
观其设计知其人
A MAN is KNOWN by the DESIGN he keeps
原文:Most Useful Software Architecture Patterns by Shadman Jamil
观其设计知其人
A MAN is KNOWN by the DESIGN he keeps
原文:Most Useful Software Architecture Patterns by Shadman Jamil

不管我们是不是有身份的人,我们一定是有身份证的人,身份证上面的号码就是我们的ID,理论上这个ID是全国唯一的,而且通过这个号码,我们还可以得到一些个人信息,比如前两位可以确定我们第一次申请身份证的时候所在的省份、接下来的四位可以确定我们所在的区县,然后还可以知道我们出生的年月以及性别。
在我们的计算机应用中,也处处存在的ID, 比如订单编号、商品ID、微博ID、微信消息ID、书的ISDN号、商品条码等等。通过ID,可以迅速定位到对象实体、为对象之间建立关联、跟踪对象在不同服务之间的流转等等。
有的ID是无意义的唯一的标识,有的ID还能提供额外的信息,比如时间和机房信息等等。为了确保唯一性,有的ID使用很长的字节数,比如256个字节,有的通过递增的long类型,只需要8个字节来表示。考虑到存储、信息包含量、性能、安全等因素,一个好的ID的设计至关重要。
介绍ID生成和分布式的方案的文章已经非常非常多了,比如文末中的参考资料中的文章,所以我在本文中简洁的汇总各个方案的优缺点,然后介绍一个分布式的ID生成器项目rpcxio/did,它可以实现单节点百万级的ID生成。
随着公司规模的扩大,以及业务量的激增,单体应用逐步演化为服务/微服务的架构模式, 服务之间的调用大多采用rpc的方式调用,或者消息队列的方式进行解耦。几乎每个大厂都会创建自己的rpc框架,或者基于知名的rpc框架进行改造。
目前, rpc框架主要沿着两条路线发展,一个是目标为了跨语言,服务端可以用不同的语言实现,客户端也可以用不同的语言实现,不同的语言实现的客户端和服务器端可以互相调用。很显然,要支持不同的语言,需要基于那种语言实现相同协议的框架,并且协议设计应该也是跨语言的,其中比较典型的是 grpc,基于同一个IDL,可以生成不同语言的代码,并且语言的支持也非常的多。
另一个rpc框架发展的目标是支持服务治理,主要的精力放在服务发现、路由、容错处理等方面,主要围绕一个语言开发,可能也有一些第三方曲折的实现服务的调用和服务的实现,这其中的代表,也是比较早的开源的框架就是阿里巴巴的dubbo。
有些rpc框架协议的涉及一开始就没有考虑的跨语言,其中使用了语言的一些特有的属性,比如Java的ObjectInputStream/ObjectOutputStream, Golang的Gob等,有些在协议的设计上就考虑了通用性, 使用JSON或者Protobuffer作为数据序列化。
有些框架是基于TCP的二进制流的数据传输,有些基于http的request/response模型进行请求,也有基于http2的流式传输,更有一些支持可信赖的UDP进行数据传入,比如quic、kcp等。
有些提供了生态圈的一些框架,比如gateway、agent等,有些restful风格的rpc框架天然支持API gateway进行负载均衡。
有些已经得到了大厂的广泛应用,有的大厂内部得到了大量应用,但目前还没有广泛的推开来。
选择一个rpc框架会基于多方面的考虑: 框架特性、性能、成熟度、技术支持、社区活跃度等多个方面,本文只比较各个流行框架的benchmark,基于几个固定的场景提供benchmark数据支持。
原文: Designing a Microservices Architecture for Failure
翻译: 设计一个容错的微服务架构 by Jason Geng
微服务架构使得可以通过明确定义的服务边界来隔离故障。但是像在每个分布式系统中一样,发生网络、硬件、应用级别的错误都是很常见的。由于服务依赖关系,任何组件可能暂时无法提供服务。为了尽量减少部分中断的影响,我们需要构建容错服务,来优雅地处理这些中断的响应结果。
本文介绍了基于RisingStack 的 Node.js 咨询和开发经验构建和操作高可用性微服务系统的最常见技术和架构模式。
如果你不熟悉本文中的模式,那并不一定意味着你做错了。建立可靠的系统总是会带来额外的成本。
TechEmpower最近发布了他们的第13轮的web框架的性能测试,得到了一些有价值的测试结果。
由于年初前一轮的测试遭遇到了硬件的瓶颈,微软 Azure 和 ServerCentral 分别提供了云主机和物理主机环境,所以第13轮的测试是在新的测试环境中进行的,所以你把这轮的测试结果和以前的测试进行比较的话可能不太合适。
一致性哈希最早由 MIT的 Karger 提出,在发表于1997年的论文 Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web, Karger et al 和合作者们提出了一致性哈希的概念(consistent hash),用来解决分布式Cache的问题。这篇论文中提出在动态变化的Cache环境中,哈希算法应该满足的4个适应条件::Balance(均衡)、Monotonicity(单调性)、Spread(分散性)、Load(负载)。
在分布式缓存系统中使用一致性哈希算法时,某个节点的添加和移除不会重新分配全部的缓存,而只会影响小部分的缓存系统,如果均衡性做的好的话,当添加一个节点时,会均匀地从其它节点移一部分缓存到新的节点上;当删除一个节点的时候,这个节点上的缓存会均匀地分配到其它活着的节点上。
一致性哈希缓存还被扩展到分布式存储系统上。数据被分成一组Shard,每个Shard由一个节点管理,当需要扩容时,我们可以添加新的节点,然后将其它Shard的一部分数据移动到这个节点上。比如我们有10个Shard的分布式存储系统,当前存储了120个数据,每个Shard存储了12个数据。当扩容成12个Shard时,我们从每个Shard上拿走2个数据,存入到新的两个Shard上,这样每个Shard都存储了10个数据,而整个过程中我们只移动了20/120=1/6的数据。
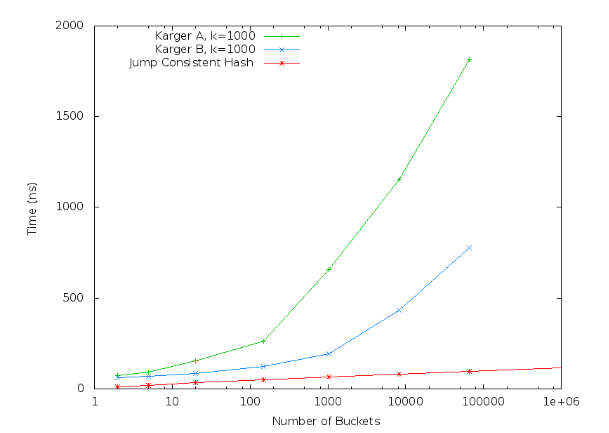
Karger 一致性哈希算法将每个节点(bucket)关联一个圆环上的一些随机点,对于一个键值,将其映射到圆环中的一个点上,然后按照顺时针方向找到第一个关联bucket的点,将值放入到这个bucke中。因此你需要存储一组bucket和它们的关联点,当bucket以及每个bucket的关联点很多的时候,你就需要多一点的内存来记录它。这个你经常在网上看到的介绍一致性哈希的算法(有些文章将节点均匀地分布在环上,比如节点1节点2节点3节点4节点1节点2节点3节点4……, 这是不对的,在这种情况下节点2挂掉后它上面的缓存全部转移给节点3了)。
其它的一致性算法还有Rendezvous hashing, 计算一个key应该放入到哪个bucket时,它使用哈希函数h(key,bucket)计算每个候选bucket的值,然后返回值最大的bucket。buckets比较多的时候耗时也较长,有人也提出了一些改进的方法,比如将bucket组织成tree的结构,但是在reblance的时候花费时间又长了。
Java程序员熟悉的Memcached的客户端Spymemcached、Xmemcached以及Folsom都提供了Ketama算法。其实Ketama算法最早于2007年用c 实现(libketama),很多其它语言也实现了相同的算法,它是基于Karger 一致性哈希算法实现:
以上两种算法可以处理节点增加和移除的情况。对于分布式存储系统,当一个节点失效时,我们并不期望它被移除,而是使用备份节点替换它,或者将它恢复起来,因为我们不期望丢掉它上面的数据。对于这种情况(节点可以扩容,但是不会移除节点),Google的 John Lamping, Eric Veach提供一个高效的几乎不占用持久内存的算法: Jump Consistent Hash。
原文地址:各大互联网公司架构演进之路汇总 by HollisChuang
请转载时务必保留文章的上述原始出处。
