I don't talk to an agent anymore, I talk to a loop or a routine.
——Boris Cherny

先讲一个真实的 case。
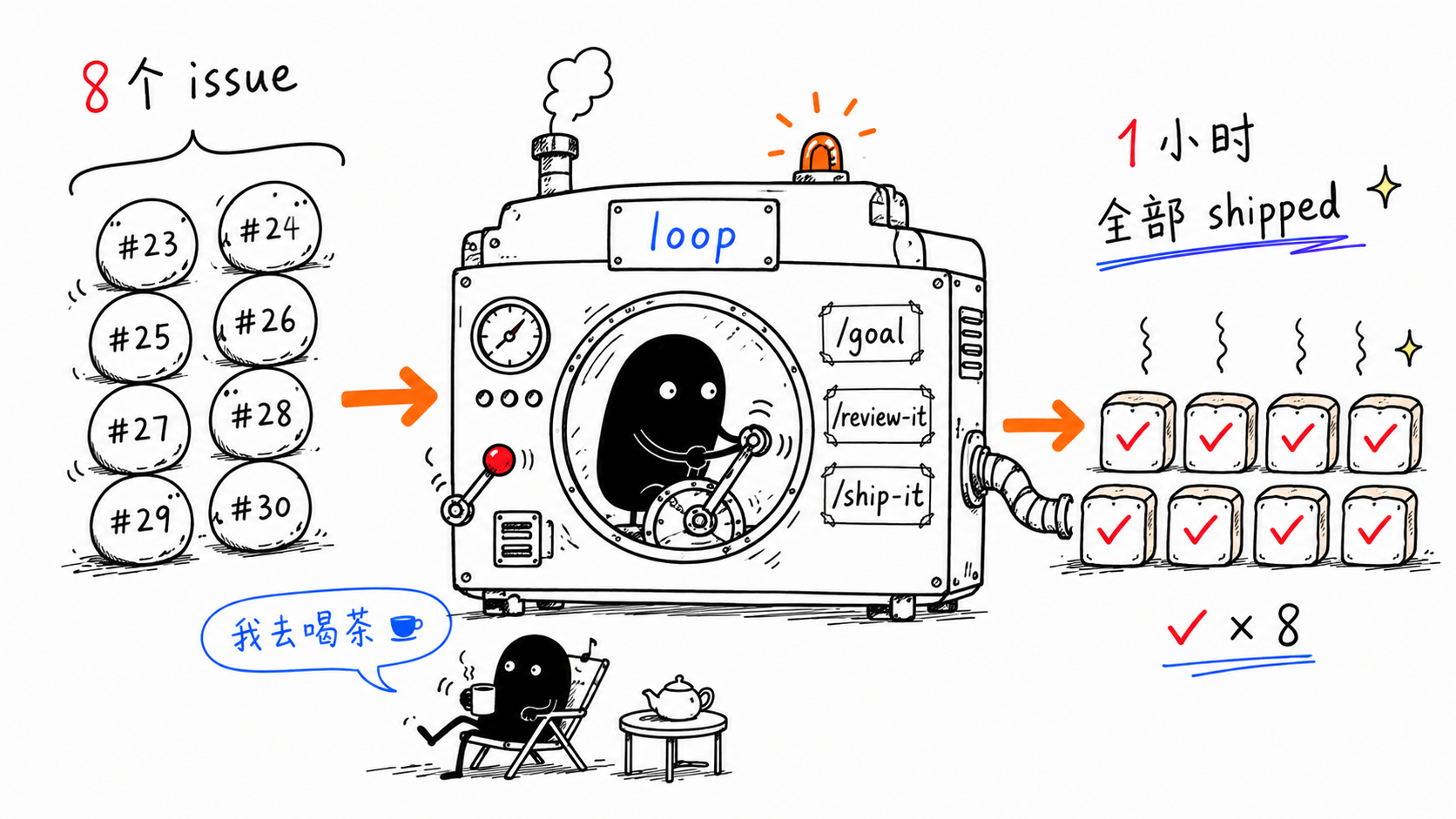
6 月 10 日下午,我把一个新工具 kuiniu(夔牛) 的 PRD 丢给 Claude Code,让它生成 8 个 issue 卡到 GitHub 仓库。然后我敲了一句 /loop-it,然后离开了。
一个小时后打开仓库一看,8 个 issue 全 closed,对应的 PR 全 merge 了。main 分支上多出了 client、server、codec、bitflip 检测、丢包统计、命令行入口、Makefile/goreleaser 集成,还顺手抽出了一个 util/rotate_writer.go。
我没有 prompt 任何一步。我只触发了一个循环。
02 Loop 到底是什么:从 ReAct 到编排
很多人吵这个词,是因为 "loop" 这个词其实裹着至少 5 种不同的东西。我在上一篇公众号文章里梳理过,这里再重复一遍背景。
Addy Osmani 把这个历史讲得很清楚:
| 阶段 | 时间 | 形态 | 谁在驱动 |
|---|---|---|---|
| ReAct 循环 | 2022 | 学术 while 循环,一个模型一个循环 | 人盯着 |
| AutoGPT | 2023 | 给目标让它自己 prompt | 著名地空转 |
| Ralph Loop | 2025 | bash 单行,每次重置上下文到锚定文件 | 终端开着 |
| /goal 产品化 | 2026 春 | 小模型验证停止条件 | 人启动一次 |
| 编排式 Loop | 2026 现在 | Loop 监督 Loop,调度+持久化 | 基础设施时间 |
最早的 Ralph Loop 是 Geoffrey Huntley 在 2025 年 7 月发布的,朴素得过分:一个 bash one-liner 把同一个 prompt 反复管道给 agent。但它只花 297 美元就构建出了一个完整的编程语言。Ralph 真正的创新是纪律,每次迭代都把上下文重置回固定的锚定文件,而不是让对话无限增长。
到了 2026 年,Codex 和 Claude Code 都内置了 /goal 命令,这就是产品化的 Ralph 循环。跑到一个可验证的停止条件成立为止,由一个独立的小模型来判断"做完了没"。写代码的 agent 不批改自己的作业,这是 loop 第一次有了 split verifier。
Boris 和 Steinberger 真正在说的是再上一层的"编排式 Loop"。和 Ralph 比,它把 loop 当成工作的单位而不是某个任务,让 loop 之间互相监督、并发地跑,靠调度而不是人工启动来发起,最关键的一点是把状态显式存到 git 里,崩溃可以恢复。
一句话总结:Ralph 假设你的终端开着;2026 版本的 Loop 假设你的终端关着。
03 我自己的 loop-it:把这套东西塞进一个 Skill
理论看完,问题来了:我怎么在自己的项目里跑一个 loop?
我做了一套叫 goal-workflow 的开源工作流,托在 GitHub:smallnest/goal-workflow。一行命令装:
1 | npx skills add smallnest/goal-workflow |
整个 pipeline 是这样的:
1 | /prd → /prd-to-spec (可选) → /to-issues → /loop-it (→ /goal → /review-it → /note-it → /ship-it)×N |
前三步还得我亲自上:/prd 和我聊一遍,把脑子里的需求整成 PRD;/prd-to-spec 可选,把 PRD 变成技术设计;/to-issues 把 PRD/SPEC 拆成一堆带 acceptance criteria 和 dependencies 的 issue 卡,自动 push 到 GitHub。
然后 /loop-it 接过去,进入 loop。每个 issue 走完整 4 步:
1 | /goal ← 实现 |
写这套东西时,我把 Addy Osmani 那张表和 Boris 的"五条建议"翻来覆去看了好几遍。最后落地的几个关键点都是冲着 loop engineering 那几个老坑去的。
第一件事是磁盘里的 state file。每个 loop 都需要一个仓库外的记忆。我用一个 .loop-state.json:
1 | { |
每次状态翻页就立刻写盘。崩溃了?重新跑 /loop-it,它读 state file,跳过已 shipped 的,从断点继续。这一招看起来傻得不行,但每个跑长链路 agent 的人都掉过同一个坑:没有磁盘记忆的 loop 一崩就归零。
第四件事是分级错误恢复。跑 loop 一定会撞墙,build 挂、测试红、merge conflict、rate limit、CI 红,没一个能躲。每种我都给了固定的恢复策略和最大重试次数:
| 错误类别 | 信号 | 恢复 | 上限 |
|---|---|---|---|
| build_failure | 编译错误、type 错误 | 读错误、改代码、再 build | 3 |
| test_failure | 断言失败 | 读输出、改实现、再测 | 3 |
| lint_failure | lint 红 | lint --fix、再 lint |
2 |
| merge_conflict | CONFLICT 标记 | rebase main、解、push | 2 |
| ci_failure | gh pr checks 失败 |
读 CI 日志、本地修、push | 2 |
| rate_limit | secondary abuse | 等 60s | 3 |
| unknown | 其他 | 标记 failed、跳过 | 0 |
撞死了不会无限重试,标记 failed、保留分支不删(让我事后看)、写检查点、跑下一个。
最后一件事是每一步都打 checkpoint:pending → in_progress → goal_done → review_done → note_done → shipped。每次状态翻页都写盘。中间断电下次接得上。这点是 ralph loop 没有的,ralph 假设你终端开着,loop-it 假设你笔记本盖着。
我实现的这个loop-it 相比较Boris说的工作流,还属于一个比较简单的,Boris说的Loop中的逻辑完全由Agent决定,而我实现的loop-it基本上是一个比较明确的工作流,按照github issues顺序去执行,虽然issues之间可能有依赖,但是在loop之前,to-issues已经把它们编排好了。而且loop-it是一个agent驱动去执行的,Boris的工作流可能是几百个Agent去执行,更宏大。
轻量级有轻量级的好处,使用起来更轻巧,也可以及时的让人类进行切入,token花费也少,下面是我昨天使用这种方式的一个实战,这也是我在Loop Engineering方向的一个探索,没有固定答案,只有摸索和经验的总结。
04 实战:一小时批量实现 kuiniu 的 8 个 feature
正如 Matthew Berman 说的,"nobody knows but him and boris."Loop Engineering 现在还没一个清晰的公认定义,但已经有不少人在解读和实践。我自己在 goal-workflow 里实现的 loop-it 算是其中一种轻量解读,加了点 harness engineering 的约束,走顺序迭代而不是 Claude Code workflow 那种宏大的多 agent 编排,省钱省心。
OK 现在回到开头那个 case。
百度内部多年沉淀的高性能网络监控工具集 nettools 这个月在密集开源,bitflip、baize、lidar 都已经放出来了。下一个准备开源的是 kuiniu(夔牛),专门做 GPU 网络的丢包和时延探测,每个 GPU 8 张卡 8 个 IP,通过 GPU 收发包来探测。
这是一个有清晰约束的工程问题,正好适合 loop。
Step 1:写一份 PRD(人肉 30 分钟)
跑 /prd kuiniu,和 Claude 聊清楚几件事:
- 同号卡探测(卡 i 探卡 i)
- 发包 GPU、收包 CPU 的不对称路径
- payload 必须携带源目 IP/Port
- 重点是丢包率和时延
- 复用 baize 已有的 codec/bitflip 检测能力
输出一份 tasks/prd-kuiniu.md。
Step 2:拆 issue(人肉 5 分钟过审)
跑 /to-issues,自动拆出 8 个:
1 | #23 kuiniu: 创建配置格式与 GPU 拓扑校验 |
每个卡片都自带 acceptance criteria、dependencies、type、priority。push 到 baidu/nettools。
Step 3:/loop-it(人肉 3 秒)
1 | /loop-it |
剩下的全是 loop 的事。我去喝杯枸杞茶。
一小时后检查进度
1 | ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ |
8 个 issue 全 closed,PR 全 merge 进 main。中间循环跑 /goal → /review-it → /note-it → /ship-it 共 32 次小循环,加上 review 阶段的修复迭代,实际触发的 agent turn 接近 60 次。/review-it 在 #25 和 #27 上分别挑出了一些边界 case 没处理,loop 自己改完又跑了一遍 review 才进 ship。
整个过程我没有 prompt 任何一步。我只在第二天打开 GitHub 看了眼 PR 列表,扫了下 review 笔记,确认每个 PR 的设计决策合理之后,那些代码就已经在主干上了。
跑完这一晚我才信一件事:loop 的难点不是 loop 本身,是放进去那个能说"不"的东西。没有真正检查的 loop,只是 agent 在反复自我同意。
最后冷静一句:不是所有任务都值得 loop。CI 分诊、依赖升级、lint-fix、强测试覆盖的 issue-to-PR(比如这次的 kuiniu)适合先上手;架构重写、认证支付、生产部署暂时不要碰。
项目链接:
- goal-workflow: github.com/smallnest/goal-workflow
- kuiniu (夔牛) — loop-it 实战产物: baidu/nettools
- Addy Osmani 原文: Loop Engineering
- Matt Van Horn 长读: WTF Is a Loop? Steinberger vs. Cherny
