用 Go 写 RDMA,到底能有多简单?又能有多快?这篇带你从零跑到 400 Gb/s。
开篇:一个让人又爱又怕的技术
如果你做过高性能网络,一定听过 RDMA 这个词。它是 AI 训练集群里 GPU 之间狂飙数据的底层、是分布式存储压榨延迟的杀手锏、是金融交易系统微秒必争的武器。
两种传输 & 两种操作
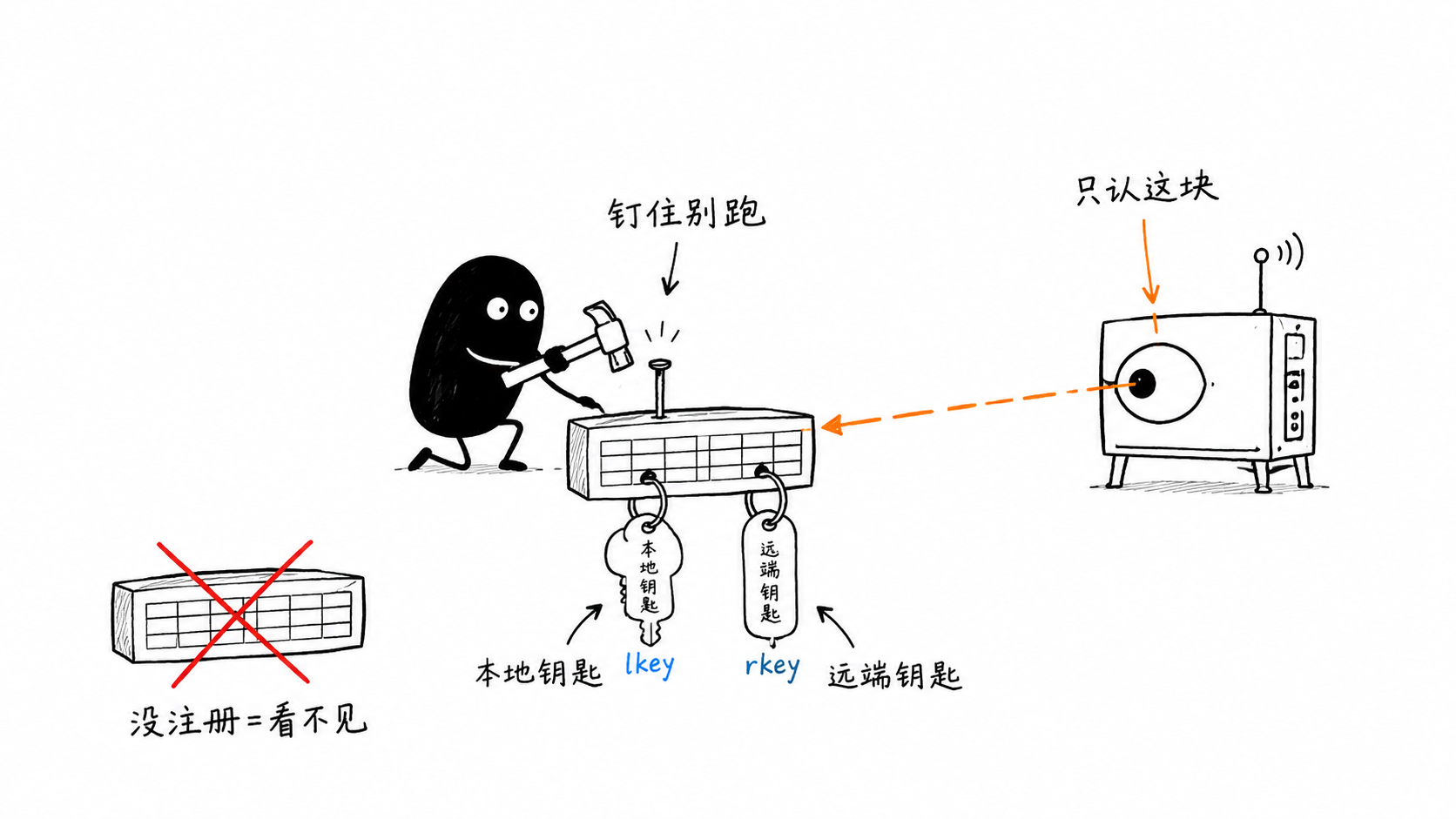
RC(可靠连接,类比 TCP):有序可靠,支持双边和单边操作
UD(不可靠数据报,类比 UDP):无连接,一对多
双边操作(Send/Recv):接收方要先挂好接收请求,双方 CPU 都参与
单边操作(RDMA Write/Read):发起方直接读写对端内存,对端 CPU 完全不参与——这是 RDMA 最"魔法"的地方
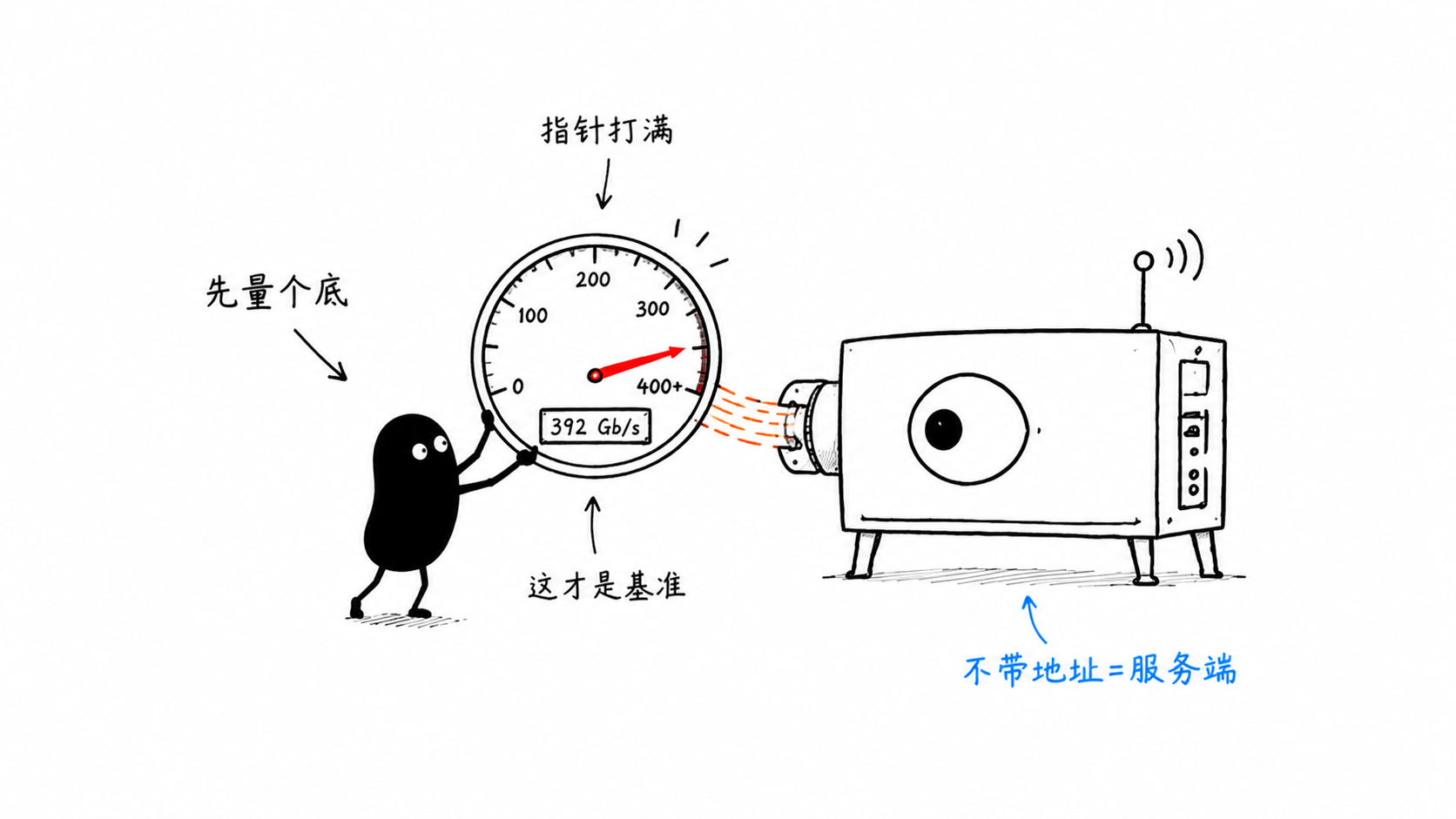
二 · 先用 perftest 摸清家底
在写代码之前,先得知道你的网卡能跑多快。业界标准是 perftest(linux-rdma 出品的 C 版基准工具)。gordma 贴心地用 Go 复刻了一套对标工具,放在 cmd/ 下:
| 工具 | 对标 | 测什么 |
|---|---|---|
go_send_bw / lat |
ib_send_bw/lat |
双边 Send 的带宽 / 延迟 |
go_write_bw / lat |
ib_write_bw/lat |
单边 Write |
go_read_bw / lat |
ib_read_bw/lat |
单边 Read |
go_rdmanet_bw / lat |
—(高级) | 测 gordma 高级 API |
命名规律很简单:操作(send/write/read) + 指标(bw 带宽 / lat 延迟)。每个工具不带地址就是服务端,带对端地址就是客户端。
跑一把带宽测试:
1 | go build -o bin/ ./cmd/... |
输出:
1 | #bytes #iterations BW average[MB/s] MsgRate[Mpps] |
48996 MB/s ≈ 392 Gb/s(注意单位:go_send_bw 输出的是 MB/s=10⁶ 字节/秒,×8÷1000 才是 Gb/s),这就是这张 400G 网卡的实力基准。记住这个数,后面要拿它当标尺。
⚠️ 单位是个大坑:三个常用工具输出单位各不相同,直接比原始数会差出 8 倍——C 版
ib_send_bw是 MiB/s(2²⁰ 字节)、Go 版go_send_bw是 MB/s(10⁶ 字节)、gordma 的--raw是 MiB/s(已对齐 C 版)。本文所有数字都统一换算到 Gb/s(10⁹ bit) 再比较。
💡 小贴士:命令里的 IP 是服务端
-d指定的那张 RoCE 网卡绑定的 IP,不是CPU网络/SSH 那个 IP。这是新手最容易连不上的坑。两端的-d(设备)和-x(GID 索引,RoCE v2 常用 3, 可以使用show_gids查看)要对齐同一张物理网络。
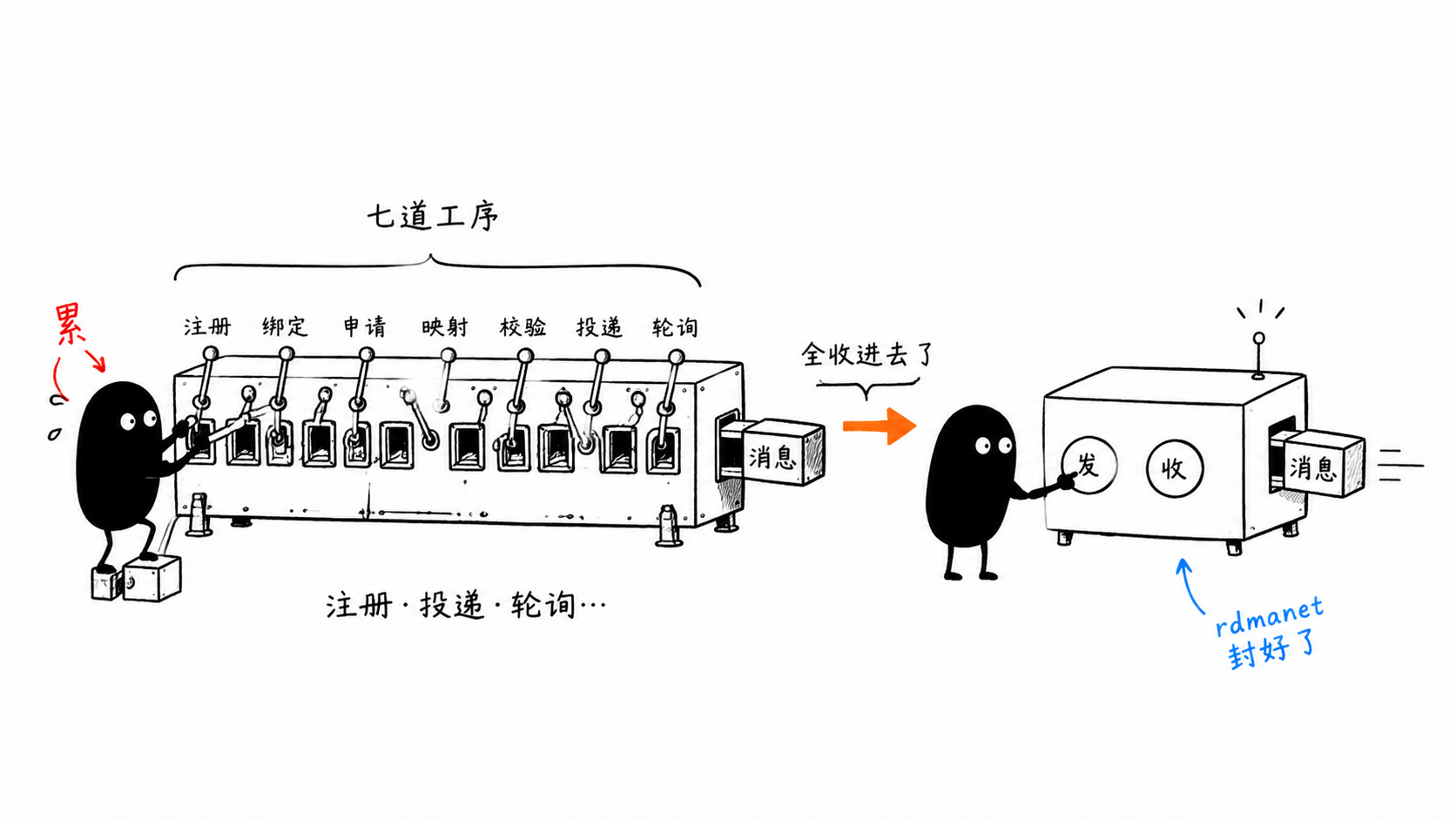
三 · 底层 API:完全掌控,但要写够样板
gordma 的底层包 gordma 一比一映射了 RDMA 的对象模型。想要完全掌控每个工作请求、每个 QP 参数,用它。代价是:你得自己走完那七步。
来看一个完整可跑的 RC 回显(用 rdma_cm 建连,省掉手写状态机):
服务端:收一条,回显
1 | func server(addr string) error { |
每一行都对应一个 RDMA 概念:注册内存 → 先挂 recv → 轮询 CQ → post send。底层 API 的好处是没有任何隐藏行为,你能做单边 Write/Read、能精调 QP 容量、能复刻 perftest——坏处是,样板真的多。
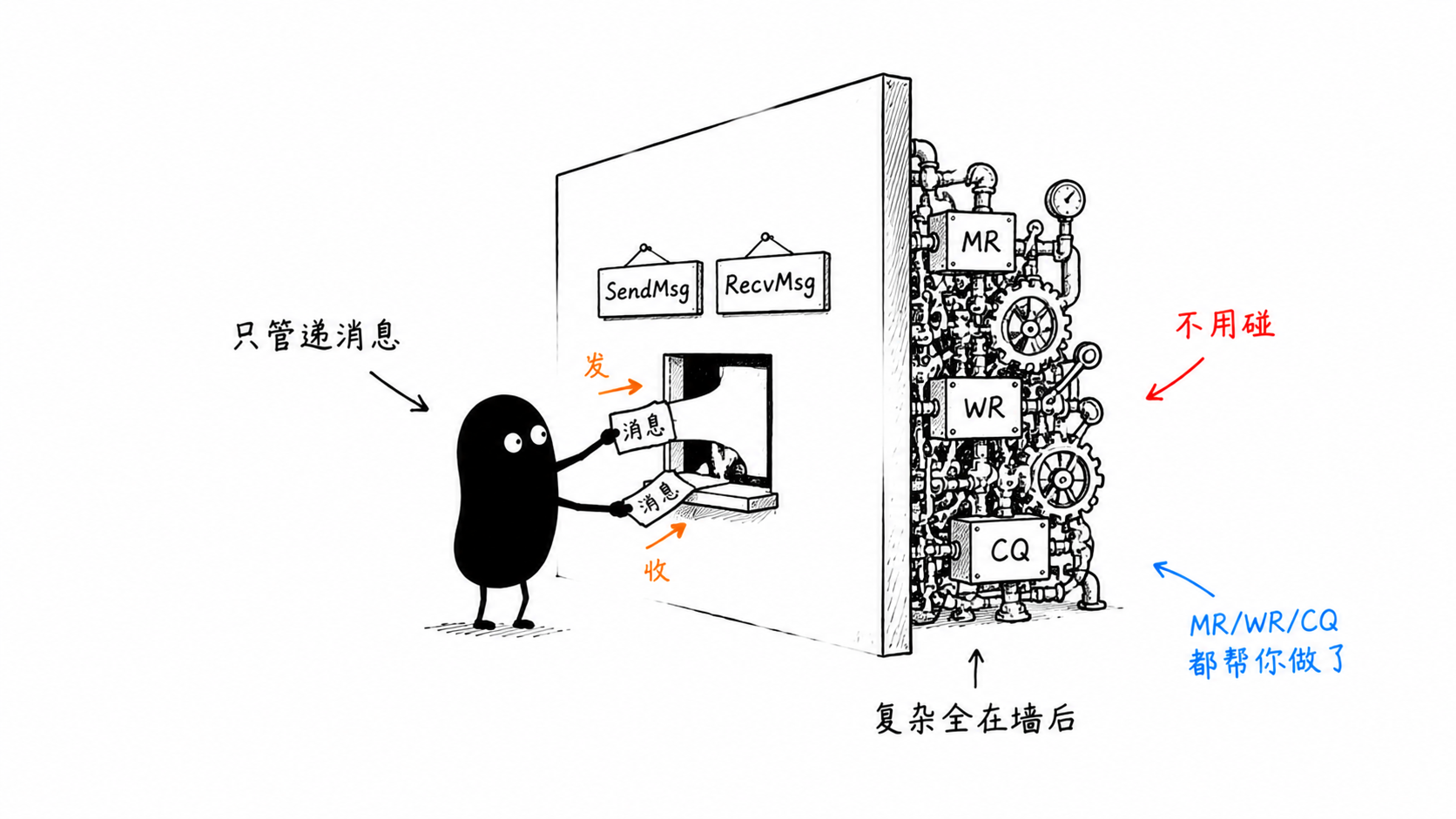
四 · 高级 API:像写 net 一样写 RDMA
如果你只是想写业务,不想碰 MR、WR、CQ 这些——用 rdmanet 子包。它把上面那一大坨全收进了 Dial / Listen / SendMsg / RecvMsg。
来看同样的事,高级怎么写。一个 RPC 服务:
服务端
1 | func serve(addr string, opts []rdmanet.Option) error { |
客户端
1 | conn, _ := rdmanet.Dial("33.0.226.25:18515", |
没有 MR、没有 WR、没有 CQ 轮询、没有状态机。 是不是和标准库 net 一模一样?
rdmanet 还提供了一整套实用能力:
- 消息语义
SendMsg/RecvMsg:保留边界,大消息自动分片重组 - 字节流适配器
Read/Write:Conn直接满足io.ReadWriteCloser,能配io.Copy传文件 - 批量 I/O
SendBatch/RecvBatch:摊薄每次调用开销 - UD 数据报
PacketConn:无连接、一对多 - 地址注册表
Registry:带外发现对端
仓库里还附带了 17 个按功能拆分的示例(examples/ 目录),从最小回显到全双工聊天、文件传输、一对多广播,一个功能一个目录,照着抄就行。
五 · RawConn:既要 net 风格,又要榨干网卡
高级 Conn 好用,但有个问题:它为了"保留消息边界 + 流控 + 易用"付出了固定成本——封帧、信用流控、bounce 缓冲拷贝、后台 poller goroutine 的跨线程交接。这些叠加起来,让它在 64KB 大包上只能跑到约 28 Gb/s,远没喂满 400G 网卡。
于是 gordma 给了第三个选择:RawConn。
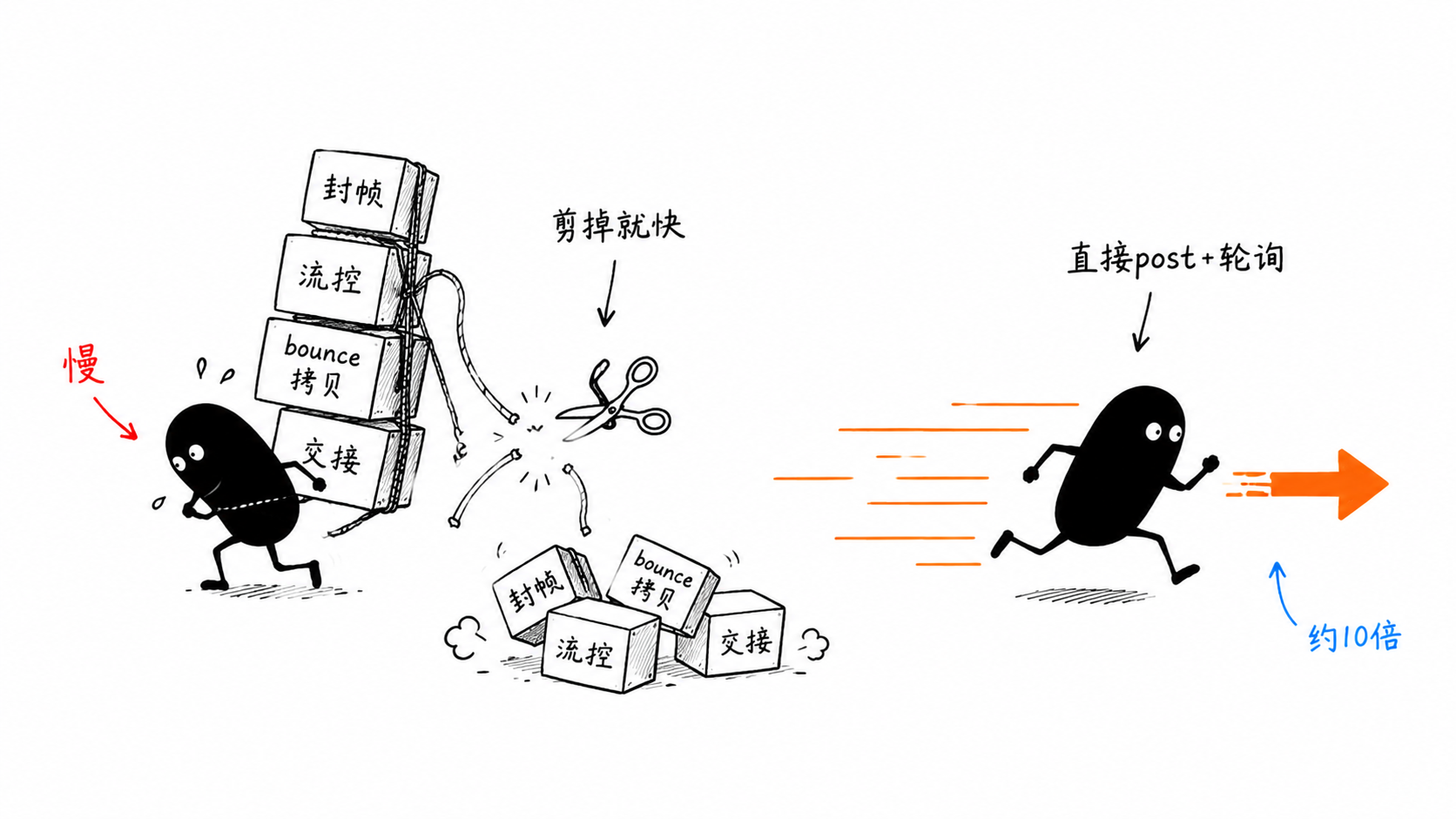
它的理念很直接:把所有花哨的东西全剥掉,直接暴露"注册内存 + 投递 WR + 自己轮询 CQ",在同一个 goroutine 里 post + busy-poll,无封帧、无流控、无交接。这正是 perftest 打满线速的那套循环。
最省事的用法是内置的 PipelineBatch,保持 N 个请求 in-flight(同时在网卡里跑),每完成一个补一个:
1 | rc, _ := rdmanet.DialRaw(addr, |
RawConn 还支持:
- 单边 Write/Read:走 TCP 握手交换了对端 rkey/地址,可以直接做"对端 CPU 不参与"的远程读写
- 批量提交
PostSendBatch:用 WR 链表一次ibv_post_send提交多个请求,把 cgo 跨界开销从"每个 WR 一次"降到"每批一次",小包消息率因此能提升约一个数量级 - 逃生舱
QP()/CQ()/PD():需要时随时下沉到底层自己驱动
代价当然有:RawConn 不替你保留消息边界、不做流控(得自己控制 in-flight 数,否则 RNR)、不托管缓冲区。一句话:先用 Conn,确实要榨干网卡时再上 RawConn。
🔬 顺带破一个误解:很多人(包括我一开始)以为"Go 经 cgo 调 RDMA 一定比 C 慢一截"。我用
GORDMA_PROBE=1把发送循环拆成"提交 WR(post)"和"忙等完成(poll)"两段实测,结论反直觉:一次ibv_post_send含 cgo 跨界约 300ns,只占总时间 ~15%,而且go_send_bw和RawConn两者完全相同。也就是说——cgo 提交开销真实存在但很小,不是性能差距的主因。后面第六节会看到,go_send_bw状态好时能直接追平 C 版ib_send_bw,根本没有"Go 追不上 C"的固有差距。
六 · 真刀真枪:带宽压测对比
理论讲完,上数据。同一对 400G RoCE v2 节点,64KB 大包,100 万条消息,实测:
结论很清楚:
- 从
Conn到RawConn,同一个库、同一张卡,吞吐 暴涨约 8 倍,证明那 28 Gb/s 的天花板就是高级那套便利机制的固定成本。 RawConn用纯 Go(加薄薄一层 cgo)把吞吐推到了 230+ Gb/s 的量级,已经和同一个库的底层go_send_bw在同一个数量级。
一个反直觉的发现:差距不在 cgo,而且不是固定的
我原本想搞清"RawConn(232) 为什么比 go_send_bw(392) 慢约 1.7 倍",于是做了一组同机、同口径、交替跑的实验(锁核 taskset + 性能调频,尽量压住抖动),用 GORDMA_PROBE=1 拆出 post/poll。结果挖出三件事:
① cgo 提交不是瓶颈。 两个工具的 post(提交 WR)都是 ~300 ns/WR、占比 ~15%,完全相同。所谓"每个 WR 一次 cgo 跨界拖慢了 Go",在这个负载上站不住——提交很便宜,而且两边一样便宜。
② Go 能追平 C。 锁核后 go_send_bw 实测峰值 0.748 Mpps,和 C 版 ib_send_bw 完全一致。早先看到的"go_send_bw 只有 ~314 Gb/s"是机器状态差时的数,不是 cgo 的锅。
③ 差距是"可变"的,不是固定缺陷。 交替跑 3 轮,go_send_bw 在 0.414 / 0.748 / 0.414 Mpps 之间离散双峰跳变,而 RawConn 稳定在 0.42。也就是说:1.76× 之间晃**,取决于那一轮 go_send_bw 状态差的那几轮,和 RawConn 几乎持平;两者差距在 **1.05×go_send_bw 能不能抢到干净的网卡/CPU 窗口。
差距的真正位置在 poll(忙等完成到达):go_send_bw 的 poll 在 0.75~1.33 µs/WR 间大幅波动(状态好就打满线速),RawConn 则被稳定压在 ~1.40 µs。考虑到这是一台共享 GPU 机、400G 链路被其他租户竞争,最合理的解释是环境竞争,而非 RawConn 有独立的代码缺陷——两个工具走的是同一套 QP 建立和 CQ 轮询路径,逐行核对没有能让 RawConn 单独变慢的差异。
🧭 给读者的实用结论:① 不要迷信"Go+cgo 必慢于 C",在大包带宽场景两者能打平;② cgo 的固定开销真实但小,真正要省它得靠批量提交 + 忙轮询(见下文小包测试);③ 想认真比性能,务必锁核、独占机器、多次取中位数,共享机上的单次数字会骗你。
小包更能看出批量提交的威力
64KB 大包很容易撞带宽上限,看不出 CPU 侧的优化。换成 1KB 小包(消息率受限场景):
1 | ./bin/go_rdmanet_bw --raw -s 1024 -n 5000000 -d mlx5_1 -x 3 -b 128 33.0.226.25:18515 |
1 | raw-batch Send(txDepth=128): 5000000 x 1024 bytes in 0.85s: 47.92 Gb/s, 5.850 Mpps |
5.85 Mpps——批量提交(PostSendBatch)在小包上把消息率拉高了一个数量级。这正是榨干高频小消息场景的关键。
尾声:三个档位,按需取用
gordma 最打动我的,是它没有逼你在"易用"和"性能"之间二选一,而是给了一条平滑的升级路径:
| 你的需求 | 用哪个 | 心智负担 |
|---|---|---|
| 写业务,要 net 风格 | rdmanet.Conn |
像写 socket,几行搞定 |
| 既要简单又要极限吞吐 | rdmanet.RawConn |
自己管内存,几十行 |
| 完全掌控每个细节 | 底层 gordma 包 |
复刻 perftest 的程度 |
而且全部代码在任何平台都能编译(macOS/Windows 走 stub 桩实现,RDMA 调用优雅返回 ErrNotSupported),只有真正运行时才需要 Linux + RDMA 硬件。这意味着你可以在 MacBook 上写代码、跑单元测试,真要压测时再丢到带卡的机器上,开发体验和门槛都友好得多。
如果你正在被 RDMA 编程劝退,或者想给你的 Go 服务接上高性能网络,不妨试试 gordma:
🔗 github.com/smallnest/gordma
从 go run ./examples/echo-msg 跑通第一个 RDMA 程序开始,你会发现——原来 RDMA 也可以这么"傻瓜"。
本文所有性能数据均为同一对 400G RoCE v2 节点上的实测结果,会随硬件与配置不同而变化。完整教程、API 文档、17 个示例和 8 个压测工具均在仓库中。
