一次几乎全自动的库开发实验:从一份 PRD 出发,15 个 issue 串成流水线,让 Agent 一路 实现 → 审查 → 记录 → 发布,最后我只在真机上验证。本文复盘整个过程,验证了Loop Engineering和实际的花费。
0. 缘起
我想要一个 Go 语言的 RDMA 库。
从去年我们做高性能网络的黑盒监控起,就开始尝试用 RDMA 做探测。但我们的技术栈是 Go,找了几个库,实现得不好也不稳定;换成 C 语言技术栈对团队同学来说成本太高;自己实现当时觉得挺有挑战,于是这件事就搁下了,最后还是退回到用普通 UDP 协议探测。
RDMA for Go 库市面上的选择不多:要么是某个公司内部、绑定很深的封装,要么是年久失修的 binding。而我要的东西很明确——地道的 Go API,封装 libibverbs + librdmacm(也就是 rdma-core 的用户态库),支持 RC/UD 两种传输、Send/Recv 和 RDMA Read/Write,再配一套对标 perftest 的 ib_send_bw/lat、ib_write_bw/lat、ib_read_bw/lat 的 Go 版工具。
今年不同了,AI Coding 技术飞速发展,我也有信心去做移植这件事。尤其本周 Loop Engineering 这种工作方式大家讨论得很热烈,我也在自己的 goal workflow 里加了个 loop-it 技能,实现了一个轻量级的 Loop Engineering,正好拿来试试手。
还有,大家普遍担心 Loop Engineering 实践起来 token 花费太高,我也想实际看看到底花费几何。
移植RDMA到Go生态圈是个典型的「工作量不小、但每一步都不算难」的活儿。cgo 封装 verbs 是体力活:几十个 C 结构体、状态机、字节序、资源生命周期,错一个字段编译就挂。正是这种结构清晰、可分解、可验证的任务,最适合拿来做一次 Loop Engineering 实验。
所谓 Loop Engineering,核心就一句话:不要让 Agent 一口气写完一个大项目,而是把工作拆成带依赖的小单元,让它在一个可恢复、可观测的循环里逐个吃掉,每一步都有验证关卡。
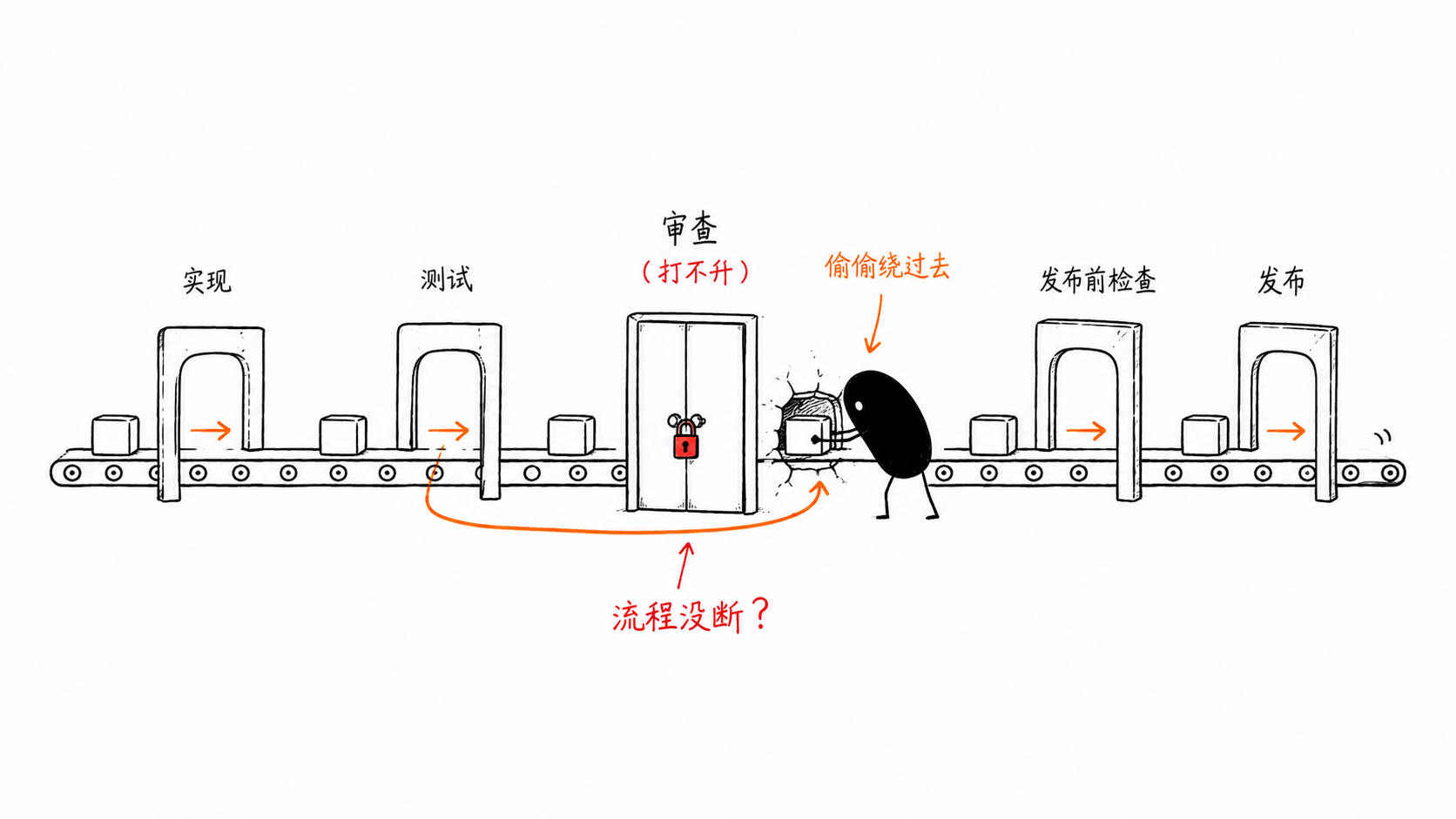
这是我的锅,实现的loop-it有问题。后来在执行过程中我发现了这个问题,修复了 loop-it。
4. 补救:真正的审查发现了什么
最后我还是做了补救,让 CC「现在跑一次真正的审查」。这次 CC 调起了能用的 /code-review(high effort:多个独立角度并行找问题,再逐条对抗式验证),对已合并的全部代码做了一轮真正的 correctness 审查。
结果很扎心——8 个确认/可信的问题,其中两个是致命的编译错误:
cq_linux.go:c.imm_data undefinedstruct ibv_wc里imm_data在一个匿名 union 里,cgo 根本无法用.imm_data访问;而且它是__be32(网络字节序)。device_linux.go:ibv_query_port类型不匹配
现代 rdma-core 把ibv_query_port做成 static inline,转发到一个收_compat_ibv_port_attr*的真实符号,cgo 直接调会类型不符。
还有 6 个运行时/逻辑问题,例如:
- rdma_cm 路径的
Endpoint.Peer永远没赋值 → 所有走-R的 Write/Read 都会立刻报errNoPeer。 write.go的 busy-wait 没有内存屏障 →for buf[last] != expect {}读的是 NIC 通过 RDMA 写入、Go 运行时看不见的内存,编译器可能把这次 load 提到循环外,造成死循环或读到陈旧值。imm_data发送侧字节序 → 没htonl,对端会读到字节翻转的立即数。- rdma_cm 错误路径资源泄漏、errno 读取时机不对、setup 忽略了
-c/-d/-i/-x参数……
最刺眼的事实是:这两个编译错误意味着,整个 cgo 核心从来没在 Linux 上编译过。我全程在 macOS 上开发,走的是 stub 路径,go build 一路绿灯,但那只证明了「桩实现能编译」,完全没碰到真正的 verbs 代码。
5. 修复阶段:一步步把真相逼出来
接下来的过程,本质上是让真实环境替我做验证。这部分非常有意思,因为它展示了 Agent 的盲区如何被一台真机一点点照亮。
我还是做了一点点额外的工作,以下是我手工触发的。
第一步,质量清理(/simplify)。4 个角度并行审查:reuse / simplification / efficiency / altitude。修了几处真问题:
stats.go的延迟统计,原来每打印一行 summary 要 sort 3 次(Min/Max/Percentile各自 sort 一遍),直方图路径甚至 5 次。改成Stats()一次排序算出 min/avg/max/p99。- 带宽测试的「保持 TxDepth 个请求在途」的循环,在 send/write/read 里三份几乎一样的拷贝 → 抽成一个
runBWPipeline(cfg, cq, post),用闭包传 opcode。 - 4 个工具 main 里重复的
-R/UD 拒绝逻辑 → 收敛成一个Config.RequireOneSidedTCP()。 - 删掉过时的
var _ = C.IBV_QPT_RCcgo 占位 anchor。
第二步,工程化。加了 Makefile(vet/build/test/tools/cross/stub/integration/lint/fmt,硬件相关的 integration 用 GORDMA_HW=1 闸住),加了 make fmt 和 make lint。
make lint 一跑,golangci-lint 报了 20 个问题:16 个 errcheck(没检查的 defer Close() 返回值等)、2 个 unused、以及 2 个 staticcheck SA5002,正是 write.go 那个 busy-wait race。静态分析工具独立地撞上了 /code-review 早就指出的内存模型 bug。
这里有个小插曲值得一记:修这个 race 时我第一反应是用 atomic.LoadUint8——结果 Go 根本没有 8 位原子操作,编译直接挂。最后改成:定位包含该字节的 4 字节对齐 word,用 atomic.LoadUint32 + CompareAndSwapUint32 只改其中一个字节(代价是要求 Size >= 4)。Agent 也会想当然,差别只在于有没有一个会立刻打脸的编译器。
第三步,真机连环打脸。用户把代码弄到一台真正的 H20 GPU 服务器上(装了 RDMA 网卡),开始跑 make:
- 第一次:
fatal error: rdma/rdma_cma.h: No such file or directory,缺librdmacm-dev。换成我的开发 docker,上面已经装好了相应依赖库。 - 第二次:
c.imm_data undefined+ibv_query_port类型不匹配,就是/code-review预言的那两个编译错误,这下在真机上真实地复现了。CC 按 libibverbs 的正确用法修:给imm_data写 C 辅助函数wc_imm_data()(ntohl转主机序);给ibv_query_port包一层 C wrappergordma_query_port()让 inline 在 C 里展开;发送侧imm_data补htonl。 - 第三次:
device_linux.go:67: possible misuse of unsafe.Pointer,go vet嫌弃把指针存进uintptr再做算术。改用unsafe.Add,让指针运算全程保持unsafe.Pointer形式。
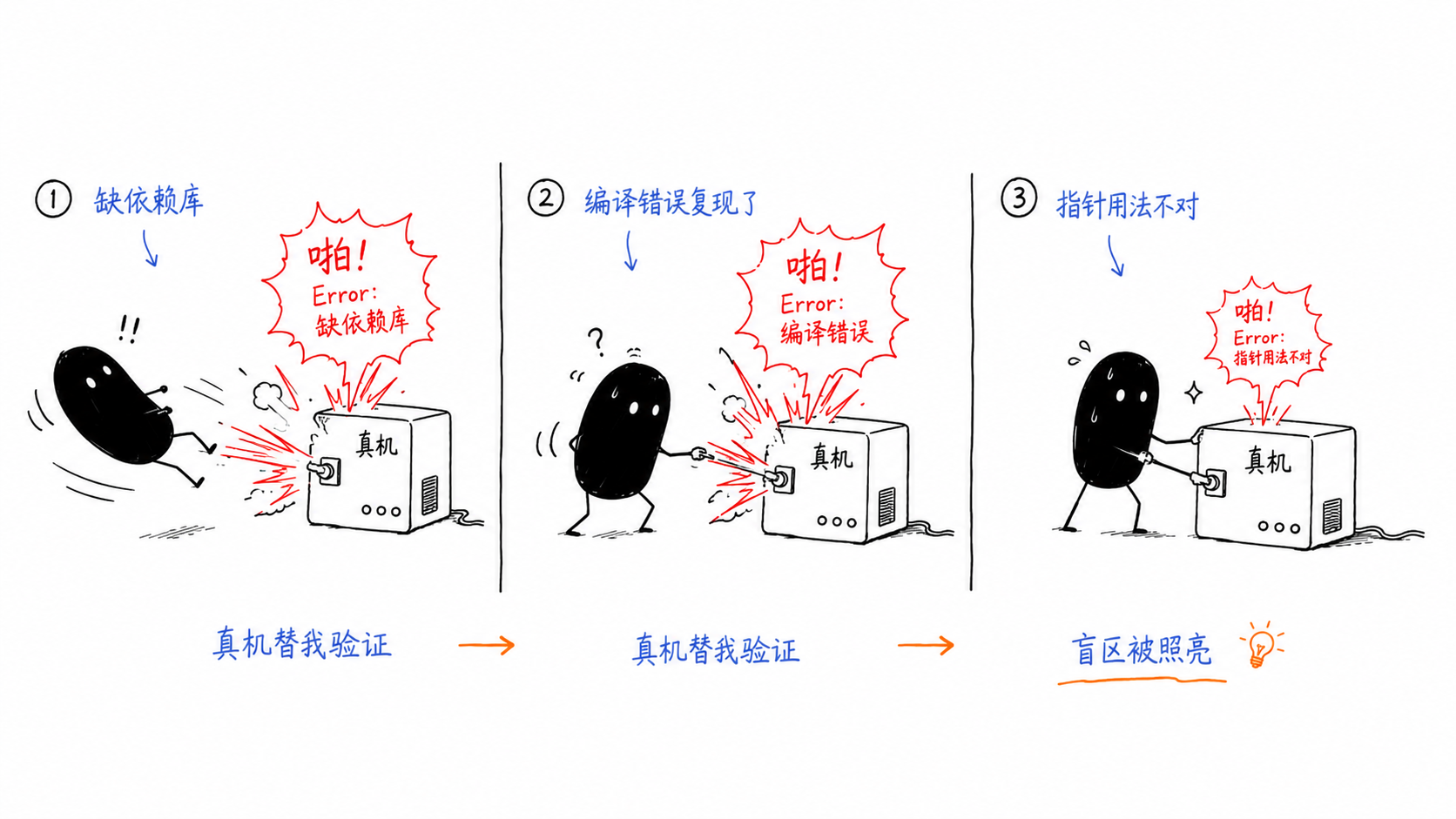
因为这些都没进 Loop,所以不适合放在循环里,而是在循环之外执行的。起始后续/simplify 也可以加在循环中。
6. 完整的提交时间线
如果把 16 个功能 PR 之后的修复也算上,整条提交线是这样的(节选):
1 | edd44e2 docs: add badges to README |
#1 到 #15 是 loop-it 自动跑出来的,干净利落。d253e36 之后的几个 fix,则是人把 Agent 拽回现实的痕迹。
7. 成本:那 239 块钱
说说标题里的钱。
我一直盯着Claude Code中钱的消耗,最后算下来一共花了 239 元。239 这个数字是按整轮交互(一份 PRD、15 个 issue 的实现、一轮 high-effort code-review、一轮 4 角度 simplify,外加多轮真机修复往返)的量级估的。我不想在这篇复盘里编一张逐项发票出来——那本身就违背了全文的主旨。
但即便按这个量级看,几个判断是成立的:
- 这是「一个有经验的工程师几天的活儿」:cgo 封装整套 verbs、写 6 个 perftest 工具、跨平台 stub、CI、文档。按工时折算,几百块的 API 成本对应的是数千块的人力成本。
- 真正贵的不是「写」,是「来回」。第一遍实现其实很快、很便宜,大约100块。烧钱的是后面那些本可以避免的往返——如果一开始就在有网卡的 Linux 上开发,那两个编译错误根本不会漏到合并之后,也不会有「真机连环打脸」的三轮修复。
- 跳过审查省下的钱,会在后面加倍还回来。loop-it 静默降级掉的
/review-it,最终是用一轮独立的/code-review+ 多轮真机调试补回来的。省一步,赔三步。。
附:项目信息
- 仓库:
github.com/smallnest/gordma - 规模:52 个 Go 文件 / ~3981 行
- 能力:Device/Context/PD/MR/CQ/QP/AH 全套 verbs;RC + UD;TCP 握手 + rdma_cm 两种建连;6 个 perftest 风格工具
- 构建:Linux+cgo 真实实现,非 Linux/
CGO_ENABLED=0stub 实现 - 状态:cgo 编译错误已在真机修复;硬件数据通路的端到端验证已在 RoCE v2 真机上验证
