大家好,给大家介绍一下, 新晋的高性能的 K/V数据库: badger。
这是 dgraph.io开发的一款基于 log structured merge (LSM) tree 的 key-value 本地数据库, 使用 Go 开发。
事实上,市面上已经有一些知名的基于LSM tree的k/v数据库, 比如 leveldb、goleveldb、rocksdb、boltdb, 可是为什么还要创造新的轮子呢。我们不妨从LSM说起。
LSM Tree
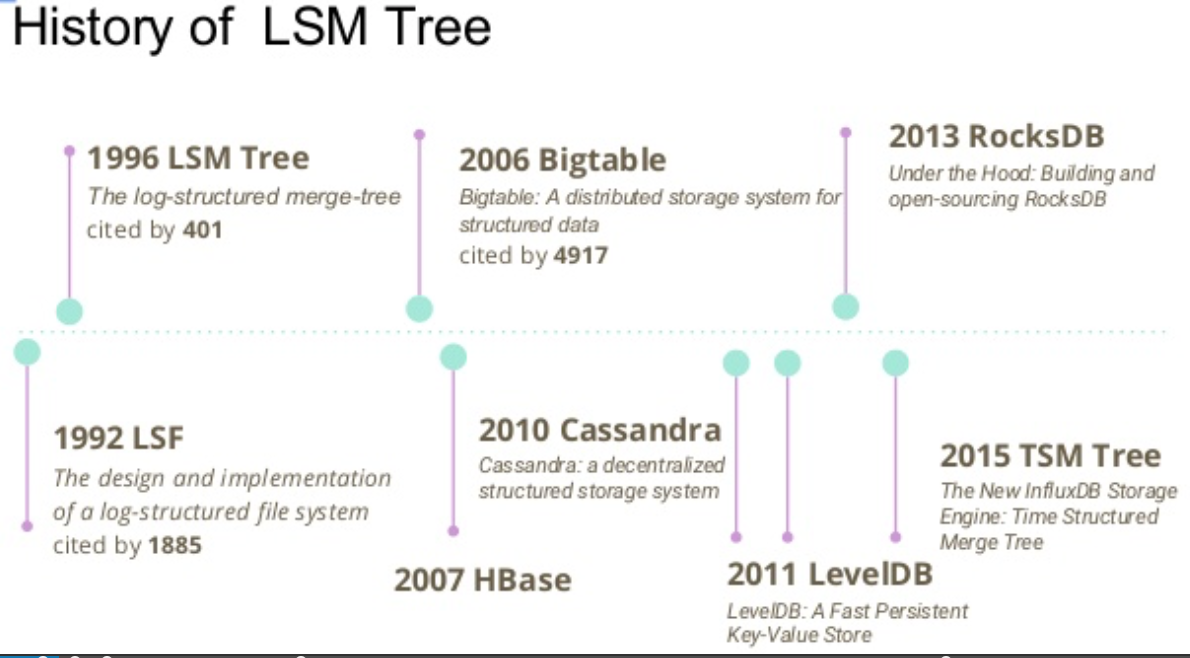
Log-structured merge-tree (简称 LSM tree) 可以追溯到1996年 Patrick O'Neil等人的论文。最简单的LSM tree是两层树状结构C0,C1。 C0比较小,驻留在内存,当C0超过一定的大小, 一些连续的片段会从C0移动到磁盘中的C1中,这是一次merge的过程。在实际的应用中, 一般会分为更多的层级(level), 而层级C0都会驻留在内存中。

2006年, Google发表了它的那篇著名的文章: Bigtable: A Distributed Storage System for Structured Data, 不但催生了 HBase这样的项目的诞生, 而且广泛地引起了大家对 LSM tree这种数据结构重视。
之后, 2007 HBase, 2010年 Cassandra, 2011年 LevelDB, 2013年 RocksDB, 2015年 InfluxDB的 LSM tree引擎等众多的 基于LSM tree的k/v数据库(引擎)诞生。
LevelDB 也是由Google的牛人 Jeffrey Dean 和 Sanjay Ghemawat创建的,被多个NoSql数据库用作底层的存储引擎。 RocksDB fork自LevelDB,但为多核和SSD做了很多的优化, 增加了一些有用的特性,比如Bloom filters、事务、TTL等,被Facebook、Yahoo!和Linkedin等公司使用。
badger
回到开始的问题, 既然已经有了一些优秀的开源的LSM tree的项目,为什么dgraph还要创建一个新的轮子呢?
答案是: 更好的性能。
dgraph开发一个新的基于LSM tree的数据库引擎badger是基于这篇论文: WiscKey: Separating Keys from Values
in SSD-conscious Storage, 这篇论文很新, 也就是去年(2016年)发表的,这篇论文提出了一种新的设计,专门为SSD所优化,将key和value分别存储以减少I/O放大。论文是由斯康辛大学麦迪逊分校的Lanyue Lu等人完成,Lanyue Lu毕业于中国科大,现在就职于Google。论文中提供了一个测试数据,加载数据库要比LevelDB快2.5–111倍,随机lookup要快1.6-14倍。
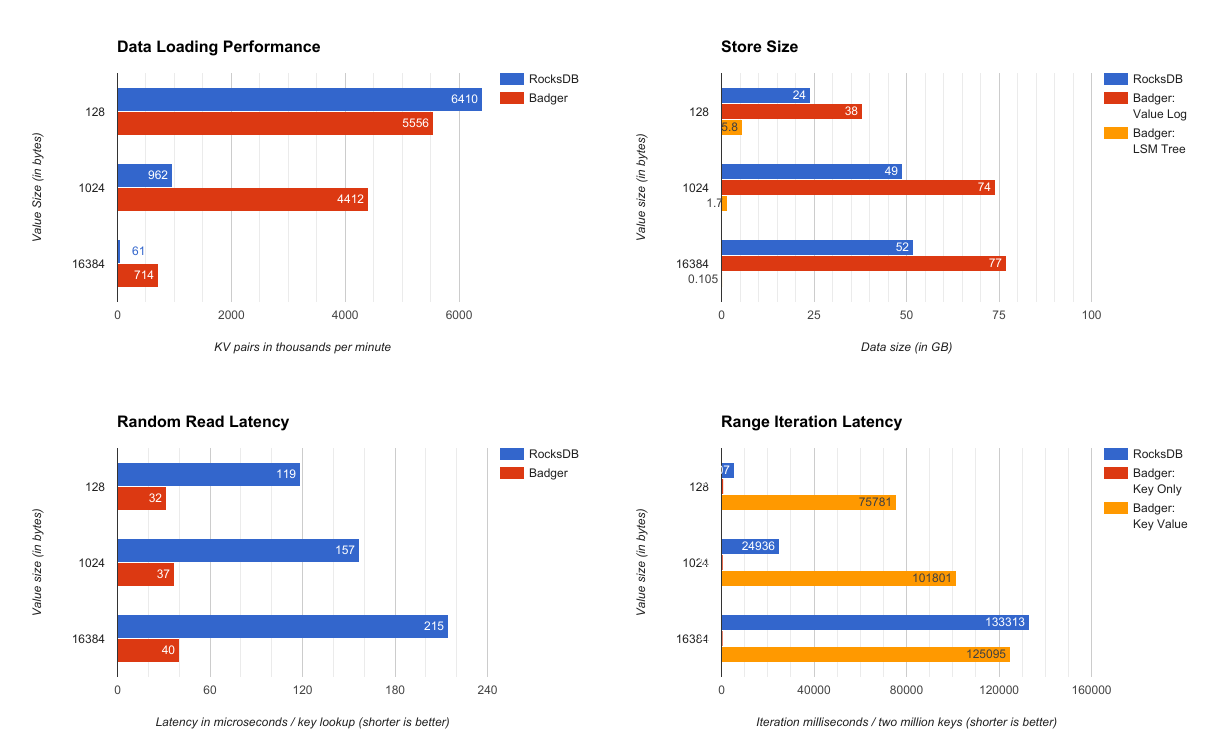
dgraph实现的这个产品叫做 Badger, 对于随机读,Badger至少要比RocksDB快3.5倍,对于值的大小从128B到16KB,数据加载Badger比LevelDB快0.86 - 14倍。
Badger分离的key和value,只有key存在LSM tree中, value存在WAL中,叫做value log。通常情况下,key比较小,所以LSM tree比较小,当获取value值的时候,再从SSD存储中读取。现在的SSD, 比如Samsung 960 Pro,对于4KB的数据块,可以提供44万的读操作/秒,这相当快了。
LSM tree最主要的性能消耗在于 compaction 过程。 在compaction的时候,多个文件需要读进内存,排序,然后再写回。每个文件都固定大小,如果文件中包含value, 文件大小会显著的增加,compaction会更频繁地发生。Badger不存储value,而是存储value的指针, 如果每个键是16, 每个value的指针是16 byte的话,一个64MB的文件就可以存储200万个键值对。
因为Badger不存储value,而是存储value的指针,compaction的时候只移动key和value指针,对于 1KB大小的value和16 byte的key, 写放大为(10*16 + 1024)/(16 + 1024) ~ 1.14。
因为Badger的LSM tree比较小,所以它的层级相对于普通的LSM tree要少,这也意味着查找会更少。例如1KB大小的value, 22byte的key, 7500万条数据的原始大小是 72GB,但是对于Badger的LSM tree来说,只需要1.7G,完全可以放在内存中,这也是Badger的随机读比RocksDB快3.5的原因。
容错
LSM tree将所有的更新写入到内存中的memtable,一旦填满, memtable回替换为immutable memtable,最终回写入到磁盘中的level0中。
如果机器宕机,内存表中的数据就会丢失。k/v数据库一般使用write-ahead log (WAL)来处理这个问题,Badger也一样。Badger会记录memtable的最后一个值的指针,当恢复的时候,它可以replay和重建LSM tree。
文件大小
Badger还使用技术对value值进行压缩,以便是log文件更小。
对于1KB的value,16 byte的key, 7500万条数据,RocksDB的 LSM tree 是 50GB, Badger的 value log文件是74GB(未压缩), LSM tree 是 1.7GB。
和RocksDB的Benchmark比较:
使用
Badger使用起来超级简单, 配置参数页不多,而且提供了默认的配置参数。
下面的代码是读写查和便利的代码,所有的操作都是在事务中完成的, Badger的事物是基于MVCC实现的。
1 | package main |
