
别再用 TODO 管 AI Agent:多智能体协作需要一块真正的看板
如果你真的开始把 AI Agent 用进日常工作流,很快会发现一个问题:任务本身不一定难,难的是任务之间的协作能不能可观察、可恢复、可交接。
传统 TODO 列表能记录“有什么事要做”,但很难回答两个更关键的问题:
- 这件事为什么卡住?
- 下游 Agent 接着做时,应该接收哪些上下文?
Hermes 的 Kanban 系统解决的正是这个问题。它不是把 Trello 或 Jira 简单搬进 Agent 世界,而是把看板变成一个多智能体任务中枢:任务会在 Triage、Todo、Ready、In progress、Blocked、Done 这些状态之间流转,父子依赖可以自动晋升,每次运行都有记录,完成任务时还可以留下结构化的 summary 和 metadata,供下游 Agent 继续使用。
换句话说,它关心的不只是“任务状态”,而是“Agent 工作流能不能接得上”。
为什么普通 TODO 不够用了
单人写代码时,TODO 往往够用。你写下三件事:
- 设计 schema
- 写 API
- 补测试
然后按顺序完成就行。中间即使有上下文损耗,也主要发生在你自己的脑子里:你知道为什么选了这个方案,知道实现踩了什么坑,知道测试哪条会挂。上下文是隐性的,但连续的。
但当你开始用多个 Agent 协作,事情就不一样了。
Story 1:单人功能开发
先看一个最简单的功能开发场景。
你要做一组 auth 功能:设计 schema、实现 endpoint、补测试。用普通 TODO 当然可以写三行,但它们之间的依赖关系是隐含的:schema 没完成,endpoint 不该开始;endpoint 没完成,测试也没法真正跑。
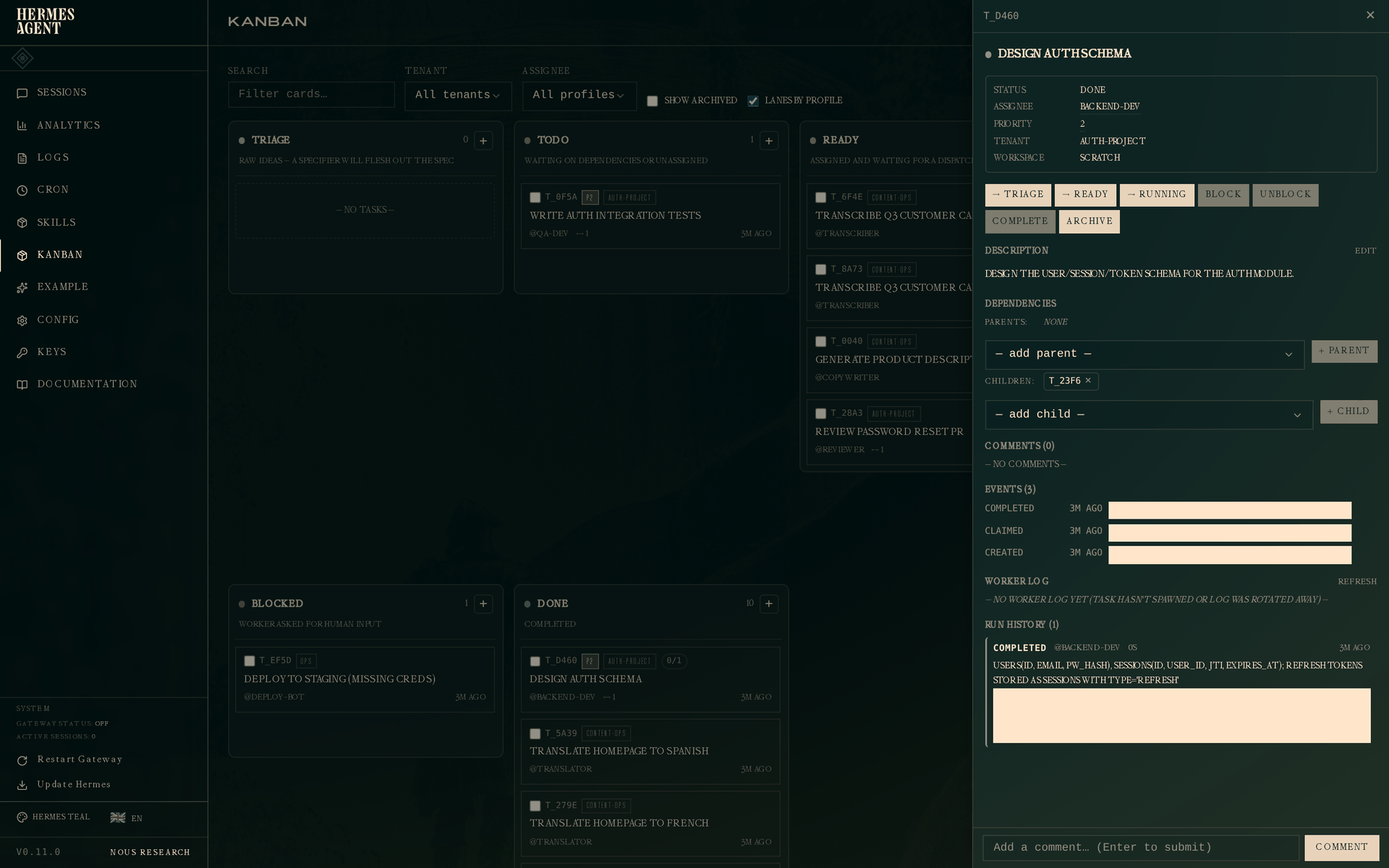
Hermes Kanban 把这件事拆成三个带父子关系的任务。父任务完成后,子任务会从 Todo 自动进入 Ready;任务被 claim 后进入 In progress;完成时用 summary 和 metadata 留下交接信息,比如 schema 设计、验收标准、测试结果。
TODO 记录了“做什么”,Kanban 还能记录“什么现在可以做、上一步留下了什么”。
右侧面板显示了一切:
Story 2:并行农场
你有三个 worker:一个负责翻译,一个负责转录,一个负责写商品文案。与此同时,任务池里有一堆彼此独立的任务:把首页翻译成不同语言,转录几通客户电话,为多个 SKU 生成商品描述。
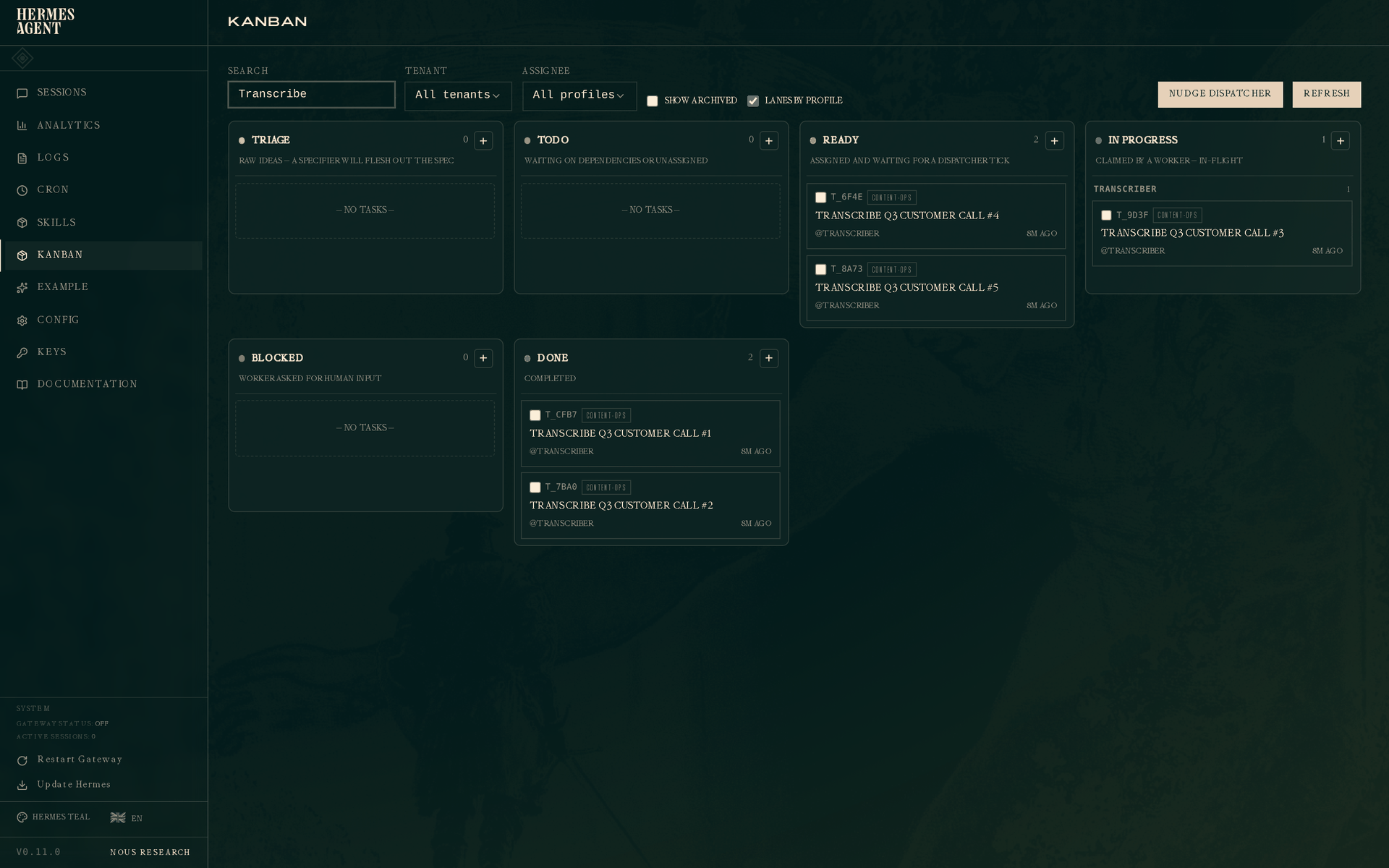
如果只靠 TODO,你能看到“还有哪些事没做”,但很难看到整个队列是怎么被消化的:哪个 worker 正在跑,哪个 worker 已经完成了两条,哪些任务还在 Ready 等下一次 dispatcher tick。
Hermes Kanban 在这里解决的是并行调度和可见性问题。每个任务都有 assignee,dispatcher 会从对应的任务池里 claim Ready 任务;看板的 In progress 列默认按 profile 分 lane,所以你不用在一堆混杂任务里扫描,就能看到 translator、transcriber、copywriter 各自正在做什么。
这就是多 Agent 并行协作和普通 TODO 的差别:TODO 只是一张待办清单,Kanban 是一个能持续分发任务、展示队列进度、沉淀每次 run 的调度系统。
看板UI可以查看并行的任务:
Story 3:角色流水线与重试
再看一个 password reset 功能:PM 先写规格,engineer 根据规格实现,reviewer 再做评审。
这不是“谁有空谁上”的任务列表,而是一条带角色的流水线。PM 完成规格时,会把 acceptance criteria 写进 metadata;engineer 开始实现时,可以从父任务最近一次 completed run 里拿到这些上下文;reviewer 评审时,也能看到 engineer 留下的 summary 和 metadata。
如果 reviewer 发现问题,比如缺少速率限制,任务可以被 block,写明原因;修复后再 unblock,重新进入 Ready,由 engineer 再次 claim。这样同一个实现任务会留下两次 run:第一次 blocked,第二次 completed。
重点不是“评审发现了问题”,而是评审意见、修复过程和最终结果被串在同一条 run history 里,后续 Agent 不需要从聊天记录里捞上下文。
Story 4:断路器与崩溃恢复
恢复能力里有两个很典型的场景。
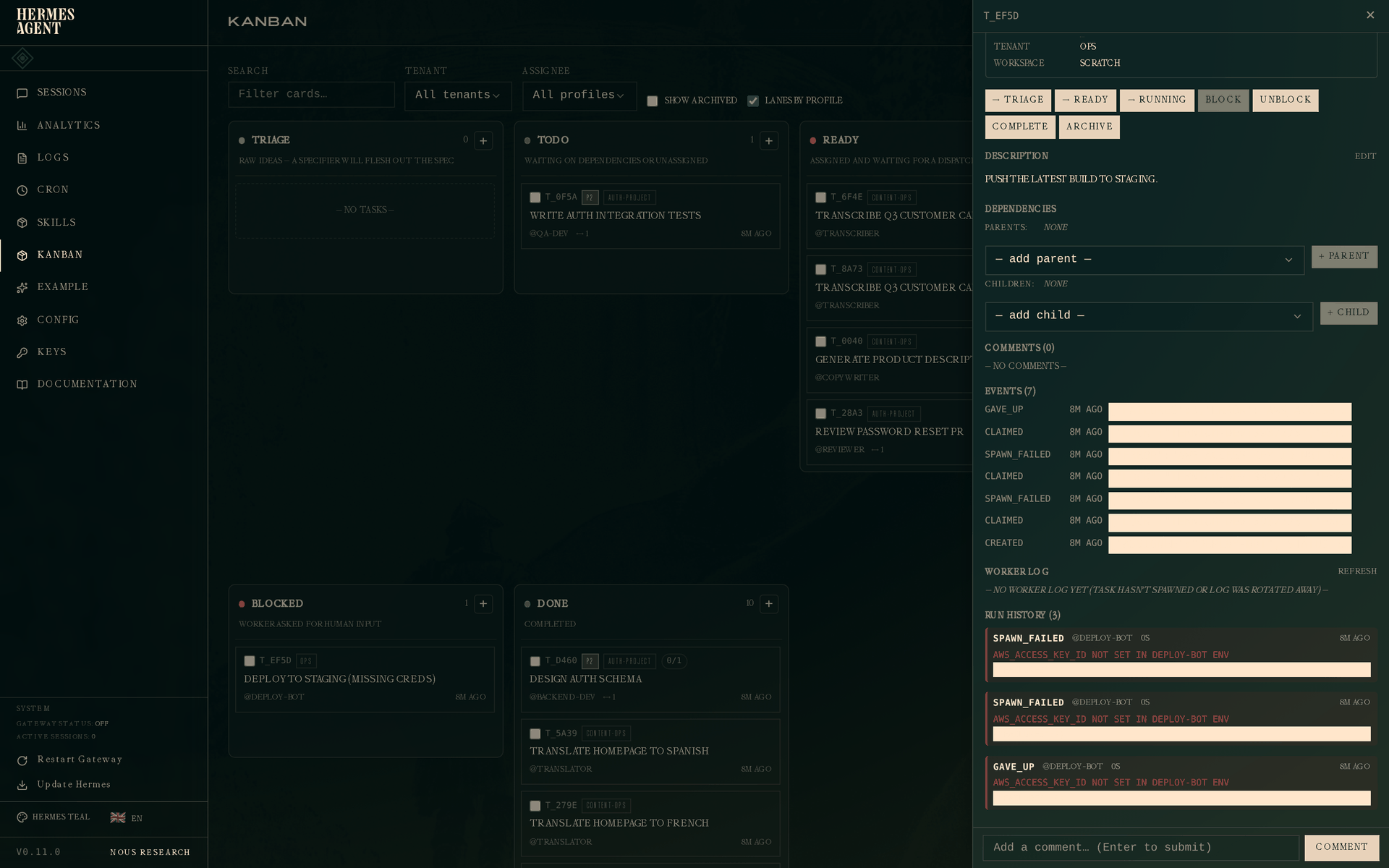
第一个是断路器。比如 deployment 任务缺少 AWS 凭证,worker 连续启动失败。普通 TODO 只会让你看到“还没完成”,但看不到系统已经失败过几次、为什么失败。Hermes Kanban 会把这些失败记到 run 里,达到 failure limit 后把任务放进 Blocked,error 字段里保留失败原因。
第二个是崩溃恢复。比如 migration 任务已经被 worker claim,但跑到一半 OOM 崩溃了。dispatcher 会发现 claim 对应的进程已经不存在,释放 claim,把任务重新放回 Ready,让后续 worker 接手。
这不是效率问题,是可靠性问题。一个系统如果不能回答“为什么失败、现在由谁接手、还能不能继续”,就不可能真正做到“可恢复”。
查看运行错误:
 )
)
一个最小例子
如果只看最小用法,可以从 auth 功能开始:先设计 schema,再实现 API,最后补集成测试。关键点是用 --parent 表达依赖,用 complete 写入交接信息。
1 | hermes kanban init |
创建完之后,只有 SCHEMA 会进入 Ready,API 和测试任务会先停在 Todo,等待父任务完成。schema 做完后,用 complete 留下交接信息:
1 | hermes kanban claim $SCHEMA |
SCHEMA 进入 Done 后,依赖引擎会自动把 API 推到 Ready。后面的 API worker 不只是看到“schema 完成了”,还能读到父任务最近一次 completed run 的 summary 和 metadata。
从 TODO 到 Kanban
这四个故事指向同一个问题:当多个 Agent 协作时,任务状态只是一个维度,真正关键的是整条协作链路能不能连续。
Hermes Kanban 围绕这条链路提供了三件事:
- 可观察:每个任务都有状态,每次执行都有 run history,不需要猜“做到哪了”。
- 可恢复:任务失败、阻塞、worker 崩溃后,系统仍然能保留 outcome、error、summary、metadata 等运行痕迹。
- 可交接:上游任务完成时留下 summary 和 metadata,下游 Agent 可以从父任务最近一次 completed run 里接收结构化上下文。
这不是把看板做得更好看,而是把协作从“标记状态”升级为“传递上下文”。
过去我们用 TODO 管自己,是因为上下文在自己脑子里。
后来我们用 Jira、Trello、Linear 管团队,是因为上下文需要在人和人之间流动。
现在我们开始用多个 Agent 组成工作流,上下文又多了一层复杂性:它不仅要被人理解,也要被机器稳定消费。
所以,当 AI 工作流从单 Agent 变成多 Agent,你需要的不是更长的 TODO 列表,而是一块真正能支撑协作的看板。
本文初稿是使用 虾塘 https://clawpond.org 编写的。使用 claude、codex、gemini、opencode 等智能体协作讨论初稿。
使用虾塘,可以让智能体更好的协作。
 )
)
