
原文: A Short Survey of PProf Visualization Tools by Jordan Crabtree。
调试CPU相关的问题经常会涉及关于趋势的微妙问题。堆使用的峰值是否逐渐的增长? routine在什么地方被调用,调用的频度如何?
一图胜千言。
一张图片就可以提供很多有用的上下文信息,否则如果用语言解释起来累的半死。将pprof可视化显示可以将有用的CPU统计数据与整个时间的上下文关联起来。
原文: A Short Survey of PProf Visualization Tools by Jordan Crabtree。
调试CPU相关的问题经常会涉及关于趋势的微妙问题。堆使用的峰值是否逐渐的增长? routine在什么地方被调用,调用的频度如何?
一图胜千言。
一张图片就可以提供很多有用的上下文信息,否则如果用语言解释起来累的半死。将pprof可视化显示可以将有用的CPU统计数据与整个时间的上下文关联起来。
原文: HTTP Response Snippets for Go by Alex Edwards.
受 Rails layouts and rendering启发, 我觉得写一个关于Go HTTP Response的代码片段集合是一个不错的主意, 它可以用来说明Go web应用程序中通用的HTTP Response的使用。
在阅读本文之前,我先推荐你阅读官方的 Effective Go文档,或者是中文翻译版: 高效Go编程,它提供了很多编写标准而高效的Go代码指导,本文不会再重复介绍这些内容。
最地道的Go代码就是Go的标准库的代码,你有空的时候可以多看看Google的工程师是如何实现的。
本文仅作为一个参考,如果你有好的建议和意见,欢迎添加评论。

官方英文版本: A Guide To The Kafka Protocol
中文翻译: watchword 翻译于2016年1月31日,修改于6月17日,基于原文2016年5月5日修改版本(v.106)修改翻译: Kafka通讯协议指南
smallnest 基于原文 Jan 20, 2017版本修改。
如果想深入了解Kafka的通讯协议的话,这篇文章不可不读。感谢 watchword 将原文翻译成了中文,我基于最新版进行了修订,修订和完善翻译中的错误。
国内的Go开发已然蔚然成风,但是Go开发者比较痛苦的是,golang.org网站以及其它的一些相关的开发网站被GFW屏蔽了。下载Go开发包海容易些,国内有一些镜像站点,或者通过一些代理也能访问,但是下载一些开发库的时候,这些库可能直接或者间接引用了 `golang.org/x/...`等依赖库, 通过go get命令确没有办法下载下来。
我原先在Comcast,这是一家外企,在国内有vpn可以直接访问这些网站,所以以前没有觉得go get是一个问题,看到大家被GFW弄的焦头烂额的时候也没觉得是一件大事情,现在换到国内的互联网企业,切切实实的感觉到GFW的威力。首先是google.com, golang.org等网站被屏蔽掉了,其次 go get 一些库如golangorg/x/net失败。
在编程语言深入讨论中,经常被大家提起也是争论最多的讨论之一就是按值(by value)还是按引用传递(by reference, by pointer),你可以在C/C++或者Java的社区经常看到这样的讨论,也会看到很多这样的面试题。
对于Go语言,严格意义上来讲,只有一种传递,也就是按值传递(by value)。当一个变量当作参数传递的时候,会创建一个变量的副本,然后传递给函数或者方法,你可以看到这个副本的地址和变量的地址是不一样的。
当变量当做指针被传递的时候,一个新的指针被创建,它指向变量指向的同样的内存地址,所以你可以将这个指针看成原始变量指针的副本。当这样理解的时候,我们就可以理解成Go总是创建一个副本按值转递,只不过这个副本有时候是变量的副本,有时候是变量指针的副本。
这是Go语言中你理解后续问题的基础。
但是Go语言的情况比较复杂,我们什么时候选择 T 作为参数类型,什么时候选择 *T作为参数类型? []T是传递的指针还是值?选择[]T还是[]*T? 哪些类型复制和传递的时候会创建副本?什么情况下会发生副本创建?
本文将详细介绍Go语言的变量的副本创建还是变量指针的副本创建的case以及各种类型在这些case的情况。
gofsm是一个简单、小巧而又特色的有限状态机(FSM)。
github已经有了很多状态机的实现,比如文末列出的一些,还为什么要再发明轮子呢?
原因在于这些状态机有一个特点,就是一个状态机维护一个对象的状态,这样一个状态机就和一个具体的图像实例关联在一起,在有些情况下,这没有什么问题,而且是很好的设计,而且比较符合状态机的定义。但是在有些情况下,当我们需要维护成千上百个对象的时候,需要创建成千上百个状态机对象,这其实是很大的浪费,因为在大部分情况下,对象本身自己会维护/保持自己当前的状态,我们只需把对象当前的状态传递给一个共用的状态机就可以了,也就是gofsm本身是“stateless”,本身它包维护一个或者多个对象的状态,所有需要的输入由调用者输入,它只负责状态的转换的逻辑,所以它的实现非常的简洁实用,这是创建gofsm的一个目的。
第二个原因它提供了Moore和Mealy两种状态机的统一接口,并且提供了UML状态机风格的Action处理,以程序员更熟悉的方式处理状态的改变。
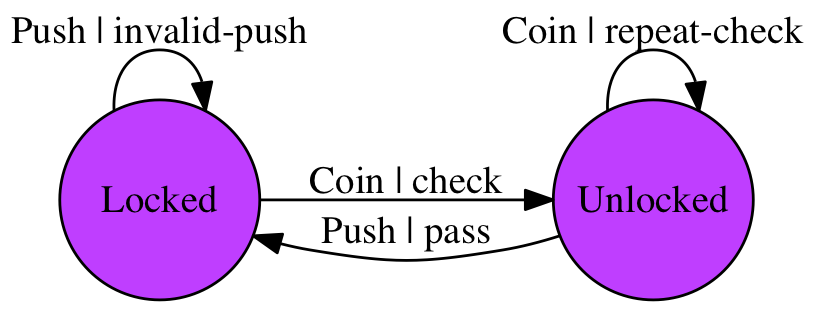
第三个原因,当我们谈论起状态机的时候,我们总会画一个状态转换图,大家可以根据这这张图进行讨论、设计、实现和验证状态的迁移。但是对于代码来说,实现真的和你的设计是一致的吗,你怎么保证?gofsm提供了一个简单的方法,那就是它可以输出图片或者pdf文件,你可以利用输出的状态机图和你的设计进行比较,看看实现和设计是否一致。
Stack trace是指堆栈回溯信息,在当前时间,以当前方法的执行点开始,回溯调用它的方法的方法的执行点,然后继续回溯,这样就可以跟踪整个方法的调用,大家比较熟悉的是JDK所带的jstack工具,可以把Java的所有线程的stack trace都打印出来。
它有什么用呢?用处非常的大,当应用出现一些状况的时候,比如某个模块不执行, 锁竞争、CPU占用非常高等问题, 又没有足够的log信息可以分析,那么可以查看stack trace信息,看看线程都被阻塞或者运行在那些代码上,然后定位问题所在。
对于Go开发的程序,有没有类似jstack这样的利器呢,目前我还没有看到,但是我们可以通过其它途径也很方便的输出goroutine的stack trace信息。
本文介绍了几种方法,尤其是最后介绍的方法比较有用。
Github 和 Gitlab 提供了一些可能有些人还不了解的语法,可以自动为文字添建连接,关联相关的一些对象,以及执行相应的操作。本文记录了这些小技巧,可以在需要的时候查询。
