目录 [−]
"Each unit of engineering work should make subsequent units easier — not harder."
每一个工程工作单元都应该让后续单元更容易,而不是更难。——everyinc/compound-engineering-plugin README
第 14 章讲 improve 把计划当作产品,让强模型做判断、弱模型做执行。省了 token。但还有一个问题没回答:省下来的 token 和时间,有没有让你的下一次工作起点更高?
大部分 AI 编程工具解决的是"这一次"。帮你写代码,跑测试,合 PR。会话结束,上下文消失。下次开新会话,Agent 从零开始重新理解这个项目。构建命令是什么来着?那个奇怪的约定是因为什么历史事故?上次修那个 bug 踩了什么坑?全忘了。Agent 学到的东西,在你关掉终端的那一刻归零。
Compound Engineering 要反转的就是这件事。核心主张不是"让 Agent 这次做得更好",是"让 Agent 下次起点更高"。每一轮工作结束时,把学到的东西沉淀回知识库,变成下一轮 Agent 启动时自动读到的上下文。用复利的方式做工程。
这个想法来自 Every 公司(Every.to),由 @kieranklaassen 和 @tmchow 维护。他们把这套方法论打包成 compound-engineering-plugin,MIT 开源,GitHub 18.3K+ star,随插件提供 37 个 skills 和 51 个 agents。支持的编码工具覆盖 Claude Code、Cursor、Codex、GitHub Copilot、Factory Droid、Qwen Code、OpenCode、Pi、Gemini、Kiro,几乎你能叫出名字的都在。

15.1 什么是复利工程
"复利工程"不是比喻。Every 团队是认真的。
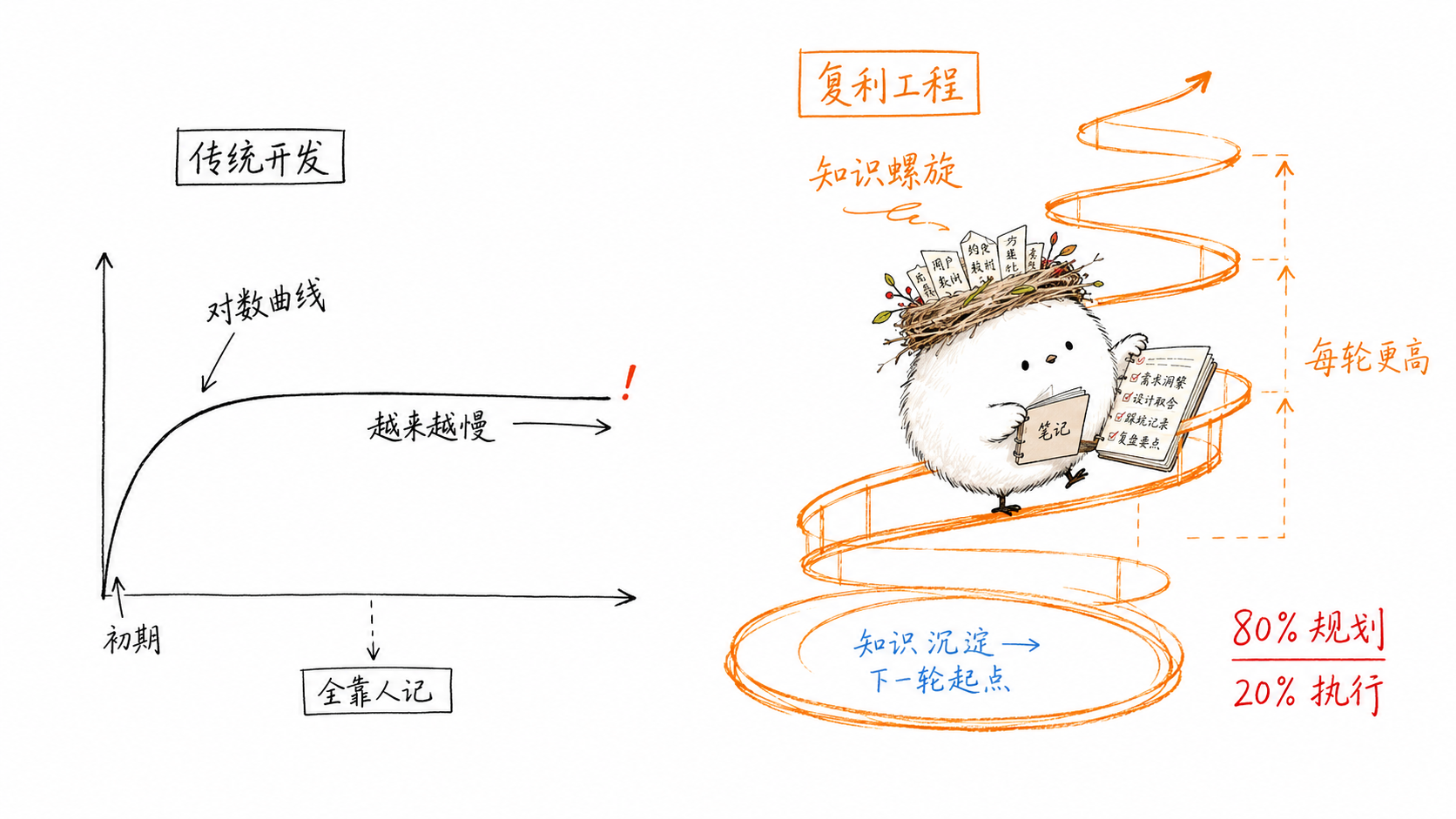
传统开发的加速曲线是对数曲线。项目初期进展快,随着代码量增长,复杂度累积,每次改动越来越慢。调试要翻更多文件,重构要查更多依赖,新人要读更多代码才能上手。熵在增加,摩擦力在增加。对抗它的方式,几乎全靠个人记忆和 Code Review 里零散的口头约定。
复利工程把这条曲线反过来。它在每一轮工作结束时,要求把本轮学到的东西显式写下来、存进仓库。不是"我记住了",是"下一轮 Agent 启动时会自动读到"。下一轮的 Agent 不需要重新发现那个坑,不需要重新推导那个约定,不需要重新踩同一条弯路。每一轮都比上一轮聪明一点。
Every 团队的投入结构说明了一切:约 80% 在规划与评审,20% 在执行。这跟传统开发"花 10 分钟想、花一整天写"的习惯反着来。逻辑很简单:锐利的头脑风暴收紧计划范围,紧凑的计划缩小执行自由度,好的评审抓模式而非孤立的 bug。每一阶段的输出质量决定下一阶段的输入质量。在规划上省的时间,执行加倍还回来。在执行上省的时间,将来加倍还回来。
和第 14 章 improve 比一下。improve 把计划当交付物,强模型做判断、弱模型做执行。Compound Engineering 往前走了一步:不光让计划成为一等公民,还让每一轮工作的学习成果成为一等公民。improve 省了 token,复利工程让省下来的 token 产生复利。
15.2 核心问题:对抗复杂度的累积
先看清它在跟什么作斗争。
软件工程有一个现象,叫"知识散落"。项目跑了一年,团队的集体知识分布在十几个人的脑子里、几百条 Slack 消息里、上千条 Git commit message 里、几十个已经过时的 Wiki 页面里。AI Agent 面对这个项目,能看到的只有源码,最多加一个 README。那些藏在人脑子里的约定、那些被某次事故逼出来的奇怪做法、那些"这个函数不能动因为有个没文档化的副作用",Agent 完全不知道。
Agent 在这个信息黑洞里工作。它猜,它假设。写出来的代码技术上正确、上下文中错误,能跑,但破坏了某个没写在任何地方的约定。然后你花时间解释,它重做。下次开新会话,你又解释一遍。
传统开发已经够糟了,至少人记住了。AI Agent 的记忆在会话结束时就清零。128K 的上下文窗口,一次性的。"知识散落"在 AI 时代被放大了十倍。Agent 写得快,忘得也快。你获得的代码量,被丢失的知识量抵消了一部分。
复利工程的解法不是让 Agent 记住更多。是让 Agent 每次读同一个文件。STRATEGY.md、brainstorm 文档、plan 文件、compound 记录、pulse 报告,这些不是一回性的交付物,是跨会话存活的知识资产。下一次 Agent 启动时,这些文件自动进入它的上下文。它从"上一次结束的地方"开始,不是从零开始。
这和第 13 章 GSD Core 的 STATE.md / CONTEXT.md 同一个思路:Agent 会忘记,仓库不会。复利工程把这个思路从项目状态管理扩展到了知识管理。不光记录做到哪了,还记录学到了什么。
15.3 STRATEGY.md:上游的持久锚点
整个体系里,有一个文件坐在所有东西的上游:STRATEGY.md。
它不是规格,不是计划,不是 PRD。它是项目级的持久锚点,回答几个最基本的、但 AI Agent 自己永远猜不对的问题:
- 这个产品到底在解决谁的什么问题?不是功能列表,是用户痛苦。
- 用什么方法解决?不是技术栈,是产品策略和核心假设。
- 目标用户画像是什么?不是 demographic 标签,是行为模式和场景。
- 怎么度量成功?不是"用户更多",是具体的、可追踪的指标。
- 什么不算成功?团队决定不做什么,这和决定做什么同样重要。
通过 /ce-strategy 创建和维护。当 STRATEGY.md 存在时,下游所有命令——/ce-ideate、/ce-brainstorm、/ce-plan——在启动时自动读取它作为锚定上下文。一个新 Idea 是否靠谱、一个新需求是否偏离方向、一个新计划是否符合策略,Agent 自己就能做第一轮判断,因为它读到了"这个项目要什么"。
没有 STRATEGY.md 的 Agent,会在每次运行中优化向随机贡献者碰巧要求的东西。有一个定时阅读的 STRATEGY.md,Agent 知道什么值得做、什么该拒绝。这和 Peter Steinberger 在 Loop Engineering 中讲的 vision.md 是同一个东西:项目的宪法。第 12 章提过,Steinberger 的策略层就是一份 Agent 每次运行都读的项目宪法。复利工程把它固化为一个独立命令和独立文件。
15.4 主循环:带着更好的上下文重复
复利工程的主循环六步。每一步和前几章的方法论有相似的形状,但最后多了一步,那一步是整个体系的灵魂。
1 | /ce-strategy ──────────────────────────────────────────────┐ |
Ideate(可选):创意生成与批判。 /ce-ideate 在头脑风暴之前跑。它的工作是生成一批想法,用证据、先例和第一性原理逐一评估,筛出值得进入头脑风暴的。Every 团队在 2026 年 4 月给它加了一个"surprise me"模式:当团队觉得想法太保守时,Agent 可以故意跳出既有框架生成一批高风险高回报的方向。每条想法都有一个"担保合约",标明它来自直接证据、外部先例、还是第一性推理。这防止了"听起来不错但没人知道为什么"的想法混进下游。
Brainstorm:交互式问答,产出需求文档。 /ce-brainstorm 是循环的真正入口。它是一个双向对话:Agent 问澄清问题,对模糊表述较真,确认边界条件,然后产出一份结构化的需求文档,存在 docs/brainstorms/。文档大小可控,不是 PRD 的重量级文档,但足够让规划者精确理解要做什么。快速功能可能三五轮对话,复杂系统可能几十轮。
Plan:需求变实施计划。 /ce-plan 读取上一阶段的需求文档和 STRATEGY.md,产出详细的实现计划。和第 13 章 GSD 的 /gsd-plan-phase 类似,研究、分解、验证计划装得进一个上下文窗口。输出包括任务依赖图、预估工作量、文件变更范围。
Work:隔离执行。 /ce-work 在隔离的 git worktree 里执行计划,带任务追踪。和第 11 章 kanbots 的 worktree 隔离同一个原理,每个 Agent 在自己的 checkout 里工作,互不干扰。
Code Review:多 Agent 预合并审查。 /ce-code-review 派出一组专门的审查员 Agent,最多 20 个并行跑,从不同维度审查变更:正确性、安全、性能、可维护性、代码风格、测试覆盖。置信度评分,自动去重。和第 33 章 /review-it 同样的使命,区别在于复利工程默认派多个 Agent 而非一个。
Compound:沉淀学到的东西。 这是整个循环的灵魂。/ce-compound 把本轮工作中学到的、任何未来 Agent 应该知道的东西,写进仓库。发现的模式、踩过的坑、根因分析的结果、被证伪的假设、新增的约束。输出存在 docs/solutions/ 或相关目录,成为知识库的一部分。
下一次 /ce-brainstorm 启动时,Agent 读到的不只是 STRATEGY.md,还有上一轮沉淀下来的 compound 记录。它知道上一次类似的需求怎么做的,上一次类似的 bug 根因是什么,上一次类似的重构为什么选了那个方向。每一轮工作都让下一轮起点更高。
和第 5 章 gstack、第 8 章 Goal Workflow 相比,复利工程的主循环在前半段几乎一样。区别在末端:别人在 Review 之后交付,复利工程在 Review 之后先 Compound 再交付。这一步把知识复用从个人习惯变成了工作流里的强制环节。
举个具体的例子。假设你让 Agent 修一个 webhook 重复创建发票的 bug:
1 | /ce-debug "the checkout webhook sometimes creates duplicate invoices" |
Agent 复现问题,追到根因:webhook 在特定网络条件下会收到两次 delivery,而幂等键生成逻辑没有覆盖超时重试的场景。修完代码,跑完测试,过完审查。
传统的 Agent 在这里就停了。Commit,Push,开 PR,关会话。
复利工程要求多做一步:
1 | /ce-compound |
Agent 把这一轮学到的写下来:webhook 幂等键逻辑的当前假设和已知边界;超时重试和 webhook delivery 之间的竞态模式;哪些相关函数使用了类似假设,可能在不同条件下出现同样问题;一个 checklist,未来任何改 webhook 相关代码的人或 Agent 都应该检查。
下一次,另一个 Agent 处理另一个 webhook 相关任务时,启动时自动读到这些记录。它不会犯同一个错误。它甚至能在自己修改代码之前,自查"我有没有碰那些已知有竞态风险的函数"。
不是 Agent 变聪明了。是知识变持久了。
15.5 命令全景
复利工程的命令全部以 ce- 前缀,保持命名空间干净。按使用频率分四组:
核心循环(每次都走):
| 命令 | 做什么 | 位置 |
|---|---|---|
/ce-brainstorm |
交互式问答,产出需求文档 | 循环入口 |
/ce-plan |
需求变实施计划 | 规划 |
/ce-work |
worktree 隔离执行,带任务追踪 | 执行 |
/ce-code-review |
多 Agent 预合并审查 | 审查 |
/ce-compound |
沉淀学到的东西到知识库 | 复利 |
上游锚点(低频但关键):
| 命令 | 做什么 |
|---|---|
/ce-strategy |
创建或维护 STRATEGY.md |
/ce-ideate |
创意生成与批判(可选前置步骤) |
辅助工具:
| 命令 | 做什么 |
|---|---|
/ce-setup |
首次环境检查和项目 bootstrap |
/ce-debug |
系统化复现、追溯根因、修复 |
/ce-doc-review |
文档审查 |
/ce-product-pulse |
按时间窗生成使用/性能/错误报告,存入 docs/pulse-reports/ |
效率工具:
| 命令 | 做什么 |
|---|---|
/ce-commit |
分析变更并生成 commit |
/ce-commit-push-pr |
一键分支、提交、推送、PR |
/ce-worktree |
手动管理 worktree |
完整列表 37 个 skills 分布在核心工作流、研究与上下文、Git 工作流、审查与质量、开发框架、工具、实验七大类。51 个 agents 覆盖代码审查(20 个专业审查员)、文档审查(7 个维度)、研究(9 个深浅组合)、设计(3 个视角)、工作流编排(2 个调度器)。
15.6 跨平台与"刻意的固执己见"
复利工程支持 10 种以上的 AI 编码工具。Claude Code 最简单,插件市场直接装。其他工具通过 Bun/TypeScript 安装器适配:
1 | # Claude Code |
装完跑 /ce-setup,Agent 自动检查环境、初始化目录结构、生成基础配置。
Every 团队在 README 里有一句话值得注意:这个项目刻意固执己见(opinionated by design)。他们欢迎 issue 和 PR 讨论,但不会接受所有贡献。不是所有建议都是好建议,不是所有定制都应该变成配置选项。这个态度在开源社区不太常见,但放在方法论工具上很合理:一个没有主张的工具比没有用还糟,因为它让你觉得你在做事。
安装器自动适配不同平台的命令命名,有的用连字符,有的用冒号,开发者不需要手动处理。
15.7 与全书方法论的对接
复利工程把知识复用做成了工作流里的强制环节,这在前面的章节里只有萌芽。
和第 2 章 Skills。 /ce-compound 沉淀下来的模式、坑、约束、checklist,最终可以固化为可复用的 Skill。Matt Pocock 的小而可组合的 Skill 是复利的天然载体。复利工程给这个载体加了一个进水管:每次循环结束时,新知识自动流入。
和第 8 章 Goal Workflow 高度同构。 /ce-brainstorm → /ce-plan → /ce-work → /ce-code-review 这条链和 /prd → /prd-to-spec → /goal → /review-it 长得几乎一样。区别在末端:复利工程显式加了 /ce-compound;上游加了 /ce-strategy 作为持久锚点。Goal Workflow 适合单功能的一次性实现,复利工程适合持续运行的团队级工程。
和第 12 章 Loop Engineering。 Loop 用五个原语加状态记忆让 Agent 自主跑起来。复利工程在这个基础上加了一个机制:Loop 不只跑,还记录。每一次循环的产出不光是代码,还有"这一次学到了什么"。下一次循环启动时,Agent 读到的不只是进度状态,还有累积的知识。
和第 13/14 章同属"规划重于执行"。 三者都信规划比执行能产生更多杠杆。GSD 把重心放在上下文隔离和验证证据上,improve 把重心放在强模型审计和计划即产品上,复利工程把重心进一步前移到 80% 的规划与评审。但它的独特贡献不是更重的规划,是规划产出的知识能被下一轮复用。
和第 33 章 /review-it。 /ce-code-review 派 20 个专业审查员并行审查,是 /review-it 的多 Agent 版本。置信度门控、去重、模式识别,机制上比单 Agent 审查更完善。
15.8 本章小结
Compound Engineering 把复利从一个金融概念变成了一套工程纪律。它的核心不是让 Agent 这次做得更好,是让 Agent 下次起点更高。
三根支柱。第一,STRATEGY.md 作为上游锚点,给所有下游决策提供方向,Agent 不该优化向随机贡献者碰巧要求的东西。第二,80/20 的投入结构,把重心前移到能产生复利的环节:计划的质量决定执行的质量,执行的质量决定沉淀的质量,沉淀的质量决定下一轮计划的质量。第三,/ce-compound 作为强制环节,每次循环结束时把学到的东西显式写下来、存进仓库,让知识的生命周期超过一次会话。
传统开发对抗复杂度靠人的记忆和口口相传。AI 开发连这个都没有,Agent 的记忆在会话结束时归零。复利工程让知识活在文件系统里,不活在任何人的脑子里或任何 Agent 的上下文窗口里。37 个 skills、51 个 agents、10 种以上编码工具支持。这些数字背后是一个更简单的道理:你做的好工作,应该继续为你工作。
