,服务正常 |
| RST | 端口关闭或被防火墙拒绝,但网络连通 |
| 没响应 | 不可达,或中途丢包 |
就这么简单。不需要 agent,不需要 server 端部署,不需要任何配置。给个 IP 和端口,立刻告诉你结果。
当前最好的方式是探测一个监听的端口,比如 ssh 端口 22等。
实际测试探测一个不存在的端口,有些服务器并不会为每一个SYN请求都返回一个RST,导致误报。
即使是探测一个监听的端口,服务器上可能设置了防止SYN Flooding攻击的策略,也不允许你高频的探测,实际在 20 ~ 100 PPS之间是合理的。
输出长这样:
1 | 21:37:14, [192.168.1.14 -> 74.48.173.243], sent: 10, received: 10 (SYN-ACK: 10, RST: 0), timeout: 0 |
每秒一个统计窗口,sent/received/SYN-ACK/RST/timeout 一目了然。丢包了打 [WARN],正常打 [INFO]。
你会不会担心服务器建立很多的半连接的TCP,会不会影响性能。实际是不会的,首先服务器有防止SYN Flooding的策略,如果收到太多的SYN会丢弃的,其次为了避免被策略丢弃,我们针对每台服务器的探测频率并不是很高,基本上在20pps ~ 100pps之间。
虽然单个服务器才100pps,但是因为一个TOR下我们会选取至少三台服务器,所以只对这些服服务器连接的ToR,它的探测频率是哦300pps, 如果更往上一层Leaf设备,它的探测频率又是几十倍,更往上Spine设备和DC,那探测频率是几万pps到几十万pps了。所以这种方式层级越高,探测的精度越高。
同时,还有一个很有意思的现象:在建立TCP握手的时候,目标服务器不是回传一个TCP+SYN的响应吗,探测服务器收到这个响应,发现它本机并没有监听这个端口(我们使用rawsocket进行旁路处理的),然后TCP/IP协议栈就会自动发一个RST给目标服务器,目标服务器就会把这个半连接关闭掉。所以实际上,这个半连接很快就被关闭了。这都是自动的。
macOS 和 Linux 的收包差异,踩了坑
lidar 的开发过程中,最头疼的不是发包,是收包。
发 SYN 用 raw socket(SOCK_RAW + IPPROTO_RAW + IP_HDRINCL),macOS 和 Linux 行为一致,一套代码搞定。
收包就不一样了。
Linux 上,raw socket(SOCK_RAW + IPPROTO_TCP)直接就能收到 TCP 响应包。内核处理 TCP 的同时,会把副本投递给 raw socket。简单直接。
macOS 上,同样的代码,一个包都收不到。
原因是 macOS 的内核 TCP 协议栈会"拦截"TCP 报文。raw socket 注册了 IPPROTO_TCP,但内核觉得"这是我的 TCP 连接",不给 raw socket 副本。BPF 设备(Berkeley Packet Filter)是唯一的出路——在链路层抓包,绕过 TCP 协议栈。
1 | // macOS: 打开 /dev/bpf* 设备,在链路层抓包 |
拿到的是原始链路层帧,带 14 字节的以太网头。得手动剥离,再解析 IP 和 TCP。
Linux 上拿到的直接就是 IP 包,没有链路层头。同一套解析逻辑,入口不同。
| macOS | Linux | |
|---|---|---|
| 收包方式 | BPF 设备(链路层抓包) | raw socket |
| 数据格式 | 以太网头 + IP + TCP | IP + TCP |
| 为什么 | 内核 TCP 栈拦截,raw socket 拿不到 | 内核投递副本给 raw socket |
这是两个操作系统内核的设计差异,没有谁对谁错。但写代码的人得知道。
我们内部都是Linux服务器,所以没有这个问题,但是开源的版本我希望更通用些,方便使用苹果本的同学也能测试和使用,所以代码做了兼容。
在高吞吐服务器上,BPF 过滤器救了命
Linux 上用 raw socket 收包有个隐患:SOCK_RAW + IPPROTO_TCP 会收到所有 TCP 报文。
在万兆网卡、几十万 pps 的服务器上,内核会把海量无关的 TCP 包拷贝到用户态,导致性能低下,吞吐率不高设置丢包。
解法是内核层过滤。SO_ATTACH_FILTER 挂载一个 classic BPF(cBPF)程序,在内核里就把不相关的包丢掉,只投递匹配探测端口的报文:
1 | A = packet[14] & 0x0f * 4 // 从 IP IHL 算 TCP 头偏移 |
12 条 cBPF 指令,硬编码在代码里。内核只把匹配的极少数报文投递上来,用户态几乎零开销。
1 | func buildBPFProbeFilter(serverPort int, srcPort uint16, portCount uint16) []sendrecv.BPFInstruction { |
源端口轮转,覆盖 ECMP 多路径
和 bitflip 一样,lidar 也面临多路径覆盖的问题。
两个固定 IP 之间,TCP 五元组如果固定(源端口不变),哈希结果始终相同,永远只走一条链路。怎么覆盖所有可能路径?
lidar 的做法是源端口轮转。每次发完一轮(所有目标各发一个 SYN),源端口 +1。配置了 100 个源端口,就跑 100 轮,每条可能的 ECMP 路径都有概率被覆盖到。
1 | // 每轮所有目标各发一个 SYN 后,源端口 +1 |
这不是完美的"全覆盖"——你没法精确知道哪个端口走哪条路——但 100 个源端口在统计意义上足够覆盖典型的多路径拓扑。
用起来
1 | # 探测单个目标的 80 端口 |
也支持配置文件:
1 | { |
1 | sudo ./lidar -c lidar.json |
三个工具,三件不同的事
bitflip 做 UDP 丢包和改包检测,baize 做常态的丢包和改包检查,lidar 做 TCP SYN 端口可达性探测。三个工具解决的问题不同,但底层技术栈是相通的:raw socket 构造报文、BPF 过滤收包、时间桶统计、速率控制。
注意, lidar没办法进行改包检测,你知道为什么吗?所以下一个要开源的工具是mping。
冷知识
最早是从radar这个名字开始,为我们的工具起名 sonar、lidar。
后来我们的平台就用中国古代神话人物和神兽命令:比如离娄、白泽和飞鸿。
这只是 nettools 的冰山一角。后续还有网关设备监控、evr的监控工具、定位工具,以及巨量监控数据的处理方案。
项目地址:https://github.com/baidu/nettools
欢迎 Star、试用、提 Issue 和 PR。
